the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 25 Oct 2022
| 25 Oct 2022
A question of scale: modeling biomass, gain and mortality distributions of a tropical forest
Nikolai Knapp
Sabine Attinger
Andreas Huth
Describing the heterogeneous structure of forests is often challenging. One possibility is to analyze forest biomass in different plots and to derive plot-based frequency distributions. However, these frequency distributions depend on the plot size and thus are scale dependent. This study provides insights about transferring them between scales. Understanding the effects of scale on distributions of biomass is particularly important for comparing information from different sources such as inventories, remote sensing and modeling, all of which can operate at different spatial resolutions. Reliable methods to compare results of vegetation models at a grid scale with field data collected at smaller scales are still missing.
The scaling of biomass and variables, which determine the forest biomass, was investigated for a tropical forest in Panama. Based on field inventory data from Barro Colorado Island, spanning 50 ha over 30 years, the distributions of aboveground biomass, biomass gain and mortality were derived at different spatial resolutions, ranging from 10 to 100 m. Methods for fitting parametric distribution functions were compared. Further, it was tested under which assumptions about the distributions a simple stochastic simulation forest model could best reproduce observed biomass distributions at all scales. Also, an analytical forest model for calculating biomass distributions at equilibrium and assuming mortality as a white shot noise process was tested.
Scaling exponents of about −0.47 were found for the standard deviations of the biomass and gain distributions, while mortality showed a different scaling relationship with an exponent of −0.3. Lognormal and gamma distribution functions fitted with the moment matching estimation method allowed for consistent parameter transfers between scales. Both forest models (stochastic simulation and analytical solution) were able to reproduce observed biomass distributions across scales, when combined with the derived scaling relationships.
The study demonstrates a way of how to approach the scaling problem in model–data comparisons by providing a transfer relationship. Further research is needed for a better understanding of the mechanisms that shape the frequency distributions at the different scales.
- Article
(2699 KB) - Full-text XML
-
Supplement
(2156 KB) - BibTeX
- EndNote





Forests are complex, heterogeneous ecosystems with characteristics which can be measured at different scales. They are inherently dynamic systems which are influenced by climate and disturbances (Lewis et al., 2015). In any given forest ecosystem, biomass is variable in space and time, driven by the interplay of productivity and mortality (Rutishauser et al., 2019). Different approaches are being used to quantify forest biomass stocks and changes. These approaches include forest inventory, eddy flux measurements, remote sensing and forest modeling (Mitchard, 2018; Shugart et al., 2015).
The listed methods for quantifying forest biomass often operate at different spatial scales, regarding their extents and resolutions. Inventories measure and map forests at the resolution of individual trees. From the individuals, biomass per area units can be derived. Inventory plots have extents ranging from a few square meters (e.g., national forest inventories) to several hectares (e.g., research megaplots). Eddy flux towers have typical footprint sizes in the range a few hundred meters (Rebmann et al., 2005). Such measurements are an important information source for deriving forest carbon budgets (Brienen et al., 2015; Hetzer et al., 2020; Hubau et al., 2020).
Much larger extents than the ones of ground-based measurements can be covered by remote sensing. Remote sensing products are typically gridded maps consisting of square-shaped pixels with side lengths, depending on the sensor platform and type of product. Typical pixel sizes are 1 m for canopy height models, 10 to 30 m for tree cover and disturbance maps, 100 m for biomass, and 1 km for productivity maps (Asner et al., 2013; Hansen et al., 2013; Running et al., 2004).
Spatial scale is also important for forest models. Models which simulate the biomass dynamics and carbon balance of forests can have different complexities. At one end of the spectrum, there are spatially explicit, individual-based models which include physiological processes for modeling the effects of environmental drivers on the carbon balance (Shugart et al., 2018). On the other end, there are spatially implicit differential equation models describing the carbon balance in terms of and aggregated biomass gains and losses (Fisher et al., 2008). Also, the spatial resolution of the output of forest models can vary. While global vegetation models produce results at large scales (global extent and resolutions of, e.g., 0.5∘; Maréchaux et al., 2021), gap forest models work at local scales (extents of several hectares and resolutions of forest gap sizes, e.g., 20 m, or individual trees; Fischer et al., 2016). How to deal with differences in resolutions of ecological models is an open question (Fritsch et al., 2020).
The heterogeneity of a forest landscape can be described by frequency distributions of forest attributes, e.g., biomass. Despite the differences in measurement areas between the methods, it is common practice to report biomass stocks and carbon fluxes in per hectare units. Having units standardized to one reference scale is important to make values comparable and transferable but bears the risk of taking the unit t ha−1 too literally and neglecting the fact that the actual areas might be of very different size. Since the actual areas, which these values represent, do often deviate from 1 ha, it is crucial to consider the scale dependence of the shapes of distributions. It has been shown that forest biomass distributions become increasingly skewed and long-tailed with decreasing plot size (Chave et al., 2003). At small scales these distributions cover a wide range of values from near 0 t ha−1 in gaps to 1000 t ha−1 in patches with very large trees. However, at the actual 1 ha scale such extreme values are uncommon to observe and the range of typical values is much more reduced.
Commonly, variance decreases with increasing scale. For independent identically distributed (iid) random variables, the aggregation by a factor n (i.e., taking the mean of n values to derive one aggregated value) results in a reduction of variance by the factor n and thus a reduction of standard deviation by a factor , while the expected value (distribution mean) stays the same (Otto and Day, 2011). More generally, also for non-iid and spatial data, the variance reduces with aggregation, as more and more of the fine-scale variance occurs within and not above the aggregation level (Smith and Urban, 1988), which is referred to dispersion variance in geostatistics (Marques and Costa, 2014).
In times where field measurements, remote sensing and model simulations are increasingly used in combination, approaches for harmonizing the different datasets with regard to spatial resolution are required. Hence, with regard to forest biomass distributions and their temporal dynamics the following problems arise. Field measurements provide us with high-resolution information, but for limited extents, while remote sensing can cover large extents with limited resolutions. Forest models make use of both kinds of information, either as input or to validate their output against. But it is often unclear how scale affects observed and simulated distribution (Knapp et al., 2018a; Landsberg, 2003; Rödig et al., 2017; Smith and Urban, 1988). Methods are needed to account for scale effects in model–data comparisons (Rammig et al., 2018).
In this study, we worked towards an approach for transferring frequency distributions of forest biomass between different scales. Such approaches are needed to compare data with simulation output. We tested it for a tropical rainforest for which we also analyzed the distributions of biomass gain and mortality. In addition, we developed two simple forest models to analyze how they can be applied at different spatial scales. The main questions of the study were the following. (1) How do frequency distributions of forest biomass vary with spatial scale and which probability density functions describe them best? (2) How can we transfer between these distributions at different scales? (3) How can simple forest models reproduce these distributions at different scales?
Table 1Equations for converting between descriptive statistics and parameters of the gamma and lognormal distributions.

m: mean; s: standard deviation; α: gamma shape; β: gamma rate; μ: lognormal meanlog; σ: lognormal sdlog.
2.1 Field data analysis
The 50 ha forest inventory plot (ForestGEO) on Barro Colorado Island (BCI), Panama, served as a study site (Condit, 1998; Condit et al., 2019, 1995; Hubbell et al., 1999). The inventory comprised single tree measurements of all trees with a diameter at breast height ≥ 1 cm (ca. 250 000 trees), including the spatial position of each individual (Condit et al., 2012). Aboveground biomass values of each tree were calculated based on a common allometric equation for tropical trees (Chave et al., 2005). Censuses used in this study comprised data from 1985 to 2015 collected in 5-year intervals. Based on unique tree identifiers and aboveground biomass (AGB) values in successive censuses, AGB gains per tree were calculated. The inventory was aggregated for square-shaped plots with 10, 20, 50 and 100 m side lengths. Attributes calculated for each of these plots were standing AGB at each census and AGB gain, loss, and mortality for each census interval. AGB loss was the sum of AGB of all trees alive in the census at the beginning of an interval and dead in the following census. AGB mortality was AGB loss divided by the standing AGB at the beginning of the interval. Due to measurement uncertainties some trees showed negative AGB gains. At the individual tree level these negative AGB gains corresponded to 29.6 % of the positive AGB gains. When aggregating AGB gain as the sum of single tree AGB gains, the negative proportion would decrease to 12.3 % (10 m), 7.2 % (20 m), 1.5 % (50 m) and 0 % (100 m). To obtain unbiased, positive AGB gains, a correction was done at the single tree level: all negative AGB gains were set to zero and all positive AGB gains were reduced by 29.6 % to maintain the overall AGB gain. AGB gains, losses and mortalities were downscaled to annual values through division by 5 years.
For investigating the scaling behavior of AGB beyond the 50 ha plot, an airborne lidar dataset from 2009 covering the whole 15 km2 island (Lobo and Dalling, 2014) was used. AGB was predicted at 100 m resolution from mean top-of-canopy height of a 1 m resolution canopy height model using a power law regression model (Knapp et al., 2020) and aggregated at the 200, 500 and 1000 m scale. Pixels intersecting the coastline were excluded to have pure forest pixels only.
2.2 Frequency distributions
The frequency distributions of all four variables (AGB, gains, losses and mortality) were fitted using the R package “fitdistrplus” (Delignette-Muller and Dutang, 2015; R Core Team, 2022) and using two alternative probability density functions: the (1) gamma and (2) lognormal distribution function. Both distribution types can be described with two parameters, respectively. If the parameters are known, the descriptive statistics of the probability distribution (arithmetic mean and standard deviation SD) can be calculated from established equations and vice versa (Table 1). Two different methods were used to fit the probability density functions to the empirical data using (1) maximum likelihood estimation (MLE) and (2) moment matching estimation (MME). The optimization criterion for MLE is to find distribution parameters which maximize the likelihood for all observations. MME aims at finding the parameters for which the calculated moments match the empirical moments.
2.3 Scaling equations
In the following, a general equation for scaling of probability distributions is formulated (based on considerations by Dubayah et al., 1997). Let θ be a parameter of a probability distribution (SD, shape, rate, etc.). Let λ and Λ be the side lengths of plots of two different sizes and κ be a scaling exponent characterizing how the parameter θ changes between scales. The values of θ (characterizing the frequency distributions; see Table 1 for examples) at scales λ and Λ shall be called θλ and θΛ, respectively. Then θΛ can be calculated from θλ in the following way:
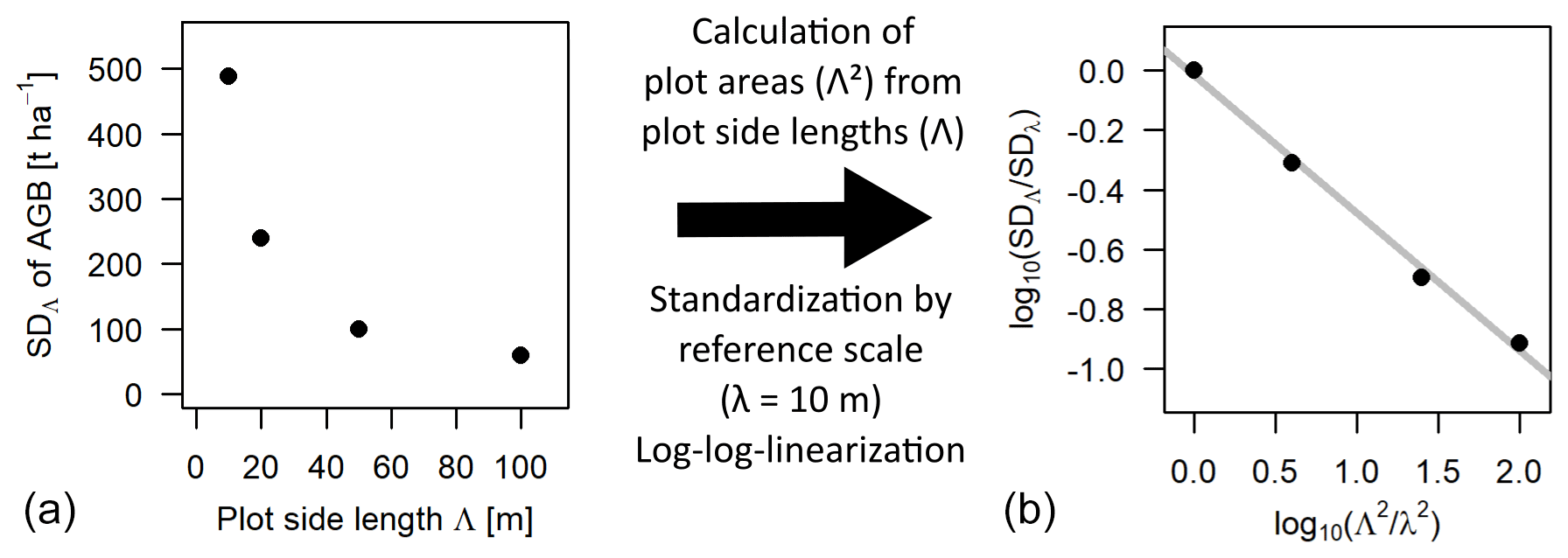
Figure 1Scale dependence of the standard deviation (SD) of the distribution of aboveground biomass (AGB). Panel (a) shows the SD values at each scale (Λ) plotted over the respective plot side lengths Λ. Panel (b) shows the scaling relationship using plot areas (Λ2 instead of Λ) and after standardizing with 10 m as the reference scale (λ), as well as plotting the values in a log–log linear way. The slope of the grey regression line is the scaling exponent κ.
If values for the parameter θ are known at different scales, κ can be derived via log–log linearization.
Hence, in log–log space, the ratio of θ at two different scales is a linear function of the ratio of areas with κ as slope. If the ratio of side length instead of areas is used, the slope of the relationship becomes 2κ. In the further analyses, the area ratio was used (Eq. 3). The focus of this study was to investigate how the scaling equation can be used to calculate the SD of forest attribute distributions at a certain target scale from a known SD at a reference scale, which will be called rescaling further on. A graphical example is given in Fig. 1 for the SD of the biomass distribution using 10 m as the reference scale. The analyses focused on the scales between 10 and 100 m, where the frequency distributions of forest biomass were considered to be primarily driven by the demographic processes growth and mortality (Smith and Urban, 1988), while at larger scales environmental gradients in heterogenous landscapes lead to deviations from the scaling relationship (lidar analysis).
2.4 Comparing frequency distributions
Two metrics were used to quantify the agreement between different probability density functions (PDFs). The first metric was the relative overlap between PDFs (OVL; Inman and Bradley, 1989), i.e., the intersection of the areas under the curves (AUCs) divided by the union of the areas under the curves of two PDFs. The R package “overlapping” was used for computation of OVL (Pastore and Calcagnì, 2019).
The second metric was the relative error of standard deviations (RESD), which we defined as the absolute difference between the SD of an estimated (e.g., rescaled or simulated) PDF1 and an observed (empirical) PDF2, normalized by the SD of the latter.
Hence, two PDFs are in close agreement, if OVL is close to one and RESD is close to zero. OVL is a good quantitative measure for visual agreement of the main bodies of the distributions. RESD, in contrast, is sensitive to the influence of the extreme values in the tails of the distributions, which is often not apparent from visual inspection of the PDFs.
2.5 Forest simulation model
A simple grid-based forest growth model was used to simulate forest dynamics over time and obtain the resulting AGB frequency distribution at mature stage. The model is based on the model suggested by Fisher et al. (2008), in which the change of AGB (B) is described as a differential equation involving an AGB gain parameter (G) and an AGB mortality parameter (M).
The analytical solution of this equation provides the average trajectory of forest biomass (over a large area) for given G and M, and the average mature AGB is .
For simulating small-scale heterogeneity including patch dynamics, Fisher et al. (2008) used a grid-based approach. Each grid cell represented 10 m × 10 m of forest area. At each simulation time step, they applied Eq. (7) to calculate the change of AGB in each cell, based on a constant AGB gain (G) and a stochastic mortality (M). A mortality event in their case meant that B was set back to zero in a patch and growth restarted from bare ground. Setting a patch back to zero is a valid assumption as long as patches are at the scale of single trees (e.g., 10 m), but using this approach at larger patch scales would rather correspond to large stand-replacing disturbances and no longer to natural tree mortality. Hence, in this study, the model was modified such that G and M both follow continuous probability distributions.
The parameters G and M were assumed to be distributed like the AGB gain and AGB mortality values derived from the field inventory. Variability in gain G represents differences in site conditions or growth rates of trees and was assumed to vary in space but stay constant in time. Hence, in the simulation, each patch was assigned a random G drawn from the AGB gain distribution, and this G was kept constant for the patch throughout the simulation run. Variability in mortality rate M reflects the stochastic nature of mortality. In a common year, only small amounts of AGB are lost per patch, due to small trees dying from competition. Large AGB losses due to dying large trees are rare events. Hence, mortality rate M was drawn randomly from the AGB mortality distribution for each patch at each time step. This simulation approach was applied at different grid cell sizes (10, 20, 50, 100 m). The total simulation area was set to 25 km2 (5 km × 5 km) to obtain smooth output distributions. The simulation time step was 1 year, and 300 years were simulated to reach a mature forest.
The AGB distributions in equilibrium state after 300 years of simulation time were analyzed by comparing them to the AGB distributions from the field inventory. The simulations were conducted with G and M coming from different probability distributions. The probability density functions could be either gamma or lognormal, fitted with either MLE or MME, and be derived from the field at either 10, 20, 50 or 100 m scale (reference scale). The scaling equation was used to rescale SD and probability density function parameters from one reference scale to the other three scales, to conduct simulations at all four scales for each of the possible input constellations (pre-model scaling). The resulting biomass distributions at the end of the simulations were aggregated from the finer to the coarser scales (post-model scaling). For evaluating the goodness of fit for the AGB distributions, OVL and RESD were calculated pairwise between each simulated (and aggregated) distribution and the empirical distribution at the respective scale. For evaluating the simulation run as a whole, the mean OVL and mean RESD over all single distributions were calculated.
2.6 Derivation of biomass distributions from theory – white shot noise
As a second approach, the AGB distribution can also be derived analytically as a function of G and M. This was done to test if such a direct calculation of the biomass distribution is possible and whether this can be applied at multiple scales as well. The approach assumes M to be white shot noise. This type of noise is used in environmental modeling to describe pulsed processes that occur at irregular time intervals (e.g., rainfall at daily resolution). White shot noise assumes pulse intensities and interval lengths both to be exponentially distributed and is, therefore, characterized by two parameters: the mean intensity and the mean occurrence probability.
It was assumed that the AGB mortality at small spatial resolution (10 m × 10 m) can be described by white shot noise. Since observed AGB mortality is never exactly zero, due to small trees dying every year, the mean occurrence probability can be assumed as one. The mean intensity then directly corresponds to the mean AGB mortality . It can be shown that under this white shot noise assumption the AGB for a given G and value follows a gamma distribution of the following form (Ridolfi et al., 2011):
For a range of k different G values, which represent the spatial heterogeneity in growth rates and which themselves follow a gamma or lognormal distribution, AGB of a forest landscape can be described by a mixture of gamma distributions.
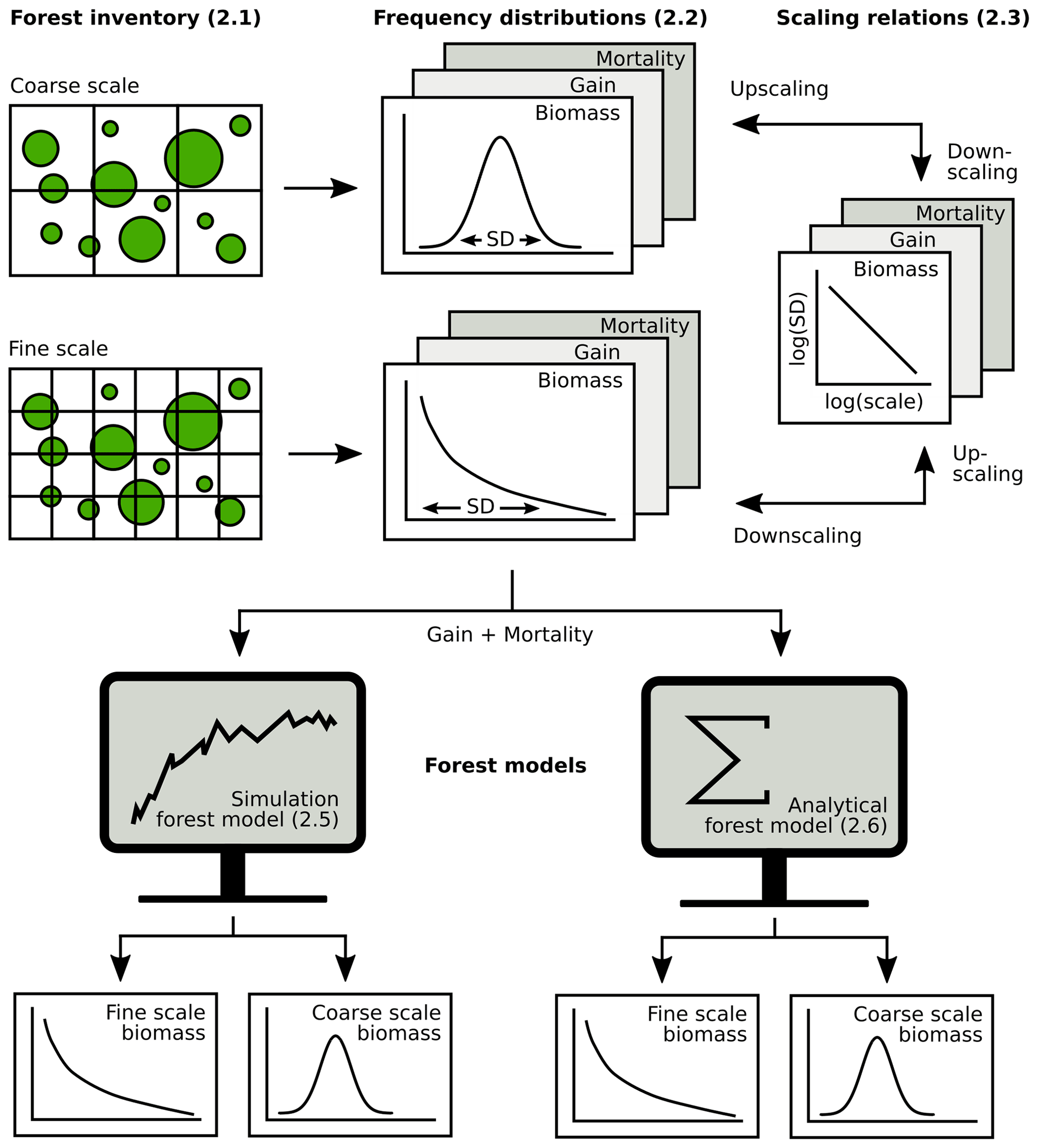
Figure 2Overview of the analysis (section numbers in brackets). Forest inventory data were aggregated at different spatial scales to obtain frequency distributions of biomass, gain and mortality. Next, scaling relationships were established for up- and downscaling of frequency distributions. Then, it was tested how biomass distributions at different scales can be derived from gain and mortality using either simulations or an analytical forest model.
The exponential distribution of mortality intensity, as assumed by the theory, has a monotonically decreasing probability density function. Such probability distributions are usually only observed for mortality at small scales, while mortality follows unimodal distributions at larger scales (see, e.g., Fig. 4). Hence, for deriving AGB distributions from the white shot noise theory at larger scales, there are different options, of which two were investigated here. (1) The simplest one is to apply the white shot noise directly at all scales, ignoring the actual shape of the mortality distribution. (2) Alternatively, white shot noise was applied to derive the AGB distribution only at the 10 m scale, and the SD of this distribution was rescaled in a post-model scaling using Eq. (1) and an empirically derived scaling exponent κ. The rescaled SD was used to approximate the AGB distribution with a lognormal distribution. The main steps in the analysis, from inventory data to frequency distributions to scaling relationships and forest model applications at different spatial scales, are summarized in Fig. 2.
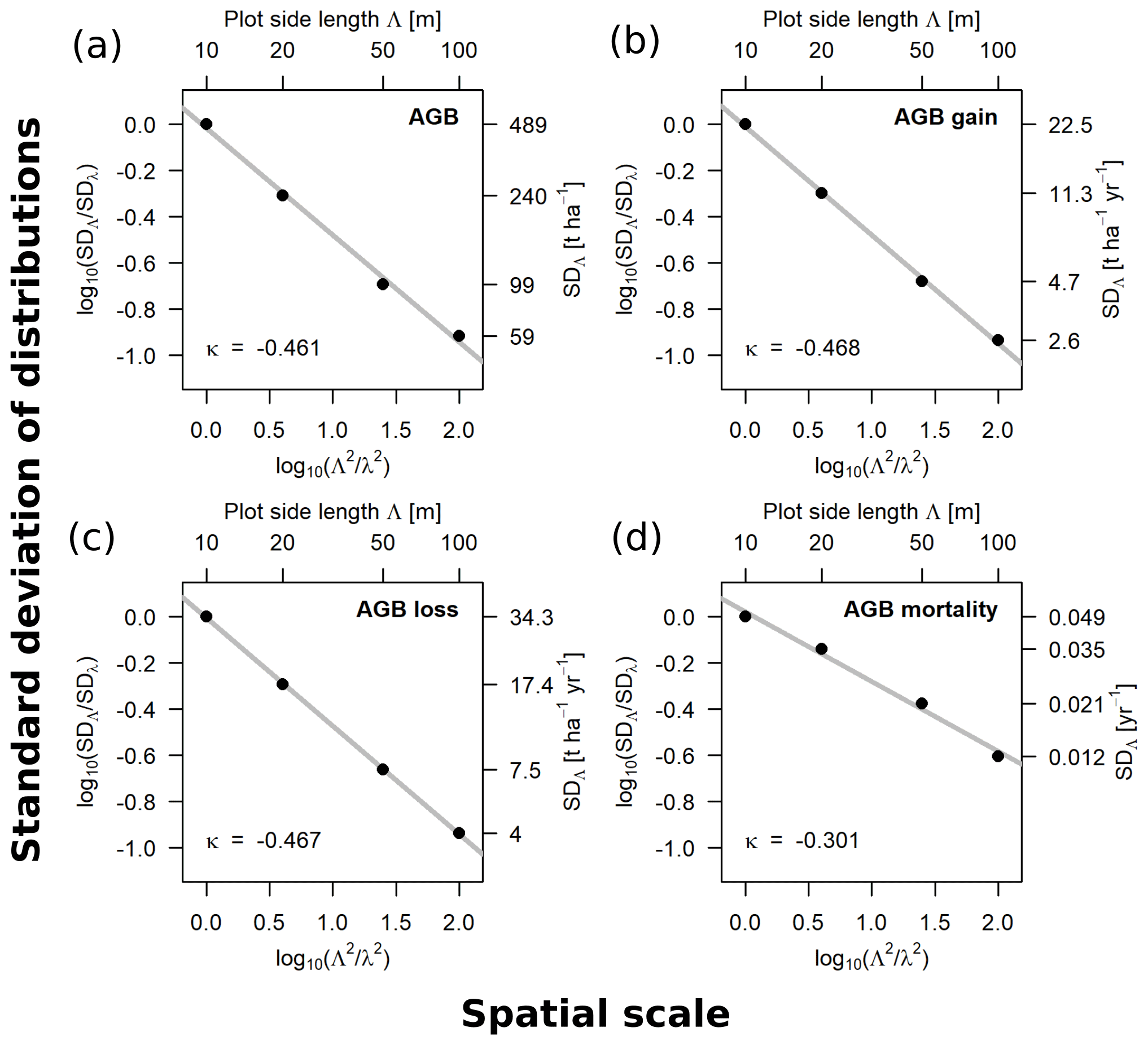
Figure 3Scaling relationships for aboveground biomass (AGB) (a), gain (b), loss (c) and mortality (d), derived from the standard deviations (SD) of the empirical distributions. Fitted slopes represent the scaling exponents (κ in Eqs. 1–3). Plotted are the log 10-transformed ratios of the SDs over the log 10-transformed ratios of plot areas, with 10 m being the reference scale (λ). The top axis shows the plot side lengths (Λ), and the right axis shows the values of the SD for each scale, respectively.
3.1 Scaling relationships of standard deviations of forest attribute distributions
The relationships between spatial scale (plot area) and standard deviations of the frequency distributions were derived for AGB, gain, loss and mortality within the 50 ha forest plot for the scale range from 10 to 100 m. The scaling exponents for AGB (κ = −0.461), AGB gain (κ = −0.468) and AGB loss (κ = −0.467) were similar, whereas it was different for AGB mortality (κ = −0.301). The log–log linear relationships are shown in Fig. 3.
Beyond the 50 ha plot, AGB was analyzed via a lidar-derived AGB map (Fig. S4 in the Supplement). The lidar analysis demonstrates that at the 100 m scale the inventory-based SD of the AGB distribution within the 50 ha plot (59 t ha−1) matches the lidar-based SD of the whole island (59 t ha−1), while the lidar-based SD within the 50 ha plot was somewhat smaller (49 t ha−1). At the 200 m scale, the lidar-based SD within the 50 ha plot (29 t ha−1) conforms the scaling relationship. At the 500 m scale, it is somewhat higher than expected (20 t ha−1), but at this large pixel size a strict spatial overlap with the 50 ha plot is not possible, and the area contributing to this value is 150 ha (6 pixels). The island-wide SDs at 200 m (47 t ha−1) and 500 m (37 t ha−1) resolution are higher than predicted by the scaling relationship. This additional variability can be explained by the larger extent and possible autocorrelation in the spatial distribution of biomass across the island. At 1000 m scale, the island-wide SD (10 t ha−1) is close to the scaling relationship, which can be explained by the fact that only 5 km2 in the center of the island, around the 50 ha plot, were analyzed while all square kilometers intersecting the shoreline were excluded.
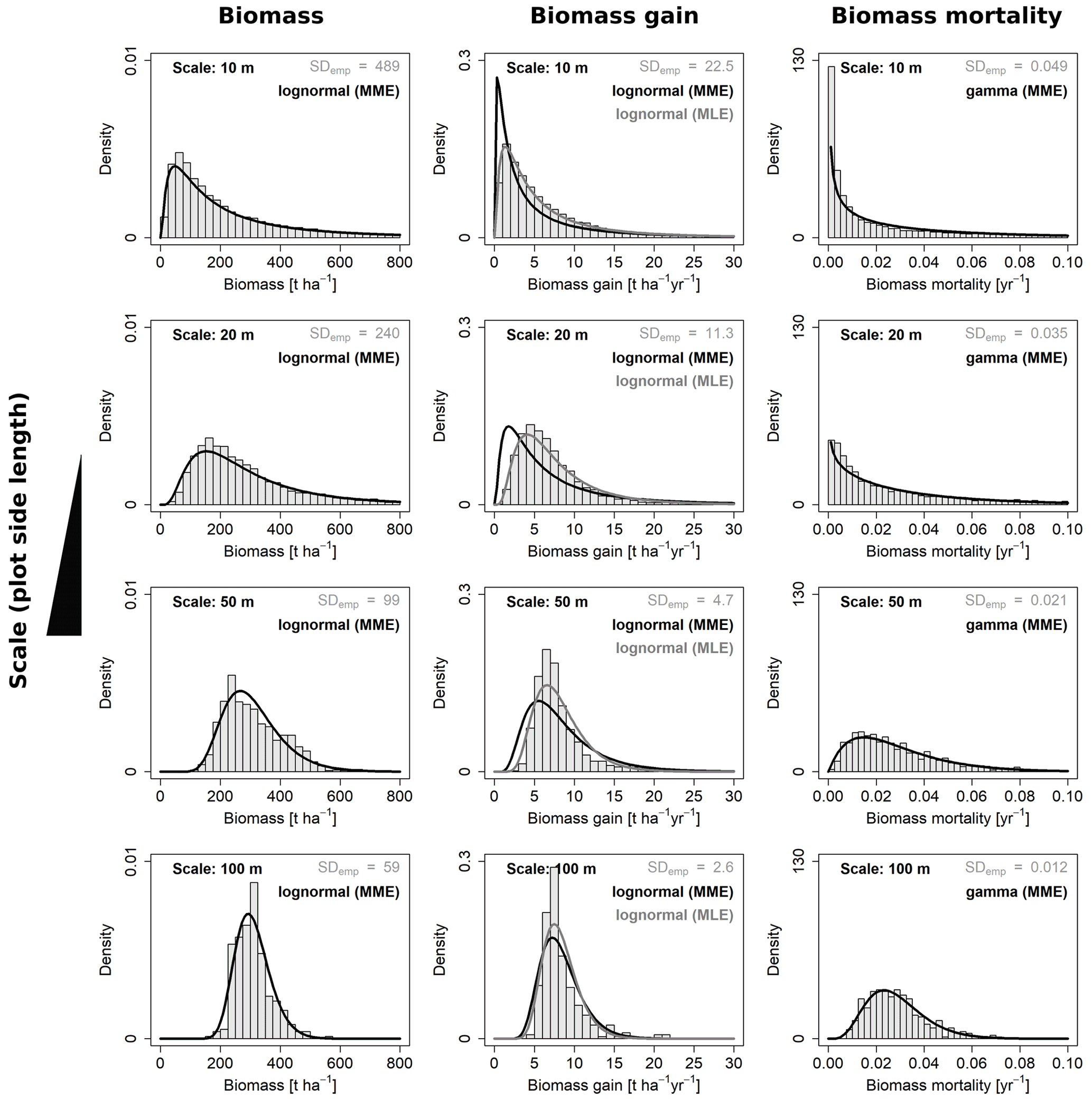
Figure 4Frequency distributions for aboveground biomass and its gain and mortality analyzed at four different scales. Shown are the best-fitting probability density functions for each of the three variables at each scale and the respective empirical distributions from the field (grey histograms). For AGB gain, each of the two fitting methods (MME and MLE) were superior regarding one criterion; hence, curves are plotted for both.
3.2 Fitted distribution functions
For each of the four variables of interest (AGB, gain, loss and mortality) the best-describing distribution function was identified, by fitting either lognormal or gamma distribution functions with the maximum likelihood or moment matching method. Selected fits for all four spatial scales (10, 20, 50 and 100 m) are shown in Fig. 4.

Figure 5Downscaling the aboveground biomass distribution from the 100 m scale to three other scales. Black curves represent the downscaled (down) lognormal probability density functions and grey histograms the empirical (emp) distributions from the field. Standard deviations are given for each distribution.
From each fit at one scale (reference scale) the expected SDs at all other scales (target scales) were calculated using the scaling equation (Eq. 1) with the empirically derived scaling exponents κ, respectively. From these rescaled SDs the function parameters and probability density curves were derived using the equations in Table 1. An example for downscaling AGB from 100 m to the three smaller scales is shown in Fig. 5.
Table 2Goodness-of-fit criteria values for the different distribution functions and fitting methods for all four variables. Best-matching distributions, i.e., those with the largest mean overlap (OVL) and smallest mean relative error of standard deviation (RESD), are highlighted in bold font. Mean hereby refers to the mean over all four spatial scales (10, 20, 50, 100 m).
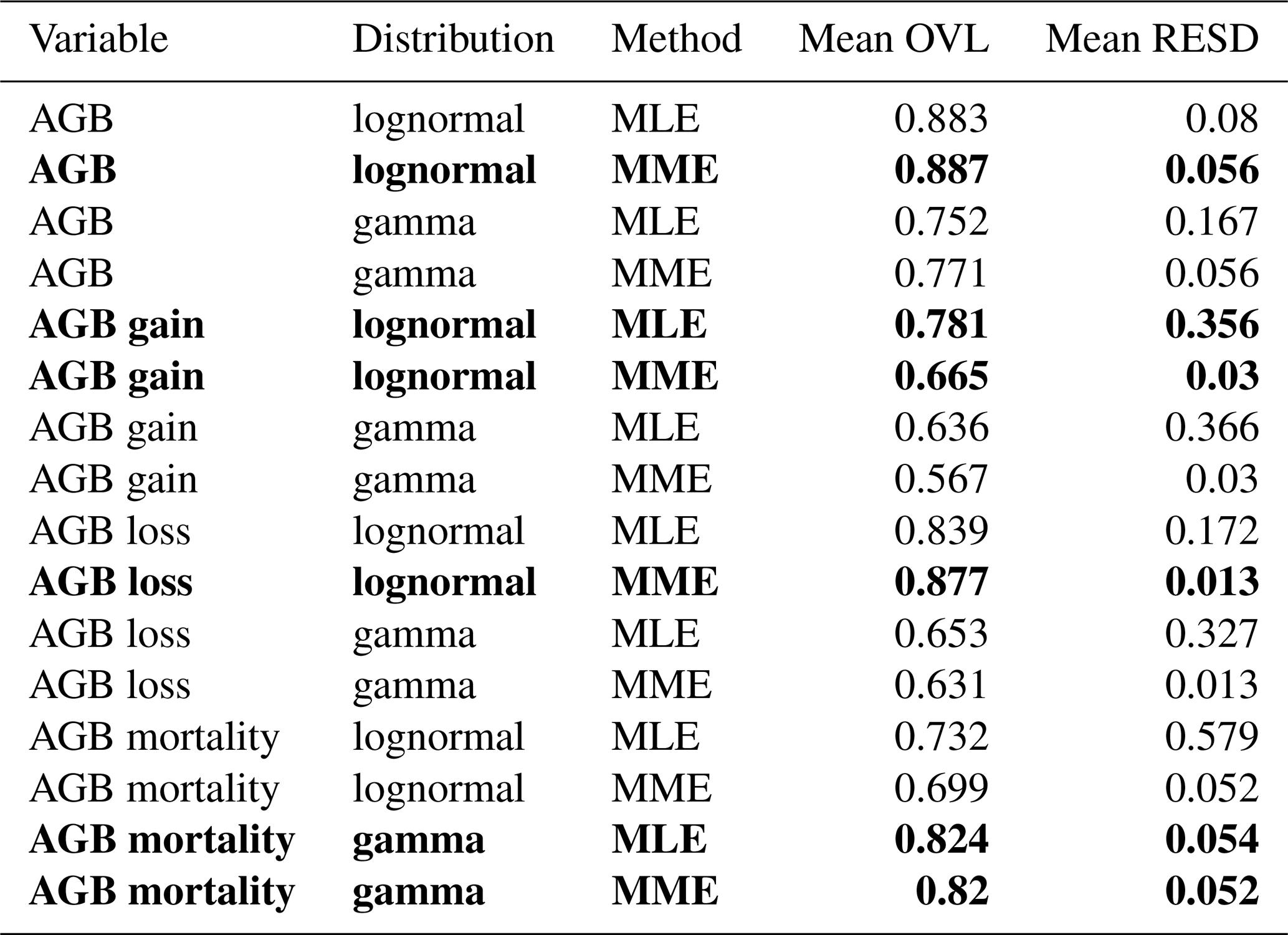
AGB: aboveground biomass; MLE: maximum likelihood estimation; MME: moment matching estimation.
To identify the best-fitting distribution and method for each variable, i.e., the most consistent across scales, two criteria were used: (1) the mean overlaps (OVL) between empirical and fitted probability densities and (2) the mean relative error of the SD (RESD). Mean in both cases refers to mean over all four spatial scales. Table 2 lists the values for these criteria for all distributions and methods, and Fig. S1 shows the best-matching distribution function for each variable at all spatial scales.
For three of the four variables, there was a clear best fit according to the criteria (Table 2): AGB (lognormal MME), AGB loss (lognormal, MME) and AGB mortality (gamma, MLE or MME equally good). For AGB gain, however, the best-fitting lognormal distribution functions derived from the MLE and MME methods were considerably different from each other (Fig. 4). While the MLE fits had the higher overlap with the field data, they produced large errors when used for calculating the SD at the other scales (large mean RESD). Consistent rescaling of the SD of AGB gain was only achieved when using the MME fit, despite the weaker overlap of these distributions with the field data. Comparing Figs. S1b with S2a illustrates the differences of the methods for AGB gain in detail, and Fig. S2b and c illustrates the RESD for both.
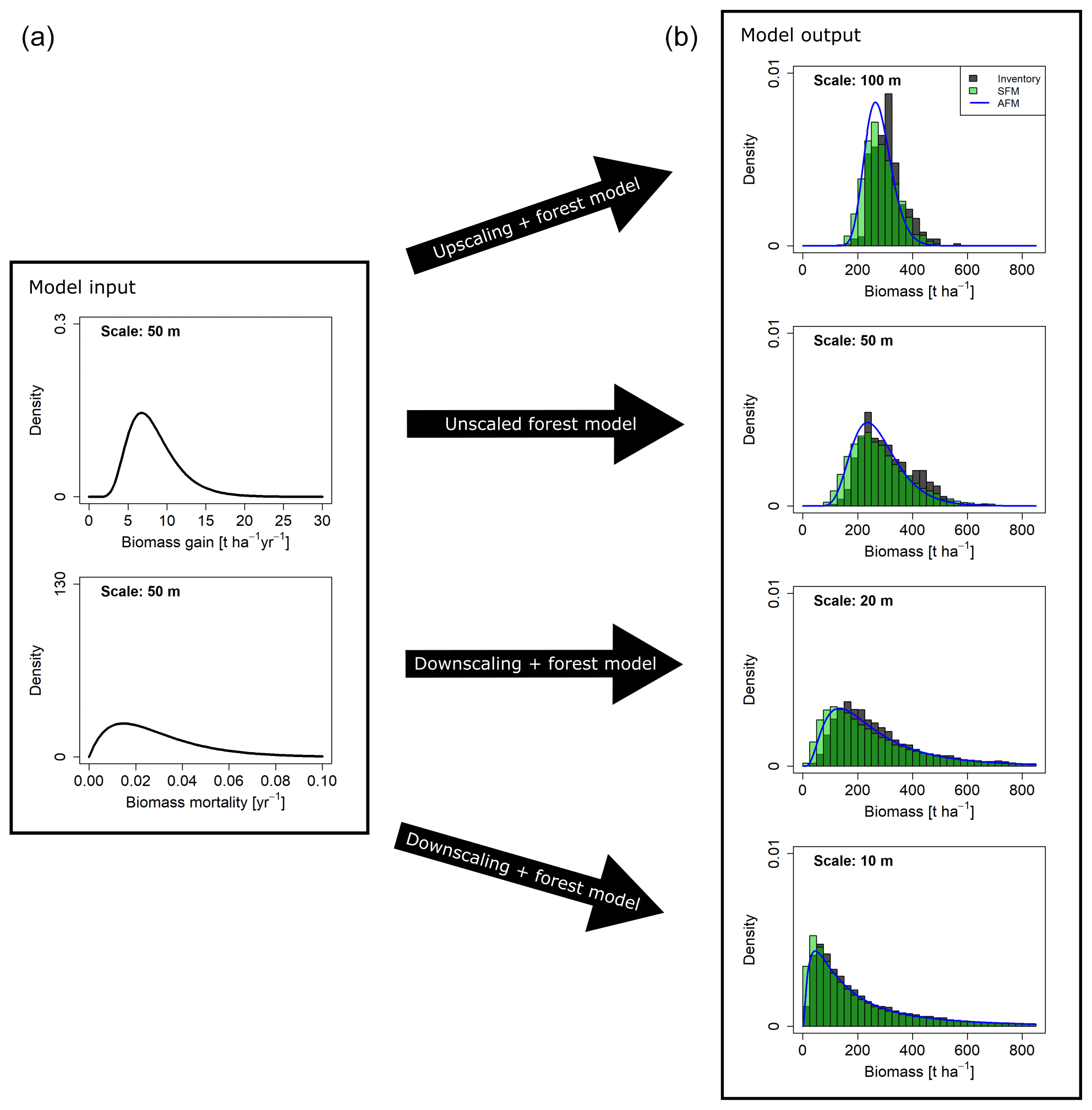
Figure 6Biomass distributions at different spatial scales resulting from different approaches. (a) Curves show the gain (G) and mortality (M) distributions used as input. (b) Dark grey histograms show the empirical distributions from the field inventory. Green histograms show the simulation results from the stochastic forest model (SFM). All SFM simulations were driven by the two probability density functions for AGB gain and mortality derived at the 50 m scale (a), which were rescaled for simulations at the 10, 20 and 100 m scale. Blue lines show the AGB distribution functions calculated with the analytical forest model (AFM).
3.3 Simulation results
Simulations with the stochastic forest model were conducted at the scales of 10, 20, 50 and 100 m. The resulting biomass distributions at the end of the simulations were aggregated to the coarser scales, respectively. By testing a range of 64 different combinations of input distribution functions (G and M) and reference scales (at which these distributions were derived), well-performing combinations were identified based on the goodness-of-fit criteria OVL and RESD (Table S1, Figs. S5–S8 in the Supplement). It was found that simulated AGB distributions matched the field distributions particularly well when G and M distributions were derived at the 50 m scale (reference scale). Figure 6 shows the results for the unscaled case at the 50 m scale and the rescaled distributions at the other scales. The distribution functions identified as best for gain and mortality, based on the field data analyses (Table 2), were also among the best for G and M, based on the simulation analyses (Table S1). If G was modeled as a lognormal distribution (MLE fit at the 50 m scale) and M as gamma distribution (MME fit at the 50 m scale), rescaling and subsequent stochastic simulations resulted in consistent AGB distributions at all scales (Fig. 6).
It was found that several versions of the stochastic forest model simulations could produce realistic AGB distributions across scales (Figs. S5–S8 provide details about the different reference, simulation and aggregation scales). The best-matching AGB distributions were observed for simulations using 50 m as the reference scale (mean OVL = 77 %, mean RESD = 9 %, Table S2). At the 20 m reference scale, the largest observed mean OVL was 75 % and the smallest observed mean RESD was 12 % (although the two were from different simulations, Table S1). At the 10 m reference scale, the best mean OVL was the smallest among all reference scales (65 %), while the best mean RESD was good (13 %, Table S1). At the 100 m reference scale, the best mean OVL was better (70 %), but the best mean RESD was far higher than for any other reference scale (34 %, Table S2).
One consistent finding across scales was that simulations using lognormal distributions and the MLE fitting method were more abundant among the best simulations than the ones using gamma distributions and the MME method. In fact, at any reference scale, the approach which used only lognormal and MLE for modeling G and M ranked among the best simulations. Approaches using gamma or MME for more than one distribution (G and M) never ranked among the best (Tables S1 and S2). Examples for simulated AGB distributions at all scales (with OVL and RESD values), when starting from different reference scales, are shown in Figs. S5 to S8.
3.4 White shot noise calculations
As an alternative to the simulations with the stochastic forest model, the calculation of AGB distributions from an analytical forest model was tested. The mortality was assumed as white shot noise; i.e., only its total mean ( = 0.0285) was required. Since the assumption of white shot noise mortality was considered most appropriate at the finest scale, the probability density function (gamma mixture distribution) was derived at the 10 m scale and upscaled with the scaling relationship, using a lognormal distribution as approximation for the mixture distribution. The distributions resulting from the analytical model (blue lines in Fig. 6) are close to the field data and the simulation model outputs. A quantitative analysis based on OVL and RESD is presented in Fig. S9, which also shows how a direct application of white shot noise at larger scales leads to deviations in the AGB distributions.
It was shown how the distributions of forest biomass, gain and mortality vary with spatial scale. While distributions at a small scale show large SDs due to the large heterogeneity between patches, SDs decrease due to spatial averaging and the loss of dispersion variance at larger scales. Methods for fitting the distributions best across all scales and transferring their standard deviations between scales were identified. It was shown how scaling was necessary to reproduce the biomass distributions with two simple forest models.
4.1 Scaling of forest attributes
For transferring between the distributions at the different spatial scales, empirical scaling coefficients were derived. The exponents for scaling the SDs of the distributions were very similar for the extensive properties aboveground biomass stocks, gains and losses (all between −0.46 and −0.47), while the one for the intensive property mortality was considerably different (−0.3). Theory states that the SD of an independent identically distributed random variable changes with the square root of the area ratio between scales, i.e., a scaling exponent of −0.5. The slight deviation from −0.5 is an indication of spatial structure in the data, i.e., that grid cells are not fully independent.
The different scaling exponent of mortality is likely caused by the fact that mortality is a ratio of AGB loss and stock. This characteristic of being a ratio between two extensive properties makes mortality a non-additive intensive property. When aggregating mortality values from smaller to larger scales, the weighted mean has to be used, with AGB as a weighting variable. It further has the consequence that the mean mortality over the whole 50 ha plot is not the same when calculated at different resolutions. The mean mortalities of all 10 and 20 m patches were 0.035 and 0.031 yr−1, respectively, and only stabilized above the 50 m scale at 0.029 yr−1 (Fig. S1d). All the other attributes in this analysis were additive and had a stable mean across scales.
The lidar-based scaling of AGB beyond the 50 ha plot and across the whole island showed that the SD of the distribution decreases further but no longer strictly follows the scaling relationship from within the plot. With increasing scale, the spatial pattern of AGB distribution is possibly increasingly dominated by environmental factors, which in the case of Barro Colorado Island are topographic slope, soil properties and forest age due to disturbance history (Mascaro et al., 2011). These covariates may alter the slopes of scaling relationships. Additionally, the spatial coverages of the AGB maps were different, due to exclusion of pixels intersecting the coastline, which led to a small sample size of only 5 pixels at the largest analyzed scale (1000 m). Further analyses could investigate the scaling in heterogenous landscapes, e.g., based on synthetically generated landscapes with spatial autocorrelation or based on regional or global remote sensing products. With such approaches, an invariability–area relationship has been suggested (Wang et al., 2017).
4.2 The choice of the proper distribution fit
Parametric probability density functions represent idealized models to which real empirical data may either conform well or not. To fit the parameters of distribution functions to match the data, different target criteria can be formulated, such as maximizing the likelihood of all observed values (maximum likelihood estimation) or matching the moments of the empirical data (moment matching estimation). Thus, the choice of the probability density function (lognormal or gamma) and fitting method (MLE or MME) affects the estimated parameters and hence SD. It was found that for the majority of forest attributes (AGB, loss, mortality) a best-fitting distribution function, which was also consistent across scales, could be identified. The example of AGB gain, however, demonstrated that different methods for distribution fitting can have different outcomes and that neither lognormal nor gamma distribution functions matched the empirical distribution well across scales. Maximum likelihood estimation usually results in high overlaps of empirical and fitted distributions. However, it does not necessarily lead to a good match of the moments of empirical and fitted distribution. Because of this, SDs of the fitted probability density functions deviated from the empirical SDs, and they deviated differently at each scale. This led to inconsistent probability density functions when applying the scaling relationship for rescaling of the SDs. With moment matching estimation, SDs were correctly estimated at all scales and could consistently be rescaled. The price for the matching moments were lower overlaps between empirical and fitted distributions.
4.3 Scaling of forest models
It was found that both forest models could reproduce the biomass distributions observed in the field at different spatial scales. For the simulation model, it proved to be best to choose an intermediate reference scale (50 m) for deriving the information about gain and mortality and using a pre-model scaling to drive simulations at the other scales. In this way, the simulation model could reproduce the biomass distributions at the four simulation resolutions.
Choosing the lower (10 m) or upper (100 m) end of the scale range as the reference scale led to less agreement of the simulated and the field distributions. An explanation for this might be that more bias is introduced when rescaling over a longer scale range rather than from an intermediate scale which is closer to both ends. Additionally, using the small scales as the reference scale is probably problematic, because mean mortality is positively biased at these scales, due to the non-additivity of mortality discussed earlier. Simulations with the 100 m reference scale resulted in too large SDs of the distributions across all scales, which can be explained by the fact that the AGB gain distribution underlying the simulations was most difficult to fit and rescale from the 100 m reference scale (Fig. S2a). The reason why this was the case remains speculative but could be explained by the effect that the heterogeneity caused by the forest structure itself (tree positions and sizes) becomes comparatively small at the 100 m scale, such that underlying landscape gradients (topography, soil conditions) make the distributions wider than expected from forest dynamics alone (Mascaro et al., 2011).
The simulation model produced the most consistent results when the input distributions were fitted using maximum likelihood estimation. This was unexpected, considering the earlier finding that moment matching estimation allows for more consistent scaling of SDs based on the field data analysis. An explanation could be that, while moment matching fits are more accurate with regard to the SD, maximum likelihood fits are overall “closer” to the real distributions (higher distribution overlap). The deviation of moment matching fits from the real distributions (smaller distribution overlap) may pose a problem in simulations where these distributions are used for drawing random numbers many times. Maximum likelihood fits might be more appropriate in this case, especially if they were obtained at intermediate scales, from where distribution parameters, like SD, can be rescaled in both directions without causing much bias.
A fast solution for approximating the AGB distribution of the forest from the AGB gain and mortality distributions was given with the analytical model using white shot noise. This approach does not require iterative simulation over time. However, it requires the assumption that mortality follows an exponential distribution, which is a simplification. At the 10 m scale the mortality distribution is at least more similar to an exponential distribution than at the larger scales. Indeed, assuming white shot noise directly at large scales did not approximate the AGB distributions well. However, assuming white shot noise only at the 10 m scale and applying a post-model upscaling enabled a good approximation of the AGB distribution across all scales without running a simulation. This is an example of an inherent scale of a model; i.e., the method white shot noise cannot be applied at arbitrary scales, but scaling helps to apply the process at its inherent scale and nevertheless produce results at other scales.
Thus, it was found that the analytical model worked best when applied at the 10 m scale, where the assumption of a white shot noise mortality was the most justified, while the simulation model worked best with parameters derived at the 50 m scale, from where the least bias was introduced when rescaling the parameters. Such optimal scales always depend on the considered processes and need to be identified in every model.
4.4 Perspectives
Quantifying the carbon budget of forests is one of the most important reasons for combining forest models with remote sensing (Shugart et al., 2015). Increasingly, the two techniques are being combined for this purpose, either using remote sensing information for model parameterization, initialization, calibration, or validation or using model information for remote sensing interpretation (Plummer, 2000). In this context, it is important that remote sensing products and models describe variables at the same spatial resolution. In case they are operating at different resolutions, appropriate scaling of the variables needs to be conducted.
Descriptive statistics of distributions and relationships between variables may critically depend on the chosen aggregation approach, a phenomenon long known as the modifiable areal unit problem (MAUP; Openshaw, 1983). The MAUP has been divided into the zoning and scaling problem. While the former refers to the problem of where to draw the borders between aggregation units, the latter refers to the size of the aggregation units, which is particularly relevant for regularly gridded data and grid-based simulation models (Wong, 2008). It can only be avoided by identifying basic ecological meaningful entities (trees in forests) and conducting analyses and model simulations exclusively at their level (Jelinski and Wu, 1996). This, however, would mean to apply individual-based models at any scale, which is not feasible for computational limitations. Thus, we rely on scaling if we want to model forest dynamics over larger areas.
Based on the results of this study, we advise to consider the spatial scale in model–data comparisons when dealing with aggregated quantities such as biomass and carbon fluxes. If possible, frequency distributions should be derived and compared at several scales. Scaling relationships like the ones identified in this study may help to transfer distribution parameters between scales.
Models often have inherent scales; i.e., they represent certain processes on a grid. This is not exclusive to simple forest models, like the one used in this study, but also individual-based forest models, which simulate many processes and environmental drivers like mortality, disturbances, climate and soil using grid cells. We have shown that for reproducing the correct output distributions (biomass) at different scales, the input distributions (gain, mortality), i.e., the model parameters, had to be rescaled accordingly.
4.5 Outlook
For a deeper understanding of the scaling coefficients of the different processes at the small scales below 1 ha, further analyses should look into the spatial patterns and mechanisms at the individual level, i.e., tree positions and their size and biomass distribution. Methods such as point process models (Lister and Leites, 2018), spatially explicit individual-based forest models (Maréchaux and Chave, 2017) or network analysis (Schmid et al., 2020) can improve our understanding of how patterns at the individual level shape the scaling at aggregated levels. Beyond the 1 ha scale, where environmental gradients determine the distributions, their influence on scaling can be investigated with a combination of forest landscape models (He, 2008), high-resolution and multitemporal remote sensing (Dalponte et al., 2019), and machine-learning-based surrogate models (Rammer and Seidl, 2019).
Several applications become possible if the scaling of biomass distributions and their relation to growth and mortality are well understood. For example, Williams et al. (2013) used this to estimate disturbance intensities from remotely sensed biomass distributions using a forest model. A detailed understanding how canopy height changes at a certain scale related to biomass changes can allow for a direct quantification of the net forest carbon changes from remote sensing (Hiltner et al., 2022; Knapp et al., 2018b). Knowledge about the scaling of forest attribute distributions is also required for downscaling of gridded maps (i.e., super-resolution), for purposes such as data assimilation (Hill et al., 2011; Rödig et al., 2017) or pixel-to-point comparisons between models and field data (Rammig et al., 2018).
The study has shown how the distributions of variables, which are important for the carbon budgets of forests, vary with spatial scale. Biomass and its gain, loss and mortality could all be described with parametric distribution functions (gamma or lognormal) of varying spread at different spatial resolutions. The spread of these distributions, in the form of standard deviations, was described as a function of scale using power law relationships. Scaling exponents for the extensive properties biomass and gain were close to the expected value of −0.5 but not precisely, which indicates subtle spatial patterns in the data, while the scaling exponent of the intensive property mortality was quite different. The scaling relationships allowed for successful up- and downscaling of the respective distribution functions in the range of scales between 10 and 100 m. Beyond this range, a comparison with lidar data showed deviations from the scaling relationship. Thus, we conclude that the distributions in the considered range are dominated by the process heterogeneity (forest dynamics), while, above, landscape heterogeneity plays an increasing role. Forest models need to account for this landscape heterogeneity when being applied at coarser scales. The application of up- and downscaling for forest models was demonstrated. It was shown how the scaling relationships can be used to reproduce biomass frequency distributions with two different simple forest models across scales using measured parameters about gain and mortality from a single reference scale as input. The two models differed with regard to which scale was the best reference scale. Optimal scales always depend on the considered processes and need to be identified in every model. Scaling approaches will hopefully facilitate the comparison and trans-scale integration of data about forest dynamics from various sources of information, such as forest inventory, remote sensing and modeling.
A publicly available forest inventory dataset was analyzed in this study. It can be found on Dryad: https://doi.org/10.15146/5xcp-0d46 (Condit et al., 2019). The BCI lidar dataset is available from the Office of Bioinformatics of the Smithsonian Tropical Research Institute upon request. The R code for the analyses and simulations is available upon request from the corresponding author.
The supplement related to this article is available online at: https://doi.org/10.5194/bg-19-4929-2022-supplement.
NK, SA and AH conceptualized the research and developed the methodology; NK performed analyses and simulations and wrote the original draft; NK, SA and AH contributed to writing, reviewing and editing.
The contact author has declared that none of the authors has any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
We would like to thank the Smithsonian Tropical Research Institute for providing the census data for BCI. The BCI forest dynamics research project was made possible by National Science Foundation grants to Stephen P. Hubbell (DEB-0640386, DEB-0425651, DEB-0346488, DEB-0129874, DEB-00753102, DEB-9909347, DEB-9615226, DEB-9615226, DEB-9405933, DEB-9221033, DEB-9100058, DEB-8906869, DEB-8605042, DEB-8206992, and DEB-7922197), support from the Center for Tropical Forest Science, the Smithsonian Tropical Research Institute, the John D. and Catherine T. MacArthur Foundation, the Mellon Foundation, the Small World Institute Fund, and numerous private individuals, as well as through the hard work of over 100 people from 10 countries over the past two decades. The plot project is part of the Forest Global Earth Observatory (ForestGEO), a global network of large-scale demographic tree plots. We thank James W. Dalling for providing the lidar data from BCI.
This research has been supported by the Helmholtz Association (grant no. ZT-I-0010) in the Reduced Complexity Models project (RedMod).
The article processing charges for this open-access publication were covered by the Helmholtz Centre for Environmental Research – UFZ.
This paper was edited by Sebastiaan Luyssaert and reviewed by two anonymous referees.
Asner, G. P., Mascaro, J., Anderson, C., Knapp, D. E., Martin, R. E., Kennedy-Bowdoin, T., van Breugel, M., Davies, S., Hall, J. S., Muller-Landau, H. C., Potvin, C., Sousa, W., Wright, J., and Bermingham, E.: High-fidelity national carbon mapping for resource management and REDD+, Carbon Balance Manag., 8, 1–14, https://doi.org/10.1186/1750-0680-8-7, 2013.
Brienen, R. J. W., Phillips, O. L., Feldpausch, T. R., Gloor, E., Baker, T. R., Lloyd, J., Lopez-Gonzalez, G., Monteagudo-Mendoza, A., Malhi, Y., Lewis, S. L., Vásquez Martinez, R., Alexiades, M., Álvarez Dávila, E., Alvarez-Loayza, P., Andrade, A., Aragão, L. E. O. C., Araujo-Murakami, A., Arets, E. J. M. M., Arroyo, L., Aymard C., G. A., Bánki, O. S., Baraloto, C., Barroso, J., Bonal, D., Boot, R. G. A., Camargo, J. L. C., Castilho, C. V., Chama, V., Chao, K. J., Chave, J., Comiskey, J. A., Cornejo Valverde, F., da Costa, L., de Oliveira, E. A., Di Fiore, A., Erwin, T. L., Fauset, S., Forsthofer, M., Galbraith, D. R., Grahame, E. S., Groot, N., Hérault, B., Higuchi, N., Honorio Coronado, E. N., Keeling, H., Killeen, T. J., Laurance, W. F., Laurance, S., Licona, J., Magnussen, W. E., Marimon, B. S., Marimon-Junior, B. H., Mendoza, C., Neill, D. A., Nogueira, E. M., Núñez, P., Pallqui Camacho, N. C., Parada, A., Pardo-Molina, G., Peacock, J., Peña-Claros, M., Pickavance, G. C., Pitman, N. C. A., Poorter, L., Prieto, A., Quesada, C. A., Ramírez, F., Ramírez-Angulo, H., Restrepo, Z., Roopsind, A., Rudas, A., Salomão, R. P., Schwarz, M., Silva, N., Silva-Espejo, J. E., Silveira, M., Stropp, J., Talbot, J., ter Steege, H., Teran-Aguilar, J., Terborgh, J., Thomas-Caesar, R., Toledo, M., Torello-Raventos, M., Umetsu, R. K., van der Heijden, G. M. F., van der Hout, P., Guimarães Vieira, I. C., Vieira, S. A., Vilanova, E., Vos, V. A., and Zagt, R. J.: Long-term decline of the Amazon carbon sink, Nature, 519, 344–348, https://doi.org/10.1038/nature14283, 2015.
Chave, J., Condit, R., Lao, S., Caspersen, J. P., Foster, R. B., and Hubbell, S. P.: Spatial and temporal variation of biomass in a tropical forest: results from a large census plot in Panama, J. Ecol., 91, 240–252, https://doi.org/10.1046/j.1365-2745.2003.00757.x, 2003.
Chave, J., Andalo, C., Brown, S., and Cairns, M.: Tree allometry and improved estimation of carbon stocks and balance in tropical forests, Oecologia, 145, 87–99, https://doi.org/10.1007/s00442-005-0100-x, 2005.
Condit, R.: Tropical forest census plots, Springer-Verlag and R. G. Landes Company, Berlin, Germany and George Town, Texas, 211 pp., https://doi.org/10.1007/978-3-662-03664-8, 1998.
Condit, R., Hubbell, S., and Foster, R.: Mortality rates of 205 neotropical tree and shrub species and the impact of a severe drought, Ecol. Monogr., 65, 419–439, https://doi.org/10.2307/2963497, 1995.
Condit, R., Lao, S., Pérez, R., Dolins, S. B., Foster, R. B., and Hubbell, S. P.: Barro Colorado Forest Census Plot Data, Center for Tropical Forest Science Databases, https://repository.si.edu/handle/10088/20925 (last access: 12 October 2022), 2012.
Condit, R., Pérez, R., Aguilar, S., Lao, S., Foster, R., and Hubbell, S.: Complete data from the Barro Colorado 50-ha plot: 423617 trees, 35 years, v3, Dryad [data set], https://doi.org/10.15146/5xcp-0d46, 2019.
Dalponte, M., Jucker, T., Liu, S., Frizzera, L., and Gianelle, D.: Characterizing forest carbon dynamics using multi-temporal lidar data, Remote Sens. Environ., 224, 412–420, https://doi.org/10.1016/j.rse.2019.02.018, 2019.
Delignette-Muller, M. L. and Dutang, C.: fitdistrplus: An R package for fitting distributions, J. Stat. Softw., 64, 1–34, https://doi.org/10.18637/jss.v064.i04, 2015.
Dubayah, R., Wood, E. F., and Lavallee, D.: Multiscaling analysis in distributed modeling and remote sensing: an application using soil moisture, in: Scale Remote Sensing and GIS, edited by: Quattrochi, D. A. and Goodchild, M. F., 432, ISBN 9781566701044, 1997.
Fischer, R., Bohn, F., Dantas de Paula, M., Dislich, C., Groeneveld, J., Gutiérrez, A. G., Kazmierczak, M., Knapp, N., Lehmann, S., Paulick, S., Pütz, S., Rödig, E., Taubert, F., Köhler, P., and Huth, A.: Lessons learned from applying a forest gap model to understand ecosystem and carbon dynamics of complex tropical forests, Ecol. Model., 326, 124–133, https://doi.org/10.1016/j.ecolmodel.2015.11.018, 2016.
Fisher, J. I., Hurtt, G. C., Thomas, R. Q., and Chambers, J. Q.: Clustered disturbances lead to bias in large-scale estimates based on forest sample plots, Ecol. Lett., 11, 554–563, https://doi.org/10.1111/j.1461-0248.2008.01169.x, 2008.
Fritsch, M., Lischke, H., and Meyer, K. M.: Scaling methods in ecological modelling, Methods Ecol. Evol., 11, 1368–1378, https://doi.org/10.1111/2041-210X.13466, 2020.
Hansen, M. C., Potapov, P. V., Moore, R., Hancher, M., Turubanova, S. a, Tyukavina, a, Thau, D., Stehman, S. V., Goetz, S. J., Loveland, T. R., Kommareddy, a, Egorov, a, Chini, L., Justice, C. O., and Townshend, J. R. G.: High-resolution global maps of 21st-century forest cover change, Science, 342, 850–3, https://doi.org/10.1126/science.1244693, 2013.
He, H. S.: Forest landscape models: Definitions, characterization, and classification, Forest Ecol. Manag., 254, 484–498, https://doi.org/10.1016/j.foreco.2007.08.022, 2008.
Hetzer, J., Huth, A., Wiegand, T., Dobner, H. J., and Fischer, R.: An analysis of forest biomass sampling strategies across scales, Biogeosciences, 17, 1673–1683, https://doi.org/10.5194/bg-17-1673-2020, 2020.
Hill, T. C., Quaife, T., and Williams, M.: A data assimilation method for using low-resolution Earth observation data in heterogeneous ecosystems, J. Geophys. Res.-Atmos., 116, 1–12, https://doi.org/10.1029/2010JD015268, 2011.
Hiltner, U., Huth, A., and Fischer, R.: Importance of the forest state in estimating biomass losses from tropical forests: combining dynamic forest models and remote sensing, Biogeosciences, 19, 1891–1911, https://doi.org/10.5194/bg-19-1891-2022, 2022.
Hubau, W., Lewis, S. L., Phillips, O. L., et al.: Asynchronous carbon sink saturation in African and Amazonian tropical forests, Nature, 579, 80–87, https://doi.org/10.1038/s41586-020-2035-0, 2020.
Hubbell, S., Foster, R., O'Brien, S., Harms, K., Condit, R., Wechsler, B., Wright, S., and Loo de Lao, S.: Light gap disturbances, recruitment limitation, and tree diversity in a neotropical forest, Science, 283, 554–557, https://doi.org/10.1126/science.283.5401.554, 1999.
Inman, H. F. and Bradley, E. L.: The Overlapping Coefficient as a Measure of Agreement Between Probability Distributions and Point Estimation of the Overlap of two Normal Densities, Commun. Stat. A-Theor., 18, 3851–3874, https://doi.org/10.1080/03610928908830127, 1989.
Jelinski, D. E. and Wu, J.: The modifiable areal unit problem and implications for landscape ecology, Landscape Ecol., 11, 129–140, https://doi.org/10.1007/BF02447512, 1996.
Knapp, N., Fischer, R., and Huth, A.: Linking lidar and forest modeling to assess biomass estimation across scales and disturbance states, Remote Sens. Environ., 205, 199–209, https://doi.org/10.1016/j.rse.2017.11.018, 2018a.
Knapp, N., Huth, A., Kugler, F., Papathanassiou, K., Condit, R., Hubbell, S. P., and Fischer, R.: Model-assisted estimation of tropical forest biomass change: A comparison of approaches, Remote Sens.-Basel, 10, 1–23, https://doi.org/10.3390/rs10050731, 2018b.
Knapp, N., Fischer, R., Cazcarra-Bes, V., and Huth, A.: Structure metrics to generalize biomass estimation from lidar across forest types from different continents, Remote Sens. Environ., 237, 111597, https://doi.org/10.1016/j.rse.2019.111597, 2020.
Landsberg, J.: Modelling forest ecosystems: State of the art, challenges, and future directions, Can. J. Forest Res., 33, 385–397, https://doi.org/10.1139/x02-129, 2003.
Lewis, S. L., Edwards, D. P., and Galbraith, D.: Increasing human dominance of tropical forests, Science, 349, 827–832, https://doi.org/10.1126/science.aaa9932, 2015.
Lister, A. J. and Leites, L. P.: Modeling and simulation of tree spatial patterns in an oak-hickory forest with a modular, hierarchical spatial point process framework, Ecol. Model., 378, 37–45, https://doi.org/10.1016/j.ecolmodel.2018.03.012, 2018.
Lobo, E. and Dalling, J. W.: Spatial scale and sampling resolution affect measures of gap disturbance in a lowland tropical forest: Implications for understanding forest regeneration and carbon storage, P. R. Soc. B, 281, 1–8, https://doi.org/10.1098/rspb.2013.3218, 2014.
Maréchaux, I. and Chave, J.: An individual-based forest model to jointly simulate carbon and tree diversity in Amazonia: description and applications, Ecol. Monogr., 87, 632–664, https://doi.org/10.1002/ecm.1271, 2017.
Maréchaux, I., Langerwisch, F., Huth, A., Bugmann, H., Morin, X., Reyer, C. P. O., Seidl, R., Collalti, A., Dantas de Paula, M., Fischer, R., Gutsch, M., Lexer, M. J., Lischke, H., Rammig, A., Rödig, E., Sakschewski, B., Taubert, F., Thonicke, K., Vacchiano, G., and Bohn, F. J.: Tackling unresolved questions in forest ecology: The past and future role of simulation models, Ecol. Evol., 11, 3746–3770, https://doi.org/10.1002/ece3.7391, 2021.
Marques, D. M. and Costa, J. F.: Analysis of the dispersion variance using geostatistical simulation and blending piles, J. S. Afr. I. Min. Metall., 114, 599–604, 2014.
Mascaro, J., Asner, G. P., Muller-Landau, H. C., van Breugel, M., Hall, J., and Dahlin, K.: Controls over aboveground forest carbon density on Barro Colorado Island, Panama, Biogeosciences, 8, 1615–1629, https://doi.org/10.5194/bg-8-1615-2011, 2011.
Mitchard, E. T. A.: The tropical forest carbon cycle and climate change, Nature, 559, 527–534, https://doi.org/10.1038/s41586-018-0300-2, 2018.
Openshaw, S.: The modifiable areal unit problem, in: Concepts and Techniques in Modern Geography, Vol. 38, Geo Books, 43, ISBN 0860941345, 1983.
Otto, S. P. and Day, T.: A biologist's guide to mathematical modeling in ecology and evolution, Princeton University Press, ISBN 9780691123448, 2011.
Pastore, M. and Calcagnì, A.: Measuring distribution similarities between samples: A distribution-free overlapping index, Front. Psychol., 10, 1–8, https://doi.org/10.3389/fpsyg.2019.01089, 2019.
Plummer, S. E.: Perspectives on combining ecological process models and remotely sensed data, Ecol. Model., 129, 169–186, https://doi.org/10.1016/S0304-3800(00)00233-7, 2000.
R Core Team: R: A language and environment for statistical computing, R Foundation for Statistical Computing, Vienna, Austria, https://www.R-project.org/, last access: 12 October 2022.
Rammer, W. and Seidl, R.: A scalable model of vegetation transitions using deep neural networks, Methods Ecol. Evol., 10, 879–890, https://doi.org/10.1111/2041-210X.13171, 2019.
Rammig, A., Heinke, J., Hofhansl, F., Verbeeck, H., Baker, T. R., Christoffersen, B., Ciais, P., De Deurwaerder, H., Fleischer, K., Galbraith, D., Guimberteau, M., Huth, A., Johnson, M., Krujit, B., Langerwisch, F., Meir, P., Papastefanou, P., Sampaio, G., Thonicke, K., von Randow, C., Zang, C., and Rödig, E.: A generic pixel-to-point comparison for simulated large-scale ecosystem properties and ground-based observations: an example from the Amazon region, Geosci. Model Dev., 11, 5203–5215, https://doi.org/10.5194/gmd-11-5203-2018, 2018.
Rebmann, C., Göckede, M., Foken, T., Aubinet, M., Aurela, M., Berbigier, P., Bernhofer, C., Buchmann, N., Carrara, A., Cescatti, A., Ceulemans, R., Clement, R., Elbers, J. A., Granier, A., Grünwald, T., Guyon, D., Havránková, K., Heinesch, B., Knohl, A., Laurila, T., Longdoz, B., Marcolla, B., Markkanen, T., Miglietta, F., Moncrieff, J., Montagnani, L., Moors, E., Nardino, M., Ourcival, J. M., Rambal, S., Rannik, Ü., Rotenberg, E., Sedlak, P., Unterhuber, G., Vesala, T., and Yakir, D.: Quality analysis applied on eddy covariance measurements at complex forest sites using footprint modelling, Theor. Appl. Climatol., 80, 121–141, https://doi.org/10.1007/s00704-004-0095-y, 2005.
Ridolfi, L., D'Odorico, P., and Laio, F.: Noise-induced phenomena in the environmental sciences, Cambridge University Press, https://doi.org/10.1017/CBO9780511984730, 2011.
Rödig, E., Cuntz, M., Heinke, J., Rammig, A., and Huth, A.: Spatial heterogeneity of biomass and forest structure of the Amazon rain forest: Linking remote sensing, forest modelling and field inventory, Global Ecol. Biogeogr., 26, 1292–1302, https://doi.org/10.1111/geb.12639, 2017.
Running, S. W., Nemani, R. R., Heinsch, F. A., Zhao, M., Reeves, M., and Hashimoto, H.: A continuous satellite-derived measure of global terrestrial primary production, BioScience, 54, 547–560, https://doi.org/10.1641/0006-3568(2004)054[0547:ACSMOG]2.0.CO;2, 2004.
Rutishauser, E., Wright, S. J., Condit, R., Hubbell, S. P., Davies, S. J., and Muller-Landau, H. C.: Testing for changes in biomass dynamics in large-scale forest datasets, Glob. Change Biol., 00, 1–15, https://doi.org/10.1111/gcb.14833, 2019.
Schmid, J. S., Taubert, F., Wiegand, T., Sun, I. F., and Huth, A.: Network science applied to forest megaplots: tropical tree species coexist in small-world networks, Sci. Rep.-UK, 10, 1–10, https://doi.org/10.1038/s41598-020-70052-8, 2020.
Shugart, H. H., Asner, G. P., Fischer, R., Huth, A., Knapp, N., Le Toan, T., and Shuman, J. K.: Computer and remote-sensing infrastructure to enhance large-scale testing of individual-based forest models, Front. Ecol. Environ., 13, 503–511, https://doi.org/10.1890/140327, 2015.
Shugart, H. H., Wang, B., Fischer, R., Ma, J., Fang, J., Yan, X., Huth, A., and Armstrong, A. H.: Gap models and their individual-based relatives in the assessment of the consequences of global change, Env. Res. Lett., 13, 033001, https://doi.org/10.1088/1748-9326/aaaacc, 2018.
Smith, T. M. and Urban, D. L.: Scale and resolution of forest structural pattern, Vegetatio, 74, 143–150, https://doi.org/10.1007/BF00044739, 1988.
Wang, S., Loreau, M., Arnoldi, J. F., Fang, J., Rahman, K. A., Tao, S., and De Mazancourt, C.: An invariability-area relationship sheds new light on the spatial scaling of ecological stability, Nat. Commun., 8, 1–8, https://doi.org/10.1038/ncomms15211, 2017.
Williams, M., Hill, T. C., and Ryan, C. M.: Using biomass distributions to determine probability and intensity of tropical forest disturbance, Plant Ecol. Divers., 6, 87–99, https://doi.org/10.1080/17550874.2012.692404, 2013.
Wong, D.: The Modifiable Areal Unit Problem (MAUP), in: The SAGE handbook of spatial analysis, edited by: Fotheringham, A. S. and Rogerson, P. A., SAGE, 105–123, ISBN 9781412910828, 2008.