the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 02 Oct 2020
| 02 Oct 2020
Canal blocking optimization in restoration of drained peatlands
Ari Laurén
Marjo Palviainen
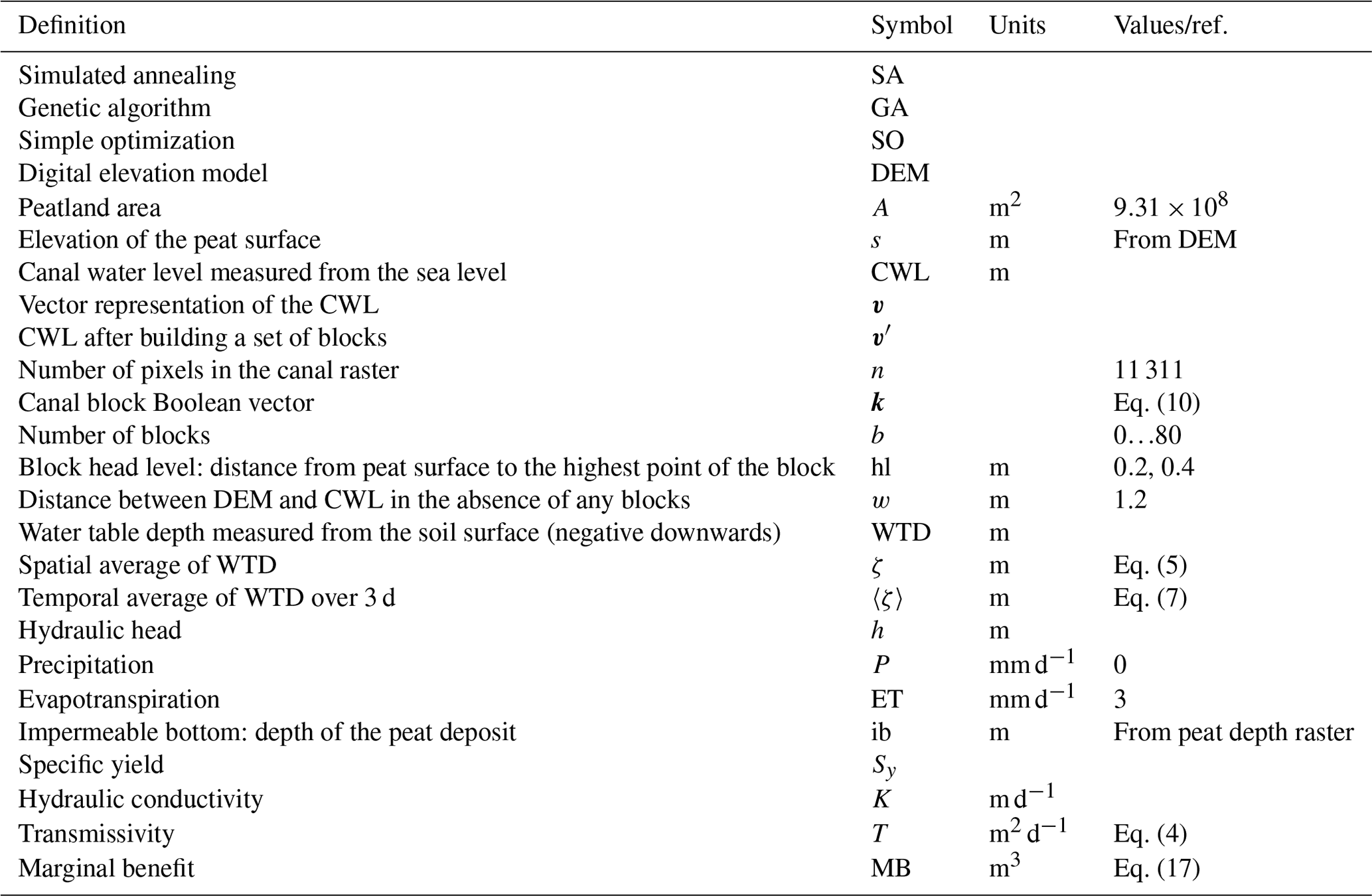
Kersti Haahti
Arif Budiman
Imam Basuki
Michael Netzer
Hannu Hökkä
Drained peatlands are one of the main sources of carbon dioxide (CO2) emissions globally. Emission reduction and, more generally, ecosystem restoration can be enhanced by raising the water table using canal or drain blocks. When restoring large areas, the number of blocks becomes limited by the available resources, which raises the following question: in which exact positions should a given number of blocks be placed in order to maximize the water table rise throughout the area? There is neither a simple nor an analytic answer. The water table response is a complex phenomenon that depends on several factors, such as the topology of the canal network, site topography, peat hydraulic properties, vegetation characteristics and meteorological conditions. We developed a new method to position the canal blocks based on the combination of a hydrological model and heuristic optimization algorithms. We simulated 3 d dry downs from a water saturated initial state for different block positions using the Boussinesq equation, and the block configurations maximizing water table rise were searched for by means of genetic algorithm and simulated annealing. We applied this approach to a large drained peatland area (931 km2) in Sumatra, Indonesia. Our solution consistently outperformed traditional block locating methods, indicating that drained peatland restoration can be made more effective at the same cost by selecting the positions of the blocks using the presented scheme.
- Article
(3359 KB) - Full-text XML
- BibTeX
- EndNote





Peatlands occupy around 3 % of global land area but hold up to one-third (630 Pg) of all carbon (C) held in active terrestrial pools (Page et al., 2011; Page and Baird, 2016; Xu et al., 2018; Le Quéré et al., 2018; Nichols and Peteet, 2019). In pristine conditions, peatlands typically act as C sinks since the input of dead organic matter is usually greater than the biological decomposition of peat and other organic residues (Reddy and DaLaune, 2008). However, drainage may turn peatlands into C sources (Minkkinen and Laine, 1998; Hooijer et al., 2010; Ojanen et al., 2010; Jauhiainen et al., 2012), and as a consequence drained peatlands are one of the main sources of CO2 emissions globally. Drainage removes excess water from peat and enhances site productivity, which is favorable for agriculture and forest production (Päivänen and Hånell, 2012; Evans et al., 2019). Even though drainage-based bioproduction can be economically viable, it has severe environmental drawbacks: it increases CO2 emissions (Ojanen et al., 2010; Jauhiainen et al., 2012), the rate of peat subsidence (Couwenberg et al., 2010; Hooijer et al., 2010; Carlson et al., 2015; Evans et al., 2019), nutrient export to water courses (Nieminen et al., 2017) and fire risk in peatlands (Usup et al., 2004; Wösten et al., 2008; Page and Hooijer, 2016). CO2 emissions have been particularly severe in managed tropical peatlands where the annual CO2 emission has been as high as 70–90 Mg ha−1 (Hooijer et al., 2010; Jauhiainen et al., 2012). C emissions from tropical peatlands in Malaysia and Indonesia in 2015 corresponded to 1.6 % of global fossil fuel emissions (Miettinen et al., 2017). According to Hooijer et al. (2010), the CO2 emissions from drained peatlands in Indonesia range from 290 to 700 Tg yr−1.
Water table depth (WTD) has been found to be the key variable controlling CO2 emissions from decomposition in tropical peatlands (Hooijer et al., 2010; Jauhiainen et al., 2012; Carlson et al., 2015; Evans et al., 2019). It has been estimated that raising the WTD from −80 to −40 cm would decrease CO2 emissions on average by 50 Mg ha−1 yr−1 (Jauhiainen et al., 2012) and the rate of peat subsidence by 1.7 cm yr−1 (Evans et al., 2019). The reason behind the beneficial effects is that increasing water content in peat limits oxygen (O2) supply for the decomposer organisms and consequently slows down the rate of aerobic decomposition (Reddy and DaLaune, 2008). Therefore, raising the WTD is a powerful tool for peatland restoration, the aim of which is to establish a self-sustaining peat ecosystem that accumulates C.
Studies of canal and ditch blocking in temperate peatlands describe how WTD rises for peatland restoration have been commonly carried out using drain or canal blocks constructed from surrounding peat material, mineral soil or artificial materials (Ritzema et al., 2014; Armstrong et al., 2009; Parry et al., 2014). As discussed by Parry et al. (2014), the WTD response depends on site topography (Holden et al., 2006), block position (Holden, 2005), drain spacing and the hydraulic characteristics of peat (Dunn and Mackay, 1996). When restoring large peatland areas, the number of blocks becomes easily limited by available financial resources. This is especially important in tropical peatlands, where the canals are typically large, requiring large structures that increase the cost of a single block (Armstrong et al., 2009; Ritzema et al., 2014). Working with limited resources raises a natural question: in which exact positions should a given number of blocks be placed in order to maximize the amount of rewetted peat and consequently to minimize CO2 emissions and the rate of subsidence?
To the best of our knowledge there is no systematic approach to support finding optimal block positions (Armstrong et al., 2009; Ritzema et al., 2014). Experimentally testing different block positions is impractical and inefficient. Process-based hydrological models, on the other hand, provide a useful tool to reveal changes in the WTD induced by different drainage setups (Dunn and Mackay, 1996). However, for large peatland areas and complex canal networks, process-based models on their own are not sufficient to solve the best block positions because the number of possible positions becomes subject to a combinatorial explosion. To illustrate this, let us consider a setup with b blocks having n possible locations. The number of ways in which the blocks could be arranged equals . For the case studied in this paper, the number of possible locations was n=11 311, and b was chosen to range from 0 to 80. To get a grasp of the number of possible combinations, let us point out that there are ways to place 40 blocks. Even with powerful computers it is not feasible to find the best combination through an exhaustive search; a different strategy is required. By using global optimization methods such as genetic algorithm (GA) and simulated annealing (SA), it is possible to find approximate solutions to the problems without an exhaustive search. Choosing canal blocking positions is a combinatorial management problem for which global optimization methods are particularly suitable (Jin et al., 2016; Laurén et al., 2018; Rao, 2009).
Our objective in this work was to build a computational scheme based on a simple hydrological model coupled with an optimization algorithm that maximizes the amount of rewetted peat with a given number of canal blocks. The hydrological model uses the Boussinesq equation to compute WTD as a two-dimensional surface. Using the WTD – a proxy for the CO2 emissions – as the target variable of the optimization problem, the optimization algorithms (GA and SA) look for the positions of the blocks that minimize the emissions. This scheme was applied to a drained peatland area (931 km2) in Sumatra, Indonesia. Topographical details of the peatland areas, as well as rainfall data and physical peat properties, were employed in the simulations. The implication for different canal blocking schemes will be discussed in the context of regional greenhouse gas emissions.
2.1 Study area
The study area was located in Siak, Riau, Indonesia (Fig. 1). The area has a humid tropical climate; the mean annual temperature is 27 ∘C with very small monthly variation. The mean annual precipitation in the area is 2696 mm with the rainy season extending from October to April. The rainfall of the wettest month (November) exceeds 300 mm per month, while the driest month (July) receives 120 mm of rainfall. According to long-term weather statistics, the mean dry period between the rainfall events during the dry season is 3.2 d, and the maximum number of consecutive dry days is 20 (data from Pekanbaru airport, located in the same province as the target area, years 1994–2013). Because of the humid climate and its topography, the area is characterized by tropical peatlands; the total area is 1100 km2, of which peatlands cover 931 km2. The depth of the peat deposit ranges from 2 to 8 m, the deepest peat deposit being located in the middle of the area (see Fig. 2). Approximately 30 % of the peat area represents hemic or moderately decomposed peat, and 60 % is sapric or highly decomposed peat. The area was drained using canals about 5 to 8 m meters wide, which are also used for the transportation of wood and other products. The widest canals are captured in our dataset, but smaller field drains exist that were omitted in this study due to the coarse resolution of the rasters. The total length of the canal network is 1100 km. Typically, the canals are spaced in intervals of 500 to 1000 m.
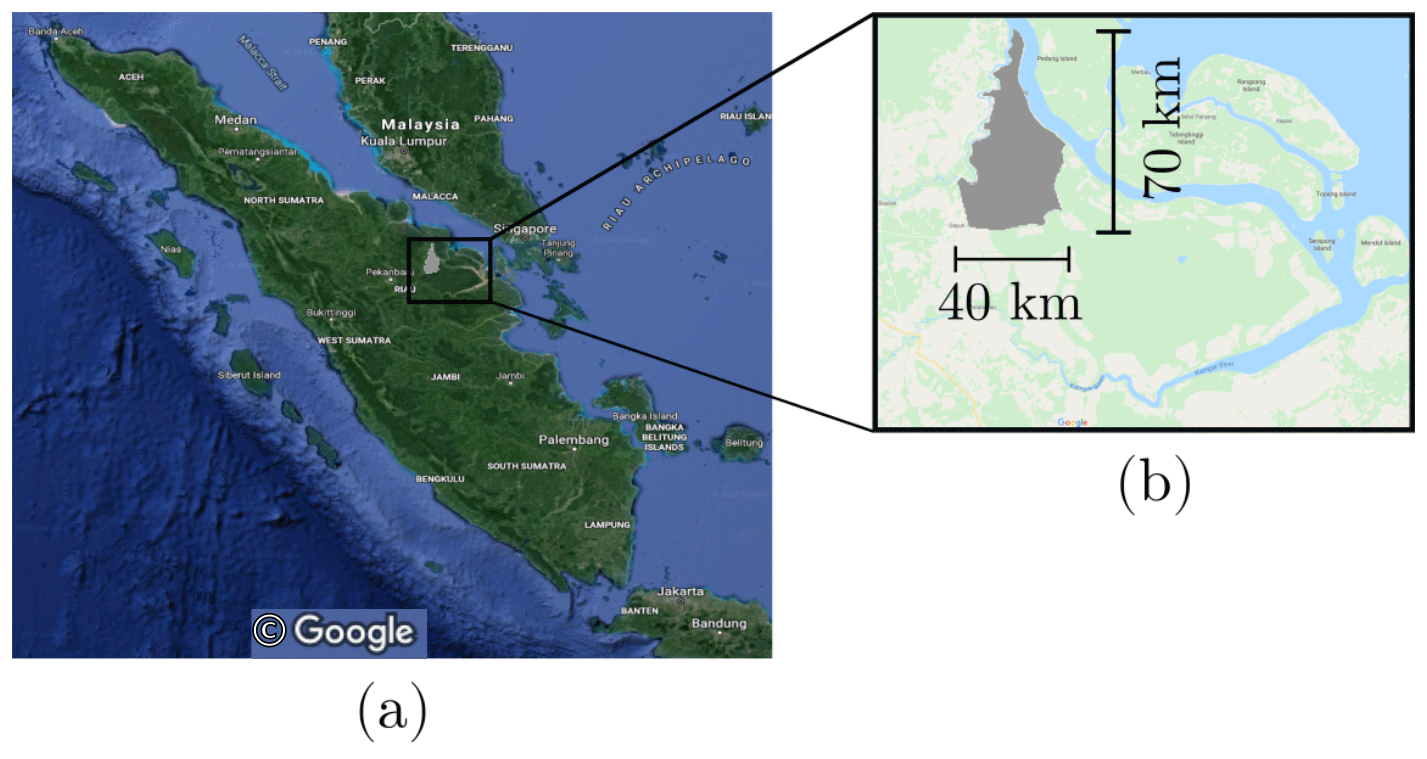
Figure 1(a) Map of Sumatra, Indonesia, with the study area shown in gray. (b) Detailed view of the study area. Map data: © Google, Maxar Technologies.
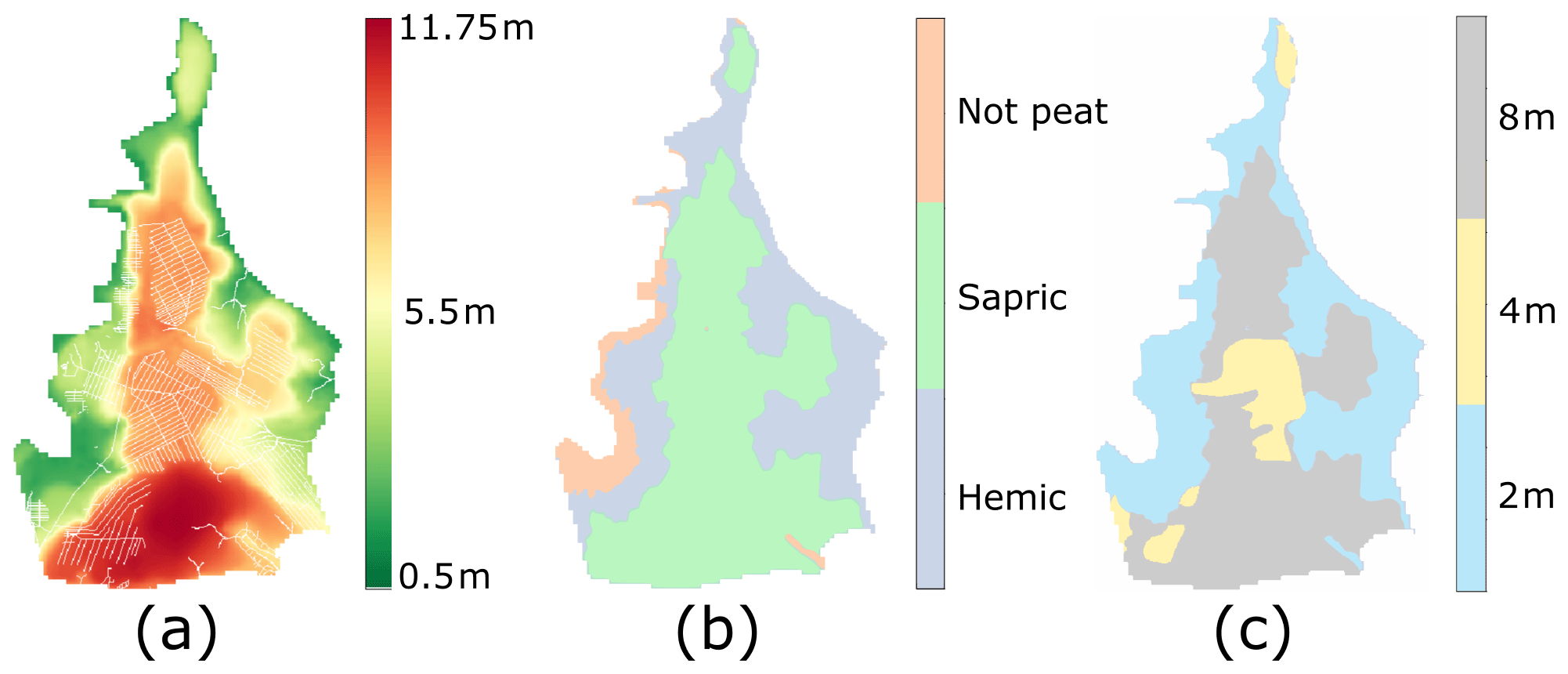
Figure 2(a) DEM (colored) with the canal network superposed (white), (b) peat types and (c) peat depth. The resolution of the rasters is 100 m×100 m.
For our computations we used the 100 m×100 m resolution raster data shown in Fig. 2, which together describe the surface elevation (DEM) (Vernimmen et al., 2019), the canal location, and the peat depth and type. The DEM was preprocessed using the fill sinks algorithm in QGIS 3.4 in order to identify and fill unwanted surface depressions. The peat type influences the peat physical properties (specific yield, Sy, and transmissivity, T) of the hydrological simulation, and the peat thickness of Fig. 2c defines ib, which is the depth of the impermeable bottom below the peat surface.
2.2 Computational scheme
The computation consists of the following modules: the canal water level subroutine, the hydrological model and an optimization algorithm. Figure 3 describes a single iteration in the optimization process. The canal water level subroutine computes the canal water level (CWL) that would result from building canal blocks in some given positions. The CWL is passed to the peat hydrological model, which solves the WTD for the whole area. WTD is closely related to the target variable of the optimization problem, 〈ζ〉, defined in Sect. 2.2.2. The optimization algorithm evaluates the target variable and decides what canal block configuration will be studied next. This starts a new iteration. We made use of two optimization algorithms: genetic algorithm (GA) and simulated annealing (SA). We also tested an alternative, simpler optimization approach (SO) that maximizes the change in CWL instead (see Eq. 13) and bypasses the hydrological simulation completely. See Table 1 for definitions of symbols used.

Figure 3Schematic representation of a single iteration of the computation showing the most relevant input and output and the interaction between the modules. The numbers in parentheses refer to the corresponding section in the main text. DEM stands for digital elevation model. The optimization algorithm proposes a particular position for the canal blocks, k. Then, the canal water level subroutine computes the canal water level (CWL) resulting from that block placement, v′. This information is passed on to the peat hydrological model, which solves for the WTD with v′ as boundary conditions and computes the resulting target variable, which is the average WTD over 3 dry days, 〈ζ〉, defined in Sect. 2.2.2. The optimization algorithm evaluates the performance and proposes a new k according to some rules specific to each algorithm. When using the alternative simple optimization strategy (SO), the CWL change, which depends only on v and v′ (see Eq. 13), is used as a target variable. This corresponds to the shortcut shown by the dashed arrows.
2.2.1 Canal water level subroutine
This subroutine calculates the CWL (v′) after building a set of blocks at positions k based on the original CWL (v). In the absence of any blocks, the CWL is assumed to be at a fixed distance, w, below the elevation derived from the DEM:
Here i ranges over the set of pixels of the DEM that form the canal network, henceforth called canal raster. In our simulations, the value of w was determined by direct observation on site and was set to w=1.2 m.
In order to compute how v would be affected by building a block in any pixel of the canal raster, information about the topology of the canal network is needed. In particular, it is necessary to know the direction of water flow to determine which adjacent pixels are upstream (and therefore potentially affected by the block). The direction of the water flow was inferred from the canal raster following two simple rules. For any two pixels in the canal network raster, we say that pixel B is a contiguous upstream pixel of A if and only if the following are satisfied:
-
A and B are adjacent to each other (diagonal adjacency is also allowed);
-
the water level of A is lower than that of B, i.e., vA<vB.
When a block is built in a given pixel of the canal raster, its water level and the water level of upstream pixels rise up to match the height of the block with no delay. In what follows, instead of using the block height as a variable, we use the block head level (hl). The block head level is defined as the distance from the DEM elevation to the highest point of the block (Fig. 4).
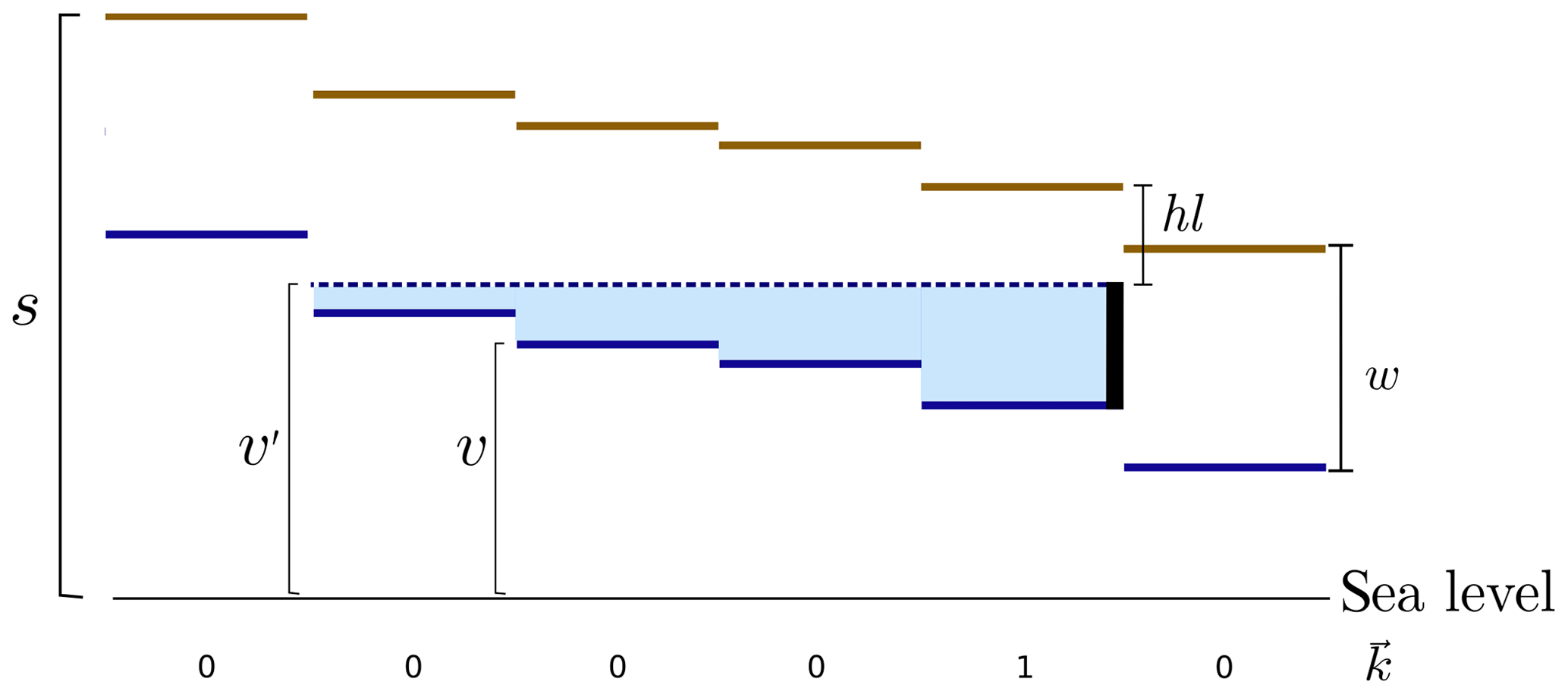
Figure 4Side view of a canal. The solid blue and the brown horizontal lines represent the initial CWL, v, and the height of the peat surface, s, respectively. The parameter w denotes the distance from the peat surface to the CWL. Each pixel is represented by one line segment. The vertical black line represents the block, and the dotted blue line represents the CWL after the block has been placed, v′. The shaded blue area represents the change in the CWL due to the block. The value of the vector k is ki=1 if there is a block in pixel i and otherwise ki=0.
A detailed description of the algorithm used to implement these rules and compute v′ is presented in Appendix A. The general response of the CWL to a block is schematically shown in Fig. 4.
2.2.2 Peat hydrological model
The peat hydrological model simulates the two-dimensional WTD surface for a given configuration of the blocks. From there it computes the target variable of the optimization algorithm, 〈ζ〉, defined in Eq. (7). The WTD was solved using the Boussinesq equation, a quasi-three-dimensional groundwater flow partial differential equation (PDE) which is computationally much more efficient than solving the full three-dimensional problem and is a standard groundwater modeling equation for domains much wider than they are thick (Bear, 1979; Connorton, 1985; Skaggs, 1980; Koivusalo et al., 2000; Cobb et al., 2017):
where Sy is the specific yield, T is the transmissivity (m2 d−1), h is the hydraulic head (m) and P−ET is the difference between the precipitation and evapotranspiration (m d−1). The WTD is related to h as follows:
where s is the peat surface in meters above sea level. Equation (2) was numerically solved on a horizontal grid with a daily time step using a finite volume solver (Guyer et al., 2009). Since Eq. (2) is a nonlinear PDE, its solution at each time step was found iteratively so as to ensure numerical stability. The number of these internal iterations was set to three, which was regarded as a good compromise between accuracy and efficiency. The numerical scheme was fully implicit in time for h and explicit for T(h) and Sy(h). The exterior faces of the grid were open water bodies, and Dirichlet – constant head – boundary conditions were applied on them. The value of h at the canal pixels was forced to be equal to v′ by adding a source term large enough to completely dominate the corresponding term of the discretized equation (Versteeg and Malalasekera, 2007).
In this setup, the transmissivity is given by
where K is the saturated hydraulic conductivity (m d−1) and ib is the depth of the impermeable bottom relative to the peat surface. It follows from Eq. (4) that the transmissivity is a function of both h and ib. However, since ib is directly inferred from peat depth measurements (see Fig. 2), we simplify the notation by letting . The layered structure of the peat deposit, whose hydraulic conductivity can vary by orders of magnitude along the vertical direction, z, is thus taken into account in T(h). Since published hydraulic property profiles in tropical peat deposits are scarce (Baird et al., 2017), we parameterized the model based on the following.
-
The degree of decomposition (hemic, sapric) affects the hydraulic conductivity. Hydraulic conductivity values for different decomposition stages were adopted from Wösten et al. (2008).
-
Hydraulic conductivity decreases exponentially with depth (Koivusalo et al., 2000; Cobb et al., 2017).
-
Woody peat is the dominant material in tropical peat deposits. The van Genuchten function was used to compute the volumetric water content of peat at depth z for each degree of decomposition and h. In the absence of measured tropical peat water retention characteristics, we used values from boreal woody peats with the same peat type and degree of decomposition (Päivänen, 1973). From the volumetric water content curves, the specific yield, Sy, which is the amount of water required for a differential increment in WTD elevation, was calculated.
Derived T(h) and S(h) curves for the deepest substrate (10 m) hemic peat are shown in Fig. 5d.
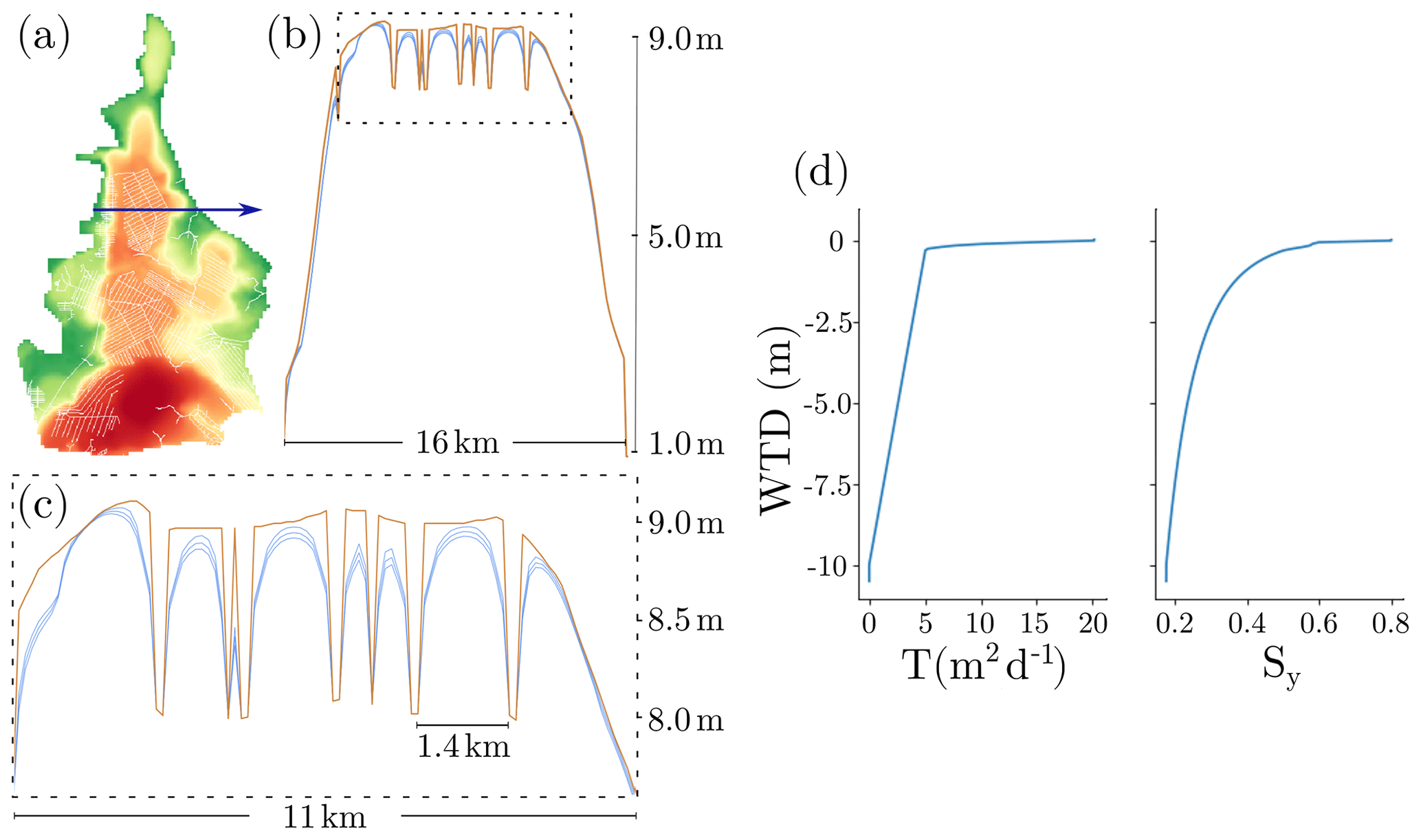
Figure 5Cross section of the simulated WTD for 3 consecutive dry days after a big rainfall event and peat hydraulic properties. (a) DEM (colored) with the canal network superposed (white) and a straight horizontal blue line indicating the location of the cross section shown in panels (b) and (c). (b) Peat surface (brown) and cross-sectional view of the WTD (blue) measured in meters above sea level. The multiple blue lines correspond to the WTD for the 3 consecutive days of dry down. Abrupt low peat surface values correspond to canals. The dashed rectangle shows the region magnified in the panel below. (c) Magnified area from the panel above. (d) Transmissivity, T(h), and specific yield, Sy(h), functions for the deepest substrate (10 m) hemic peat.
Ponding water in fully saturated profiles was neglected, and all surface water was removed from the computation, therefore assuming that the typical runoff velocity of water is greater than the infiltration velocity.
All simulations started from a fully saturated landscape, i.e., WTD=0.0 m or, equivalently, h=s, which may occur after a heavy tropical rainfall event. Thereafter, for the optimization procedure, 3 dry days without any precipitation, and , were simulated with a daily time step. The reason to adopt this particular setup is that the wet initial state acts as a system reset which, if followed by a period without precipitation, allows for a qualitative comparison with observations. The exact number of dry days was decided according to two criteria. On the one hand, the mean of consecutive rainless days during the dry season in a 20 yr time window was 3.2 d (data from Pekanbaru airport, located in the same province as the target area, years 1994–2013). On the other hand, three time steps result in a manageable computational load in the optimization process.
The spatially averaged WTD (m) at the end of each time step, l, was defined as
where the integral extends to the whole peatland area including the canals and stands for the solution of Eq. (2) at time step l. The mean WTD over d days is then given by
where the brackets 〈⋅〉 denote the temporal average. The average WTD over 3 d is specially relevant in this work, and in what follows we will denote it without subscripts:
In order to estimate the annual CO2 emissions that a given block configuration produces, the WTD for a full year was also simulated. That simulation was also initialized with fully saturated initial conditions and was made to coincide with a high rainfall event in December 2012. It was assumed that the yearly emitted amount of CO2 per hectare, (Mg ha−1 yr−1), is proportional to 〈ζ〉365, i.e.,
with coefficients (Jauhiainen et al., 2012)
The exact values of α and β are important for the CO2 emission estimation, but they are not relevant for the rest of the results produced in this work since only the relative values of are of interest in the optimization process. Instead, the crucial feature is that the annual average WTD is linearly related to the emitted amount of CO2. The whole computational scheme is therefore independent of the exact values of α and β, and they are only used at the last stage in order to report the results in units of annual emitted tons of CO2.
2.2.3 Optimization of block positions
The management question of finding the position of a given number of blocks in such a way that the amount of emitted CO2 or its proxy, 〈ζ〉, is minimized can be formally formulated as follows.
Let be the Boolean vector indicating the presence or absence of a block in each canal pixel, i.e.,
The objective function ,
maps a given block setup to 〈ζ〉, the target variable. The objective function (or, equivalently, the target variable) is to be minimized subject to the constraint that
where b is the number of blocks to be built. There is no analytic expression for f. Instead, it is a result of combining the canal blocking subroutine with the peat hydrological model. As pointed out in the Introduction, the search space is discrete and too large for exhaustive search. Moreover, it might have many local minima that are not close to the global minimum, so algorithms that only seek local solutions are not useful. Therefore, this problem is better addressed with nonlinear, global optimization algorithms.
Even global optimization algorithms are not guaranteed to find the optimal solution in a search space in which all options cannot be tested. Given that there exists no guarantee that the process will converge towards the true global minimum of f, the reliability of the optimization procedure benefits from exploring more than one optimization method. Genetic algorithm (GA) and simulated annealing (SA) are heuristic methods that can often find the global minimum in many problems and are naturally applicable for the solution of discrete optimization tasks (Rao, 2009). In this case, both algorithms start off with some random k composed of b blocks (b=0…80), for which the resulting 〈ζ〉 is computed. Then, according to some rules specific to the algorithm, another k is proposed. This process is repeated for a fixed number of iterations, the same for all numbers of blocks. Both algorithms tend to favor the configurations that result in a smaller value of the target variable, 〈ζ〉, but they also have the vital feature of avoiding getting stuck in local minima. In SA, this is achieved by allowing steps that worsen the objective function with certain probability. This probability is controlled by the sole parameter, the temperature (a term coming from metallurgy, from which the inspiration for it came), which decreases from an initial maximum value. In GA, on the other hand, the problem is circumvented by evaluating populations of individual vectors k at each iteration or generation. The fittest individuals are passed on to the next iteration according to some rules that include mixing between individuals, also known as mating, and some randomness, or mutations. The mutation and the mating probabilities are the only parameters in the genetic algorithm implementation we used.
Table 2Block locating methods and their parameters. The values of the parameters were decided empirically.
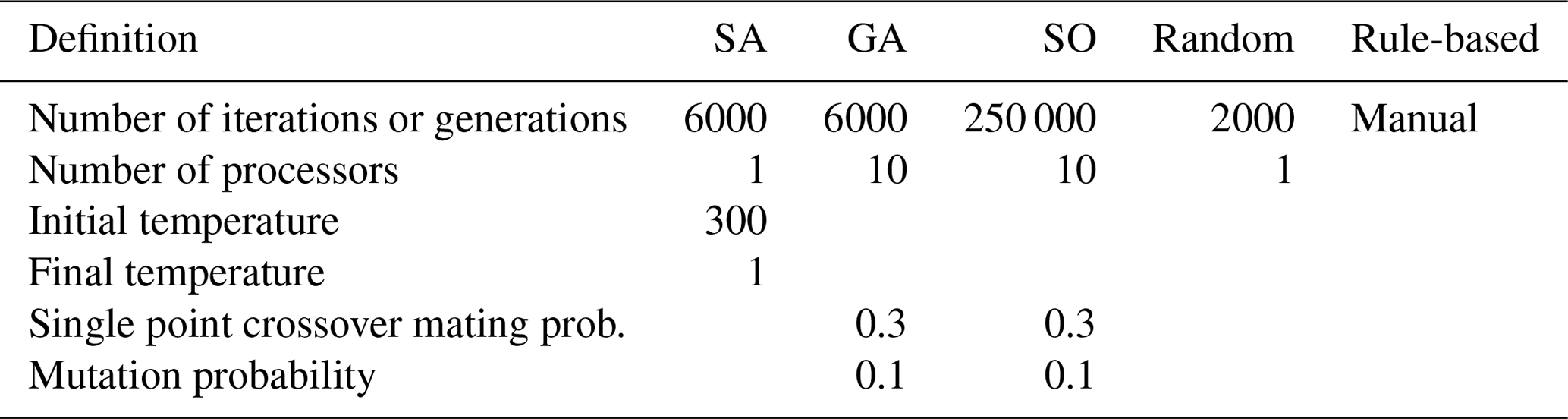
The parameters used for both algorithms were fixed by trial and error, and they are shown in Table 2. The authors are aware that parallel versions of SA exist (see, e.g., de Souza et al., 2010), but the single processor algorithm was chosen for this task. GA was run in parallel on 10 processors. With the same number of iterations (or generations), parallelization allows GA to explore 10 times more block configurations in a similar amount of time. SA was implemented by means of the Python package simanneal 0.5.0 (PyPi, 2019), and for GA the eaSimple algorithm in the DEAP library (Fortin et al., 2012) was used.
This optimization setup is computationally expensive regardless of the optimization algorithm used. The main bottleneck of the computation is the numerical solution of the Boussinesq equation, Eq. (2). A simpler alternative is to maximize the CWL change,
on its own. The CWL change is represented by the blue shaded area in Fig. 4. The rationale behind this alternative choice of the target variable is simple: in general, it is to be expected that a higher CWL will lead to wetter peat throughout the area. By completely bypassing the numerical solution of the PDE, this approach requires a fraction of the computational resources required for the full optimization procedure described above while potentially obtaining a good approximation of the minimum 〈ζ〉. SO was implemented by modifying the target variable of GA and was run for 250 000 iterations on 10 processors. This amounted to a similar computational effort as for the SA and GA algorithms.
To evaluate the performance of the optimization algorithms, we compared the resulting 〈ζ〉 against two other ways of positioning blocks: randomized and rule-based. The random block configurations were generated by randomly selecting locations from a uniform distribution. The value of 〈ζ〉 from 2000 random block configurations was computed and aggregated into the mean, . The rule-based configuration was constructed following standard procedure in the absence of computational tools: blocks were placed in perpendicular intersections of contour line maps with the canal raster (Ritzema et al., 2014). The rule-based positions of the blocks for b=10 are shown in Fig. 7a.
In order to enable a meaningful comparison between different setups, the average WTD resulting from these simulations was normalized with the average WTD in the absence of blocks, i.e.,
where 〈ζ(b)〉 is the 〈ζ〉 resulting from placing b blocks.
In a similar vein, we define the improvement of any block locating method to be
It measures the simple difference in mean WTD between the reference value, 〈ζ(0)〉, and the one resulting from placing b blocks with any of the methods above. In particular,
will be used to denote the mean improvement achieved by locating b blocks randomly.
Yet some more insight can be gained by looking at the results in terms of marginal benefits. We define the marginal benefit of building b+Δb blocks over b blocks to be
The quantities from Eqs. (14) to (17) are used to investigate the performance of all block placing methods in the task of minimizing 〈ζ〉 with a fixed number of blocks.
3.1 Reality check
In order to demonstrate that the peat hydrological model and the canal water level subroutine reproduce the expected qualitative behavior of the WTD, two figures are shown. Figure 5 shows the WTD drop during 3 consecutive dry days for a cross section of the drained area. After 3 dry days, the WTD drops about 10 cm at the midpoint between two drains separated by 1.4 km. When the canals are closer to each other, the WTD drop is larger, and if the canals are far enough apart, the peat remains fully saturated. The shape of the WTD solution between two canals is the typical one for diffusion PDEs such as Eq. (2).
The behavior of the canal water level subroutine is demonstrated by comparing the CWL change in a small drained area with and without canal blocks (Fig. 6). The effect of the canal blocks on the CWL propagates to different distances depending on local topography. If the slope of v is small, the effect of a single block can reach distances on the order of a kilometer. If, instead, v changes very steeply, the effect of a block reaches less far. In addition, the amount of rewetted peat as a consequence of building one block is dependent on the local topography and physical properties of the peat deposit and on the proximity to other canals. It is precisely the complexity of this response that calls for computational methods in order to solve the optimal block placement.
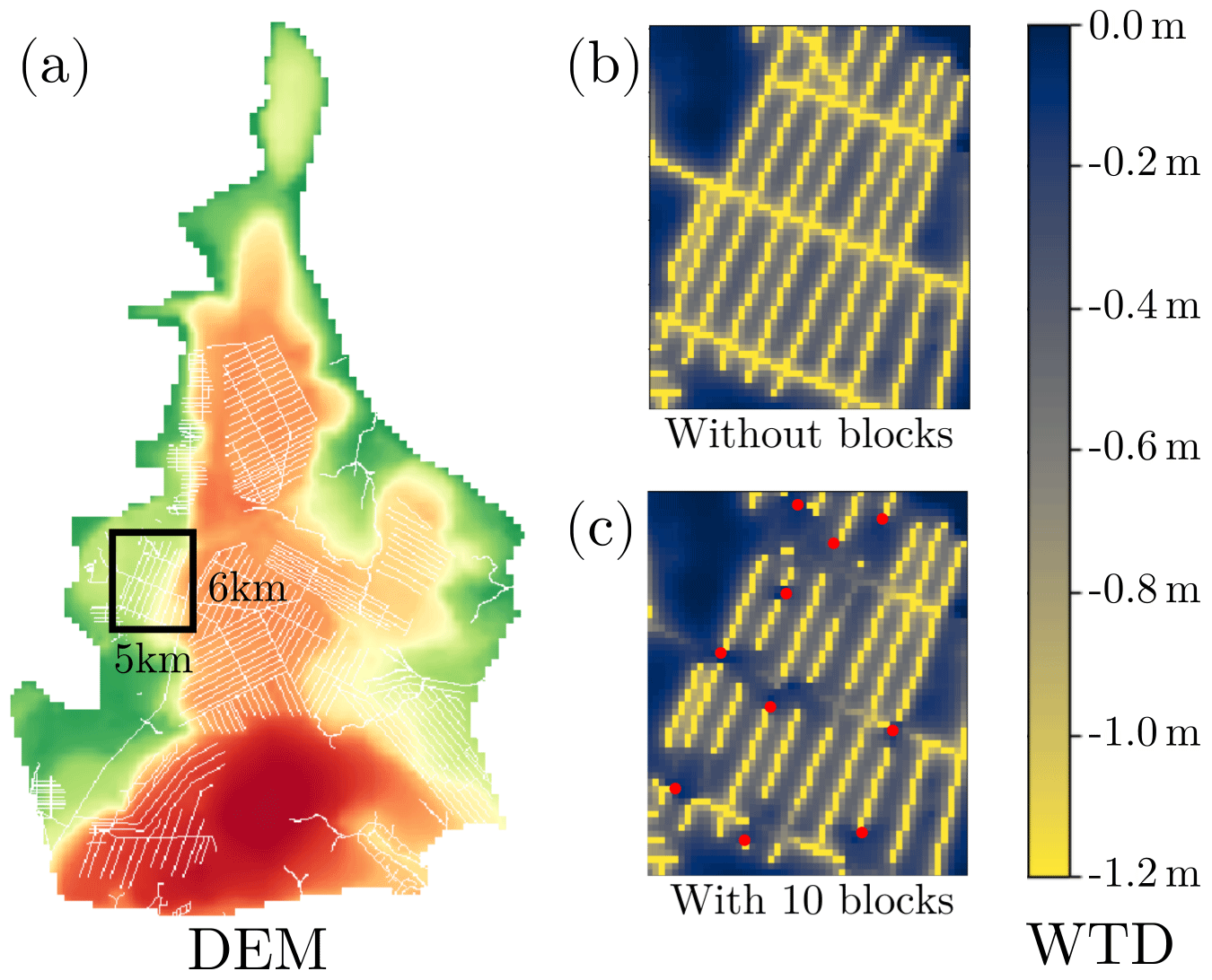
Figure 6WTD after 3 dry days with and without blocks. (a) DEM (colored) with the canal network superposed (white) and a rectangle indicating the area shown on the right. (b) WTD after 3 dry days without any blocks. (c) WTD after 3 dry days in the same area with 10 blocks (block locations are indicated by red dots). WTD in the canal raster is defined as . Blocks help raise the WTD closer to the surface, but their effectiveness varies depending on the local topography.
3.2 Canal block optimization
The average WTD was computed using different scenarios with an increasing number of canal blocks () for each of the block placing methods described (rule-based, random, SA, GA, SO). Their resulting values are shown in Fig. 7, and they constitute the main result of the present study.
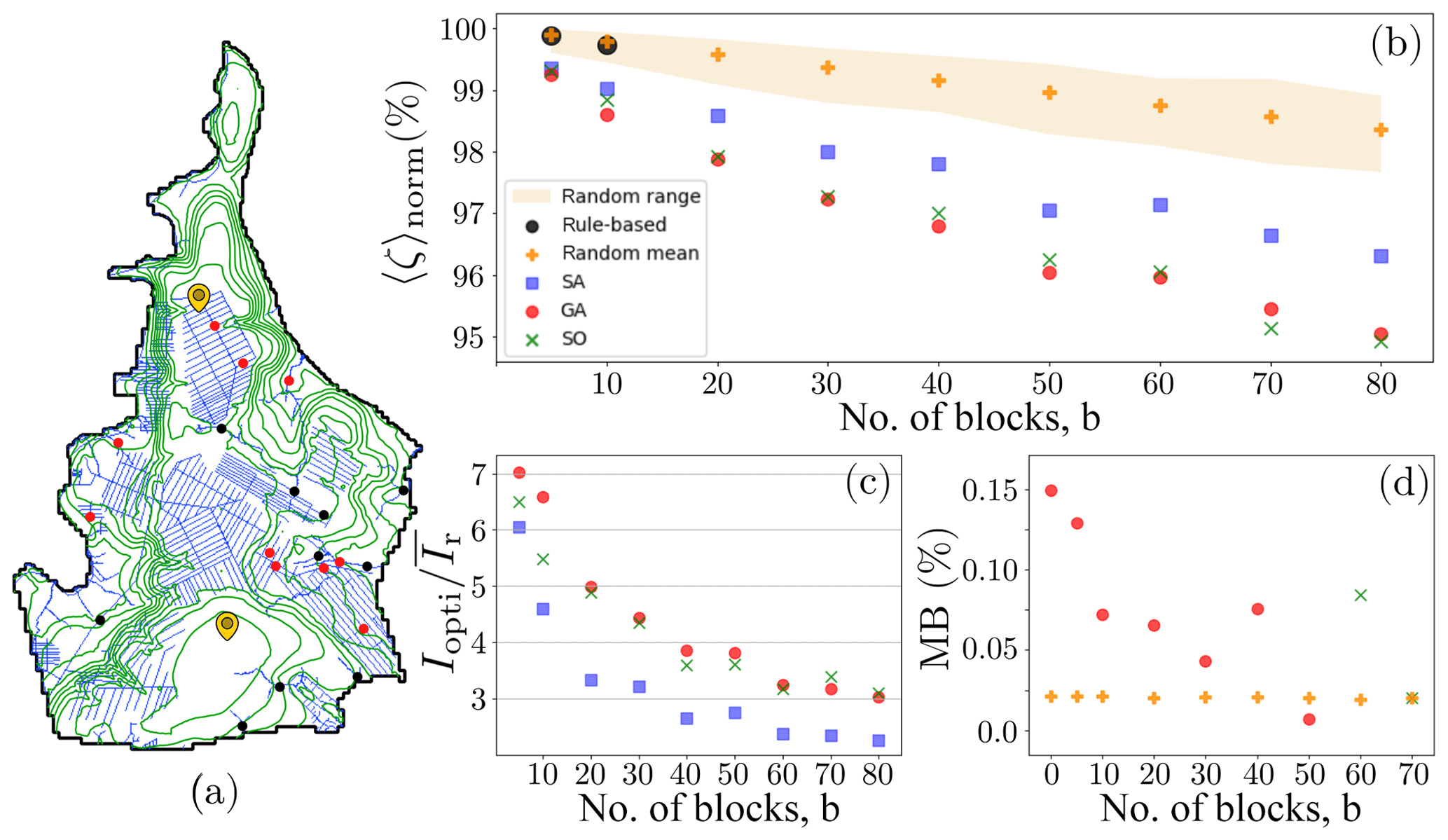
Figure 7Peat rewetting performance comparison of random block locations, the rule-based approach and the optimization algorithms (SA: simulated annealing; GA: genetic algorithm; SO: simple algorithm) for different numbers of blocks. (a) Map of the area. The canal network is shown in blue, and the contour lines in green. The resulting block positions for the case b=10, both for GA (red dots) and rule-based (black dots), are shown. Furthermore, the locations of the annual WTD simulations of Fig. 10 are indicated by yellow plectrum-like markers. (b) 〈ζ〉norm, defined in Eq. (14), as a function of the number of blocks. The rule-based approach was only carried out for 5 and 10 blocks. (c) Relative improvement of several block locating methods with respect to the mean of the random configuration, as defined in Eq. (16), for different numbers of blocks. (d) Marginal benefit, as defined in Eq. (17), for the best performing optimization algorithm and for the mean of the random configurations.
The most straightforward observation is that the more blocks there are, the larger the fraction of peat they will rewet, even if they are placed randomly. The second observation is that the optimization algorithms were able to find systematically better block positions than the random or the rule-based approaches. An informative way to gauge this difference is to realize that they were able to obtain with only 10 blocks the same amount of rewetted peat that the random configurations did with 60 blocks (Fig. 7b). The largest performance difference of the optimization algorithms over the random configuration happened for b=5, and it was approximately (Fig. 7c). As the number of blocks increased, I(b) decreased monotonically for every block placement method. For b=80, the maximum number of blocks considered in this study, was about 3 times . That is to say, at their best, the optimization algorithms were able to find block configurations that rewetted 7 times more peat than the random and the rule-based approaches did for the same number of blocks; at their worst, they were 3 times better than the random.
Another thing to note is that the rate at which 〈ζ〉 dropped for increasing b was markedly slower for the random block placements than it was for the ones resulting from the optimization algorithms. This can be quantified by the marginal benefit, MB(b) (Fig. 7d), which gives the slope of Fig. 7b. For clarity, only the MB for the best performing optimized solution is shown. MB(b) for the mean of the random locations was approximately constant, while for the best optimized solution it decreased with b.
As Fig. 7 shows, GA and SO performed similarly in the task of minimizing 〈ζ〉. At first sight, this might look surprising since the target variable for SO was not 〈ζ〉 itself, but the CWL changes. In order to understand this behavior, we need to know how strongly 〈ζ〉 and the CWL change are correlated with each other. Figure 8 shows that the optimal solutions for the two algorithms with 〈ζ〉 as a target variable (SA and GA) tend to favor block configurations with smaller 〈ζ〉 regardless of the CWL change, while SO is focused on maximizing CWL change and gets good performance in 〈ζ〉 as a by-product of the correlation between the two.

Figure 8Correlation between 〈ζ〉 and the CWL change for the random and the optimized block configurations. A larger block-induced change in CWL leads in general to a WTD closer to the surface. The number that accompanies each one of the points stands for b, the number of blocks that were located for each simulation.
The sensitivity of 〈ζ〉 to the block head level, hl, is demonstrated in Fig. 9 in which we plot 〈ζ〉norm resulting from the best available block positions for two different values of the block head level, . There can be a significant difference in the WTD, especially for large b.
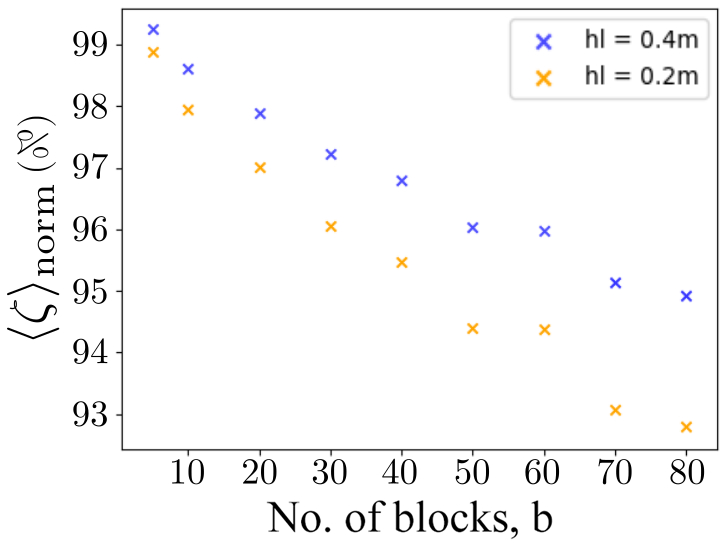
Figure 9Sensitivity of the average WTD to a difference in the block head level, hl. The values of 〈ζ(b)〉norm correspond to the optimal block positions computed for hl=0.2 m (orange) and hl=0.4 m (blue). The larger the blocks are, the higher the WTD has risen.
3.3 Implication for CO2 emissions
In order to draw further conclusions about the beneficial environmental impact of building canal blocks, we simulated the WTD for a full year under two different regimes: without any blocks and with the best available positions for the maximum number of blocks (80). Rainfall intensity was taken from Pekanbaru airport's weather station data, located in the same province as the target area. The heavy rainfall events registered during December 2012 were used as the starting point for the simulation, which was set up with completely saturated initial conditions. Evapotranspiration was set to 3 mm d−1 and the block head level to hl=0.4 m. For each of the two block setups, three daily WTD time series were recorded: the WTD in a drained area in the north, the WTD in the natural undrained peat dome in the south (Fig. 7a shows the exact locations) and the spatially averaged WTD over the whole area, ζ (Fig. 10).
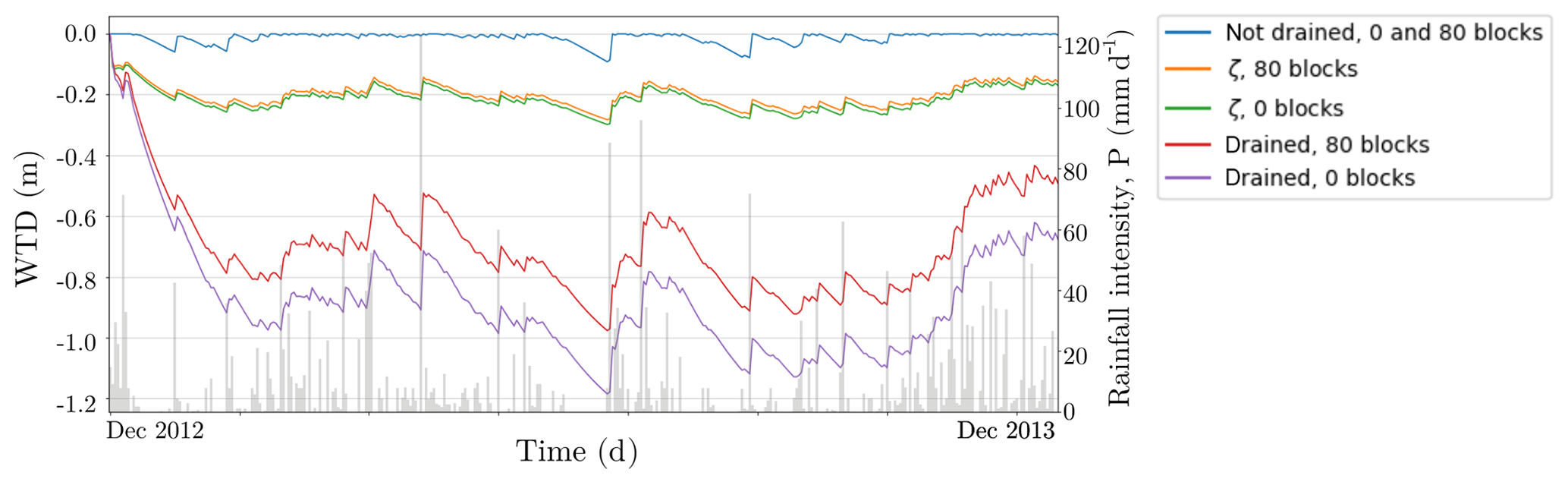
Figure 10Simulated daily WTD for two sites (drained and natural, see Fig. 7 for the exact locations) within the peatland area and the average WTD, ζ. The same period (December 2012–December 2013) was simulated without any blocks (green and purple lines) and with the 80 optimized blocks (orange and red lines). The spatial average ζ for is shown in orange and green. There was no appreciable difference in WTD in the undrained area between different block configurations, and the WTD is shown by a single line (blue line). Daily rainfall intensity is shown as gray vertical lines (data from Pekanbaru airport).
Nearby blocks were able to raise the water table by approximately 20 cm in the chosen drained location. At the other end of the spectrum, the WTD in the natural zone was not affected at all. As a result, the effect of the 80 blocks in the WTD over the whole area, given by ζ, was to raise it only by a few centimeters.
We obtained the following annual average values for the entire area: cm without any blocks and cm with the 80 best available blocks. In order to translate our results about the simulated annual WTD into the amount of emitted CO2, we used Eq. (8). Thus, Mg ha−1 yr−1 and Mg ha−1 yr−1 were obtained for the aforementioned block configurations.
4.1 Model evaluation and reality check
To the best of our knowledge, this work introduces the first freely available systematic tool that can quantify the rewetting performance of different block configurations. It operates on all the easily available data (data derived from weather and geographic information system, GIS) and combines them in a scientifically coherent way. It is also designed to be computationally feasible for large areas. Therefore, this tool can potentially be very useful for decision makers in greenhouse gas emission mitigation and drained peatland restoration contexts.
The qualitative behavior of the WTD and of the CWL in Figs. 5 and 6 reflects the following expected traits. First of all, WTD decreases with time as a result of drainage. Second, the smaller the distance between canals, the more the WTD drops for it was assumed that the system lacks any water input. In contrast, the WTD might stay close to the surface if the canals are far enough apart. Moreover, the effect of a set of blocks in the CWL propagates upstream in the correct way.
In this study, we did not validate the hydrological model against actual field data because there is no extensive, publicly available dataset. The aim of the paper was not to test a new hydrological model per se but rather to solve a management question by applying a preexisting one with parameter values derived from the literature. We assume that a more precise parameterization would not have changed the outcome of the optimization procedure, and thus the qualitative assessment of the parameters’ fitness was enough to fulfill our principal objective. It might be argued that in the absence of a quantitative validation, there is a high uncertainty in the simulated annual WTD of Fig. 10. However, the simulated daily WTD of Fig. 10 is in the same range and shows similar dynamics as those reported earlier for drained peatlands in similar areas (Jauhiainen et al., 2012; Hooijer et al., 2012; Evans et al., 2019) and for natural peatland forests in the Greater Sunda Islands (Cobb et al., 2017; Evans et al., 2019). Thus, we assume that WTD in Fig. 10 and the consecutive CO2 emissions, discussed in Sect. 4.3, are plausible. Furthermore, we are aware that the hydrological model presented here may produce inaccurate estimates. The discretization error introduced with a daily time step could be substantial, and the convergence test could be improved, for instance, by studying the behavior of the solution with smaller time steps. However, accuracy and convergence needed to be sacrificed as a tradeoff against runtime. The hydrological model needed to be simplified just enough so that a meaningful amount of block setups could be explored and the management question could be successfully tackled.
Some remarks about the assumptions made in the canal water level subroutine are in order. As explained in Sect. 2.2.1, the CWL in the absence of blocks was inferred from the DEM using a constant w (see Eq. 1). This implies that any local fluctuation in the height of the DEM is directly transferred to the CWL. Indeed, a CWL derived in this manner is not expected to be monotonically decreasing in the direction of water flow. This non-monotonic nature of the CWL can lead to incorrect predictions of the effect a block has on the CWL. Another source of misrepresentation of the connectivity of the CWL comes from the artifact that the resolution of the DEM, 100 m×100 m, introduces. According to the rules in Sect. 2.2.1, if two different canals happen to be less than 100 m apart, then rule 1 will erroneously infer that those two pixels are contiguous. Moreover, as mentioned in the description of the study area, there were small field drains that were not captured by the raster maps due to their coarse resolution. All these problems could be ameliorated by using a separate, complete canal network vector layer which contains the direction of the water flow. There is yet another class of approximations that were made in Eq. (1). First of all, in reality the distance between the peat surface and the CWL in the absence of blocks, w, is not constant; it might vary in time due to seasonality and in space at different heights. It is also worth noting that the resulting water profile after building a block is typically not a perfectly horizontal line, as depicted with dotted lines in Fig. 4, but an inclined one. Furthermore, we are implicitly neglecting tidal effects which could affect the water flow direction close to the seashore. All these approximations were either imposed by the quality of the data or judged to be of secondary importance in the computation of the CWL.
4.2 Canal block optimization
Two basic observations can be drawn from Fig. 7. The first is that the performance of the rule-based approach is comparable to that of the random location of the blocks. The positions for the blocks in the rule-based approach were located in perpendicular intersections between contour lines and canals (Ritzema et al., 2014), as shown in Fig. 7a. Figure 7a makes it apparent that it is very difficult to predict the effect of the blocks on the WTD by using logical reasoning alone: there are no evident differences between the locations of the blocks placed according to the rule-based and the GA methods. The rule-based approach was only carried out for 5 and 10 blocks, yet as b increases, so does the complexity of the task, and it is therefore not expected that it would perform any differently from the random method when the amount of blocks increased. This leads us to conclude that the combination of the random trials and the rule-based approach may be interpreted as the best humanly possible result in the absence of any computational tools.
The second observation is that the optimization algorithms performed systematically better than the random and rule-based approaches. Going into further details, GA and SO were more successful in minimizing 〈ζ〉 than SA. Under the same conditions, GA and SA are expected to perform similarly (Rao, 2009), but the single processor nature of SA restricted its search space to be 10 and 417 times smaller than those of GA and SO, respectively. The optimization performance of GA and SO was very similar for all numbers of blocks, but SO performed best for higher numbers of blocks. Both strategies are sound from the hydrological point of view, but their success in the optimization happens for different reasons. The good performance of SO can be explained by two factors. On the one hand, its simplicity allowed it to explore 42 times more block configurations than GA, thus being able to reach a fairly good approximation of the maximum CWL change even for large b. On the other hand, 〈ζ〉 and the CWL change correlated strongly as is shown in Fig. 8, meaning that SO got a good result in 〈ζ〉 minimization as a byproduct of CWL change maximization. Another way of putting this is that, unlike the CWL change, 〈ζ〉 gets the full three-dimensional information about the catchment topography and the peat physical properties, but in return the optimization task is more demanding. This may not be true for every study area. For instance, in domains with a high spatial heterogeneity in peat physical properties, the correlation is expected to be less evident. As the number of blocks to be located, b, increases, the size of the search space does so as (which has a maximum at around ). It is this rapid increase in computational complexity for reasonable numbers of blocks which might explain the better performance of SO when the number of blocks is greater. Following this line of reasoning, the fact that SO performs better than GA only for leads us to conclude that computational resources are limiting the performance of GA at least at those values of b; i.e., a substantially better performance of GA is to be expected for high b if the number of iterations increased. The success of both GA and SO calls for an alternative optimization strategy that would profit from both algorithms' strengths. Such an algorithm could be designed so that GA was initialized with several optima from the fast SO.
However interesting, comparing the performance of different algorithms was not the objective of this work. Instead, the main conclusion can be drawn by contrasting the outcome of the optimization algorithms with the best humanly available guesses. With the same number of blocks, the reduction in average WTD by the optimized block configuration is systematically greater than the one achieved simply by logical reasoning (Ritzema et al., 2014; Armstrong et al., 2009). This contrast is most significant for a small number of blocks, for which the average WTD reduction resulting from the best available block locations is up to 7 times larger than the one derived from the mean of the random blocks (Fig. 7c). As the number of blocks increases, the relative improvement, I, decreases and so does its derivative, the marginal benefit, MB, for the best available optimized block positions (Fig. 7d). This implies that the benefit of adding one more block decreases with the number of blocks that are already built. This fact is likely due to two main reasons. On the one hand is the aforementioned difficulty for the algorithms to find the optimal solution in an increasingly larger search space. On the other hand is the fact that the best positions might already be occupied by some of the blocks. Theoretically, there exists a limiting number of blocks at which the finite size of the area would make the marginal benefit decrease even with the absolute best block locations. We suspect that with the current b we were not yet at the limits of the system and that this finite-size phenomenon will only be relevant for larger b. In contrast, the marginal benefit of adding one more block was almost constant for the random block configuration (i.e., the decrease of was linear), which implies that if the blocks were to be built randomly, each additional block would be equally successful in reducing 〈ζ〉.
It is not expected that a different choice of parameters would affect these general observations of the optimization results. While different parameterizations will result in a different WTD in absolute terms (see, e.g., the case of varying hl; Fig. 9), the relative differences in WTD between all block locating methods remain for different choices of parameter values.
It is also worth mentioning that solving the steady-state version of the Boussinesq equation, Eq. (2), was explored as the way to compute the target variable of the optimization, 〈ζ〉. However, this approach was discarded in favor of the presented transient equation due to two observations. First, the steady-state solution does not yield a proper description of groundwater behavior. In tropical climates, rainfall is a key driver of hydrological processes, and rainfall intensity is highly variable in time. Thus forcing the model to run with average rainfall and evapotranspiration does not result in a satisfactory model of these systems. Second, since the PDE is nonlinear, the computational time needed to solve the steady-state version was comparable to the time needed to solve the transient equation.
4.3 Implication for CO2 emissions
The simulated annual CO2 emissions of Sect. 3.3 are within the range of the values in the literature for peatlands in the same region (Hooijer et al., 2012; Evans et al., 2019). Relatively speaking, building 80 blocks for the whole 931 km2 area mitigates only 2.24 % of the CO2 emissions. The reason for this modest performance might lie in 80 being too few blocks for such a large area (our method remains applicable for the placement of a larger number of blocks at the expense of longer computing times). Let us note that there are approximately 1100 km of canals. When placing 80 blocks, the expected distance between a pair of blocks is about 14 km. Yet the influence a block has on the CWL spans, in our study area, a maximum of 2 km. Let us stretch our results further to give a rough estimate of the number of blocks needed in order to prevent 10 % of the emissions in the study area. Taking the values for 80 blocks as a reference, and assuming that 〈ζ(b)〉 decreases linearly with b, 350 blocks would be needed to reach that emission reduction goal. This would correspond to having on average one block every 3 km. Of course, assuming that 〈ζ(b)〉 decreases linearly with b is only a rough approximation (Fig. 7 shows the true dependence). This nonlinear dependence points to the second reason for the modest performance of the 80 blocks: there seems to be room for improvement in our optimization procedure.
On the other hand, looking at the CO2 emissions in absolute terms, building 80 blocks prevents the emission of 1.01 t ha−1 yr−1 or a total of 94 156 t annually throughout the whole area. To get a grasp of the magnitude of these numbers, they are on the order of what 25 000 cars with an annual mileage of 20 000 km would emit.
It is clear that canal blocking raises WTD and therefore decreases CO2 fluxes in tropical drained peatlands. The current application does not account for methane emissions which might increase with rising WTD (Deshmukh et al., 2020; Manning et al., 2019). The optimization problem would have to be slightly reformulated to account for both negative and positive responses of C emissions to WTD rise. Yet the approach presented here would remain applicable provided that the hydrological model was extended to include a methane emission subroutine. This is left as a rather interesting open question for future work.
4.4 Application to real-life scenarios
When considering the applicability of our method to real-life scenarios, some of its underlying assumptions should be stated clearly. Our method assumes that it is possible to build a block at any given point in the canal raster and that the cost of doing so is constant and independent of site properties. Armstrong et al. (2009) carried out a comprehensive study of several drain blocking strategies in blanket peatlands in the UK. It is apparent from their work that the aforementioned assumptions do not hold in most real-life canal blocking scenarios. In particular, Armstrong et al. (2009) recommend building different types of blocks depending on the following site-specific variables: gradient of the CWL, canal width, peat wetness, peat depth, exposition of underlying mineral soil and distance to building site. If our method is to have the desired practical impact, it should be able to accommodate these points. One way to do so would be to construct a realistic function that would return block cost based on the above site properties. Indeed, the variables above may be easily translated into economical terms. For instance, a block built at a point of the CWL where the head gradient is large requires stable, expensive structures to avoid block failure. Similarly, a remote building site, wide canals and wet conditions increase the cost of building a block. Moreover, the bulk of the data needed to construct the block cost function is already part of the model (peat depth, DEM, WTD). Regarding the formulation of the optimization problem, block cost could be introduced simply by changing the constraint equation, Eq. (12); instead of fixing the number of blocks, the block cost could be fixed.
It remains true that choosing the location of a set of blocks for best performance is a daunting task due to the complexity of the response of the water table and even more so when different types of blocks are considered. Therefore, the specifics of Figs. 7 to 9 may change when several block types are considered, yet it is expected that the general trend would be similar; human guesses will not perform as well as optimized block locations. Nevertheless, the block locating method described in this work will never replace expert knowledge. It should rather build upon it in order to have the desired practical impact. Our approach acknowledges that expert knowledge alone might not be enough to solve the rewetting problem of drained peatlands in an optimal way, and it opens up the opportunity for local experts and organizations to use process-based hydrological modeling and numerical optimization techniques, which, as we have hopefully succeeded to show, can be powerful tools.
We constructed an optimization scheme that looks for the maximum water table rise for a drained peatland area given a fixed amount of canal blocks. Our results show that, with the same amount of resources (i.e., number of blocks), the present computational setup enables a more effective canal blocking restoration of drained peatlands than human guesses do. The computational approach also enables a cost-benefit analysis to solve several management questions.
The information about the topology of the canal network was stored in a (sparse) matrix, M, of dimensions (n×n), where n is the number of pixels in the canal raster. For any two pixels of the canal raster, i and j, the entries of the matrix M are
Contiguous upstream pixels were defined in rules 1 and 2 of Sect. 2.2.1. Note in particular that if MAB=1, that is, if pixels A and B are adjacent and pixel B is upstream, it follows that MBA=0. Moreover, note that Mii=0 for any i. In other words, M is not symmetrical, and all the elements of its diagonal are equal to 0. M can then be interpreted as the adjacency matrix of the simple, directed graph, G, whose nodes are the pixels of the canal raster, and an edge exists if two nodes are in direct physical contact (Newman, 2018). In such a graph, the direction of the edges is the opposite to the direction of the water flow. Within this setup, the vector , where k is the vector of the blocks' positions defined in Eq. (10), contains the information about all the first neighbors of the blocks in k. Specifically,
Say we wish to build a block in pixel A, that is, ki=1 only for i=A. The operations that the canal water level subroutine performs in order to propagate the effect of this block to the neighboring nodes of A are described in Algorithm 1.

Line 1 sets the new value of the CWL in the pixel where the block is built to be h units higher. In line 2, the neighboring pixels that are contiguous upstream pixels of A are stored into k′. The two conditions in line 4 effectively implement rules 1 and 2 of Sect. 2.2.1. Finally, for those pixels for which these two conditions are met, the CWL gets updated.
For the sake of readability, Algorithm 1 shows a single step in the process of computing v′; i.e., it only updates the CWL for the first upstream pixels of a block located in A. In order to obtain the final CWL, the operations in Algorithm 1 would have to be iterated over for all successive v′ until no more pixels were affected in the canal network. The algorithm could also be extended straightforwardly to any number of blocks. Following these rules, the CWL obtained after building a block looks like the one in Fig. 4.
The source code and the data used are available under the MIT license at https://doi.org/10.5281/zenodo.3741043 (Urzainki and Laurén, 2020; https://github.com/LukeEcomod/blopti, last access: 6 April 2020).
IU and AL contextualized the problem and developed the model code. IU performed the simulations. AB, IB and MN produced and validated the datasets. KH helped formulate the research goals and methods. MP, HH and AL contributed by reviewing and editing the paper. IU prepared the paper with contributions from all coauthors.
The authors declare that they have no conflict of interest.
The authors wish to thank the referees' thorough comments on the paper and Harri Koivusalo for useful discussions about the hydrological modeling. Furthermore, the authors wish to acknowledge CSC – IT Center for Science, Finland, for computational resources.
This paper was edited by Alexandra Konings and reviewed by Alex Cobb and one anonymous referee.
Armstrong, A., Holden, J., Kay, P., Foulger, M., Gledhill, S., Mcdonald, A. T., and Walker, A.: Drain-blocking techniques on blanket peat: A framework for best practice, J. Environ. Manage., 90, 3512–3519, https://doi.org/10.1016/j.jenvman.2009.06.003, 2009. a, b, c, d, e, f
Baird, A. J., Low, R., Young, D., Swindles, G. T., Lopez, O. R., and Page, S.: High permeability explains the vulnerability of the carbon store in drained tropical peatlands, Geophys. Res. Lett., 44, 1333–1339, https://doi.org/10.1002/2016GL072245, 2017. a
Bear, J.: Hydraulics of Groundwater, McGraw-Hill Series in Water Resources and Environmental Engineering, McGraw-Hill, New York 1979. a
Carlson, K. M., Goodman, L. K., and May-Tobin, C. C.: Modeling relationships between water table depth and peat soil carbon loss in Southeast Asian plantations, Environ. Res. Lett., 10, 074006, https://doi.org/10.1088/1748-9326/10/7/074006, 2015. a, b
Cobb, A. R., Hoyt, A. M., Gandois, L., Eri, J., Dommain, R., Salim, K. A., Kai, F. M., Su'ut, N. S. H., and Harvey, C. F.: How temporal patterns in rainfall determine the geomorphology and carbon fluxes of tropical peatlands, P. Natl. Acad. Sci. USA, 114, E5187–E5196, https://doi.org/10.1073/pnas.1701090114, 2017. a, b, c
Connorton, B. J.: Does the regional groundwater-flow equation model vertical flow?, J. Hydrol., 79, 279–299, https://doi.org/10.1016/0022-1694(85)90059-9, 1985. a
Couwenberg, J., Dommain, R., and Joosten, H.: Greenhouse gas fluxes from tropical peatlands in south-east Asia, Glob. Change Biol., 16, 1715–1732, https://doi.org/10.1111/j.1365-2486.2009.02016.x, 2010. a
Deshmukh, C. S., Julius, D., Evans, C. D., Nardi, Susanto, A. P., Page, S. E., Gauci, V., Laurén, A., Sabiham, S., Agus, F., Asyhari, A., Kurnianto, S., Suardiwerianto, Y., and Desai, A. R.: Inmpact of forest plantation on methane emissions from tropical peatland, Glob. Change Biol., 26, 2477–2495, https://doi.org/10.1111/gcb.15019, 2020. a
de Souza, S. X., Suykens, J. A. K., Vandewalle, J., and Bollé, D.: Coupled Simulated Annealing, IEEE T. Syst. Man Cy. B, 40, 320–335, 2010. a
Dunn, S. and Mackay, R.: Modelling the hydrological impacts of open ditch drainage, J. Hydrol., 179, 37–66, https://doi.org/10.1016/0022-1694(95)02871-4, 1996. a, b
Evans, C. D., Williamson, J. M., Kacaribu, F., Irawan, D., Suardiwerianto, Y., Hidayat, M. F., Ari, L., and Page, S. E.: Rates and spatial variability of peat subsidence in Acacia plantation and forest landscapes in Sumatra, Indonesia, Geoderma, 338, 410–421, https://doi.org/10.1016/j.geoderma.2018.12.028, 2019. a, b, c, d, e, f, g
Fortin, F.-A., De Rainville, F.-M., Gardner, M.-A., Parizeau, M., and Gagné, C.: DEAP: Evolutionary Algorithms Made Easy, J. Mach. Learn. Res., 13, 2171–2175, 2012. a
Guyer, J. E., Wheeler, D., and Warren, J. A.: FiPy: Partial Differential Equations with Python, Comput. Sci. Eng., 11, 6–15, 2009. a
Holden, J.: Peatland hydrology and carbon release: why small-scale process matters, Philos. T. Roy. Soc. A, 363, 2891–2913, https://doi.org/10.1098/rsta.2005.1671, 2005. a
Holden, J., Evans, M. G., Burt, T. P., and Horton, M.: Impact of land drainage on peatland hydrology, J. Environ. Qual., 35, 1764–1778, 2006. a
Hooijer, A., Page, S., Canadell, J. G., Silvius, M., Kwadijk, J., Wösten, H., and Jauhiainen, J.: Current and future CO2 emissions from drained peatlands in Southeast Asia, Biogeosciences, 7, 1505–1514, https://doi.org/10.5194/bg-7-1505-2010, 2010. a, b, c, d, e
Hooijer, A., Page, S., Jauhiainen, J., Lee, W. A., Lu, X. X., Idris, A., and Anshari, G.: Subsidence and carbon loss in drained tropical peatlands, Biogeosciences, 9, 1053–1071, https://doi.org/10.5194/bg-9-1053-2012, 2012. a, b
Jauhiainen, J., Hooijer, A., and Page, S. E.: Carbon dioxide emissions from an Acacia plantation on peatland in Sumatra, Indonesia, Biogeosciences, 9, 617–630, https://doi.org/10.5194/bg-9-617-2012, 2012. a, b, c, d, e, f, g
Jin, X., Pukkala, T., and Li, F.: Fine-tuning heuristic methods for combinatorial optimization in forest planning, Eur. J. For. Res., 135, 765–779, 2016. a
Koivusalo, H., Karvonen, T., and Lepistö, A.: A quasi-three-dimensional model for predicting rainfall-runoff processes in a forested catchment in Southern Finland, Hydrol. Earth Syst. Sci., 4, 65–78, https://doi.org/10.5194/hess-4-65-2000, 2000. a, b
Laurén, A., Asikainen, A., Kinnunen, J.-P., Palviainen, M., and Sikanen, L.: Improving the financial performance of solid forest fuel supply using a simple moisture and dry matter loss simulation and optimization, Biomass Bioenerg., 116, 72–79, 2018. a
Le Quéré, C., Andrew, R. M., Friedlingstein, P., Sitch, S., Hauck, J., Pongratz, J., Pickers, P. A., Korsbakken, J. I., Peters, G. P., Canadell, J. G., Arneth, A., Arora, V. K., Barbero, L., Bastos, A., Bopp, L., Chevallier, F., Chini, L. P., Ciais, P., Doney, S. C., Gkritzalis, T., Goll, D. S., Harris, I., Haverd, V., Hoffman, F. M., Hoppema, M., Houghton, R. A., Hurtt, G., Ilyina, T., Jain, A. K., Johannessen, T., Jones, C. D., Kato, E., Keeling, R. F., Goldewijk, K. K., Landschützer, P., Lefèvre, N., Lienert, S., Liu, Z., Lombardozzi, D., Metzl, N., Munro, D. R., Nabel, J. E. M. S., Nakaoka, S., Neill, C., Olsen, A., Ono, T., Patra, P., Peregon, A., Peters, W., Peylin, P., Pfeil, B., Pierrot, D., Poulter, B., Rehder, G., Resplandy, L., Robertson, E., Rocher, M., Rödenbeck, C., Schuster, U., Schwinger, J., Séférian, R., Skjelvan, I., Steinhoff, T., Sutton, A., Tans, P. P., Tian, H., Tilbrook, B., Tubiello, F. N., van der Laan-Luijkx, I. T., van der Werf, G. R., Viovy, N., Walker, A. P., Wiltshire, A. J., Wright, R., Zaehle, S., and Zheng, B.: Global Carbon Budget 2018, Earth Syst. Sci. Data, 10, 2141–2194, https://doi.org/10.5194/essd-10-2141-2018, 2018. a
Manning, F. C., Kho, L. K., Hill, T. C., Cornulier, T., and Teh, Y. A.: Carbon emissions from oil palm plantations on peat soil, Frontiers in Forests and Global Change, 2, 37 pp., https://doi.org/10.3389/ffgc.2019.00037, 2019. a
Miettinen, J., Hooijer, A., Vernimmen, R., Liew, S. C., and Page, S. E.: From carbon sink to carbon source: extensive peat oxidation in insular Southeast Asia since 1990, Environ. Res. Lett., 12, 024014, https://doi.org/10.1088/1748-9326/aa5b6f, 2017. a
Minkkinen, K. and Laine, J.: Long-term effect of forest drainage on the peat carbon stores of pine mires in Finland, Can. J. Forest Res., 28, 1267–1275, https://doi.org/10.1139/x98-104, 1998. a
Newman, M.: Networks, 2nd Edn., Oxford University Press, New York, 2018. a
Nichols, J. E. and Peteet, D. M.: Rapid expansion of northern peatlands and doubled estimate of carbon storage, Nat. Geosci., 12, 917–921, https://doi.org/10.1038/s41561-019-0454-z, 2019. a
Nieminen, M., Sallantaus, T., Ukonmaanaho, L., and Sarkkola, S.: Nitrogen and phosphorus concentrations in discharge from drained peatland forests are increasing, Sci. Total Environ., 609, 974–981, https://doi.org/10.1016/j.scitotenv.2017.07.210, 2017. a
Ojanen, P., Minkkinen, K., Alm, J., and Penttilä, T.: Soil-atmosphere CO2, CH4 and N2O fluxes in boreal forestry-drained peatlands, Forest Ecol. Manage., 260, 411–421, https://doi.org/10.1016/j.foreco.2010.04.036, 2010. a, b
Page, S. E. and Baird, A. J.: Peatlands and Global Change: Response and Resilience, Annu. Rev. Env. Resour., 41, 35–57, 2016. a
Page, S. E. and Hooijer, A.: In the line of fire: the peatlands of Southeast Asia, Philos. T. Roy. Soc. B, 371, 20150176, https://doi.org/10.1098/rstb.2015.0176, 2016. a
Page, S. E., Rieley, J. O., and Banks, C. J.: Global and regional importance of the tropical peatland carbon pool, Glob. Change Biol., 17, 798–818, https://doi.org/10.1111/j.1365-2486.2010.02279.x, 2011. a
Päivänen, J.: Hydraulic conductivity and water retention in peat soils, Acta Forestalia Fennica, 129, 7563, https://doi.org/10.14214/aff.7563, 1973. a
Päivänen, J. and Hånell, B.: Peatland Ecology and Forestry -A Sound Approach, University of Helsinki Department of Forest Sciences Publications 3, Helsinki, 2012. a
Parry, L. E., Holden, J., and Chapman, P. J.: Restoration of blanket peatlands, J. Environ. Manage., 133, 193–205, 2014. a, b
PyPi: Simulated Annealing in Python, available at: https://pypi.org/project/simanneal/, last access: 16 December 2019. a
Rao, S. S.: Engineering Optimization -Theory and Practice, John Wiley & Sons, Hoboken, New Jersey, 2009. a, b, c
Reddy, K. R. and DaLaune, R. D.: Biogeochemistry of Wetlands, CRC Press, Florida, USA, 2008. a, b
Ritzema, H., Limin, S., Kusin, K., Jauhiainen, J., and Wösten, H.: Canal blocking strategies for hydrological restoration of degraded tropical peatlands in Central Kalimantan, Indonesia, Catena, 114, 11–20, 2014. a, b, c, d, e, f
Skaggs, R. W.: A water management model for artificially drained soils, Technical Bulletin, North Carolina Agricultural Experiment Station, 267, 54 pp., 1980. a
Urzainki, I. and Laurén. A.: Blopti – canal blocking optimization, Zenodo, https://doi.org/10.5281/zenodo.3741043, 2020. a
Usup, A., Hashimoto, Y., Takahashi, H., and Hayasaka, H.: Combustion and thermal characteristics of peat fire in tropical peatland in Central Kalimantan, Indonesia, Tropics, 14, 1–9, https://doi.org/10.3759/tropics.14.1, 2004. a
Vernimmen, R., Hooijer, A., Yuherdha, A. T., Visser, M., Pronk, M., Eilander, D., Akmalia, R., Fitranatanegara, N., Mulyadi, D., Andreas, H., Ouellette, J., and Hadley, W.: Creating a Lowland and Peatland Landscape Digital Terrain Model (DTM) from Interpolated Partial Coverage LiDAR Data for Central Kalimantan and East Sumatra, Indonesia, Remote Sensing, 11, 1152, https://doi.org/10.3390/rs11101152, 2019. a
Versteeg, H. K. and Malalasekera, W.: An Introduction to Computational Fluid Dynamics, 2nd Edn., Pearson Education Limited, Harlow, England, 2007. a
Wösten, J. H. M., Clymans, E., Page, S. E., Rieley, J. O., and Limin, S. H.: Peat-water interrelationships in a tropical peatland ecosystem in Southeast Asia, Catena, 73, 212–224, 2008. a, b
Xu, J., Morris, P. J., Liu, J., and Holden, J.: PEATMAP: Refining estimates of global peatland distribution based on a meta-analysis, Catena, 160, 134–140, 2018. a