the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 13 Mar 2025
| 13 Mar 2025
Selecting allometric equations to estimate forest biomass from plot- rather than individual-level predictive performance
Nicolas Picard
Noël Fonton
Faustin Boyemba Bosela
Adeline Fayolle
Joël Loumeto
Gabriel Ngua Ayecaba
Bonaventure Sonké
Olga Diane Yongo Bombo
Hervé Martial Maïdou
Alfred Ngomanda
In the context of global change, it is essential to quantify and monitor the carbon stored in forests. Allometric equations are mathematical models that predict the biomass of a tree from dendrometrical characteristics that are easier to measure, such as tree diameter, height, or wood density. Various model forms have been proposed for allometric equations. Moreover, the model choice has a critical influence on the estimate of the biomass of a forest. So far, model selection for allometric equations has been performed based on the tree-level predictive performance of the models. However, allometric equations are used to estimate the biomass of plots rather than individual trees. The distribution of trees sampled for establishing allometric equations often differs from the forest structure. Moreover, at the plot level, the residual individual errors for different trees can cancel off. Therefore, we expect the plot-level predictive performance of a model to differ from its tree-level performance. Using a dataset giving the observed biomass of 844 trees in central Africa and a null model for the size distribution of trees in the forest, we simulated forest plots between 0.1 and 50 ha in area. Then, using a Monte Carlo approach, we calculated the mean sum of squared errors (MSS) of the differences between observed and predicted plot biomass. We showed that MSS could be well approximated by a three-term formula, where the first term corresponded to bias, the second one corresponded to the tree residual error, and the third one corresponded to the uncertainty on model coefficients. For small plots (≤ 0.1 ha), the plot-level predictive performance was dominated by the tree residual error term. Model selection based on plot-level predictive performance was then consistent with that based on tree-level performance. For large plots, this term vanished. Model selection based on plot-level performance could then differ from that based on tree-level performance. In the case of large plots, chains of models that combined a general equation to predict biomass and local equations to predict some of the predictors of the biomass equation could provide a good trade-off between the bias in and the uncertainty on model coefficients. We recommend using plot-level rather than tree-level predictive performance to select allometric equations. The three-term formula that we developed provides an easy way to assess the effect of plot size on model selection and to balance the respective contributions of bias, tree residual error, and the uncertainty on model coefficients.
- Article
(1113 KB) - Full-text XML
- BibTeX
- EndNote




In the context of changing climate due to increasing CO2 atmospheric concentration, it is essential to quantify and monitor the main compartments that store or emit carbon at the global level. Forests are one of these compartments and are part of the solution to mitigate climate change (Lewis et al., 2019). However, there are still uncertainties in the quantification of forest carbon stocks, in particular in the tropics (Rodda et al., 2024). Measuring and monitoring forest carbon stocks involves a chain of measurements that starts with biomass measurement at individual tree level and ends with remote sensing techniques (Gibbs et al., 2007; Réjou-Méchain et al., 2019). Typically, tree-level biomass measurements are used to fit allometric equations that predict the biomass of a tree from tree dendrometrical characteristics that are easier to measure, such as diameter, height, or wood density (Chave et al., 2014). Allometric equations are used in turn to estimate the biomass of forest plots. Plot-level biomass can be used to fit plot-level models that predict plot biomass from plot volume and other plot characteristics, using biomass expansion factors or related approaches (Pan et al., 2004; Fang et al., 2007; Guo et al., 2010). These plot-level models can then be used to estimate forest biomass at the country (Fang et al., 2007) and continental (Fang et al., 2014) scales. Plot-level biomass data can also be used to calibrate remote sensing indices to predict the biomass of pixels in satellite images. Satellite images are finally used to map forest biomass on large areas.
Because plot-level biomass data are key for large-scale biomass estimation, it has been proposed to directly measure biomass at the plot level (Clark and Kellner, 2012). Fast-developing measurement techniques like terrestrial or airborne lidar may provide plot-level measures of biomass in the future (Xu et al., 2021). However, based on destructive measurements, plot-level measures of biomass are currently difficult. Allometric equations thus remain an indispensable link in the measurement chain (Vorster et al., 2020). The development of new tree biomass allometric equations is still mobilizing a great deal of scientific effort around the world (Yang et al., 2024). However, the uncertainty on the choice of the allometric equation used to convert inventory data into biomass estimates remains a major source of error (Picard et al., 2016). In this study, we focus on the step of the allometric equation that connects the tree level to the plot level while considering that allometric equations are intended to provide biomass estimates at the plot level rather than at the tree level (McRoberts and Westfall, 2014; McRoberts et al., 2015; Paul et al., 2016).
Improving the predictive performance of allometric equations often consists of reducing their residual standard error. This reduction can be achieved by integrating new predictors into the equation, such as crown dimensions, trunk shape, diameter of the largest branches, or tree architecture (MacFarlane, 2011; Goodman et al., 2014; Brede et al., 2022). New measurement techniques are indeed providing a greater level of detail in the description of trees (Momo Takoudjou et al., 2018; Lines et al., 2022). There is an ecological interest in understanding the drivers of biomass allometry at the tree level (Yang et al., 2024). Nevertheless, the application of allometric equations to plot data over large areas relies on forest inventory data. The use of detailed predictors in allometric equations is thus limited by the set of dendrometrical variables commonly available in forest inventories. In tropical forests, these variables are usually limited to diameter and species. Adding dendrometrical predictors to the model to reduce the tree-level residual error would then inflate the measurement cost to obtain these additional predictors at the plot level.
Beyond the availability of predictors at the plot level, there is a more fundamental reason for not systematically attempting to reduce the residual standard error of allometric equations. A large residual error at the tree level may be compensated at the plot level when the residual errors from different trees cancel off. The leveling off of the individual residual error is all the more important, as the plot is large. Thus, explaining the greatest share of the variance in tree biomass may not always be the best strategy to select an allometric equation to predict plot biomass. Assessing the predictive performance of allometric equations at the plot level, rather than at the individual level, could significantly alter how equations are selected and improved.
Adding a predictor that is not available in inventory data can be achieved by using an auxiliary equation to predict this predictor. Tree height has often been incorporated in biomass allometric equations in this way (Chave et al., 2014). Tree height generally improves the prediction of biomass but is rarely available in large-scale forest inventories. On the other hand, datasets on tree height are much more abundant than datasets on tree biomass, so a diameter–height model can usually be fitted with higher precision than biomass models (Feldpausch et al., 2011). Thus, one option is to predict height from diameter, then biomass from diameter and height, i.e., to use a chain of models (Feldpausch et al., 2012). Another option is to predict biomass from diameter alone. A pending question is which option is the best.
Table 1Statistics used to assess the predictive performance of a fitted allometric model f at the tree, plot, and forest levels. The mathematical expressions are only specified for the statistics specific to this study. Otherwise, the description of the statistic is recalled. The allometric model f was fitted to a dataset 𝒳 that gave the biomass Bi and the dendrometrical characteristics xi of m trees. The coefficients θ of model f had a multivariate normal distribution Φ with covariance matrix Σ. A plot with area A and tree density N was obtained by sampling N×A trees from 𝒳 with replacement using the probability of drawing wi for the ith tree of 𝒳. The forest was the limit when the plot area A tended to infinity for a fixed N.

The objective of this study was to compare allometric equations based on their predictive performance at the plot level rather than at the tree level. We examined whether shifting the focus from the tree to the plot influenced model selection. Different competing models were compared. We placed ourselves in the context of fitting allometric equations, when a calibration dataset of observed tree biomass is available and model coefficients need to be estimated. A different context is when allometric equations are given with known coefficients, and a validation dataset is given to compare their predictive performance. The method we proposed can accommodate models fitted in different ways. It can also be used to assess the predictive performance of a chain of models, i.e., a model that predicts y from x followed by another one that predicts tree biomass from y. Such a situation is often found when it comes to the role of tree height in the prediction of its biomass. Our method is a Monte Carlo method that relied on randomly generated plot-level data, thus allowing us to compare equations for different plot sizes. Given a dataset on individual tree attributes (including tree biomass), a plot was generated by randomly picking trees while constraining plot structural characteristics (such as tree density or basal area) to prescribed values. These plot structural characteristics were set using a null forest model. We used a dataset on tree biomass in the Congo Basin to illustrate the method (Fayolle et al., 2018).
Using this dataset, we addressed the following questions. (i) Does model selection based on predictive performance at tree level agree with model selection based on predictive performance at plot level? (ii) How does plot size affect model selection when this selection is based on predictive performance at plot level? (iii) When extra data on tree height are available so that a height–diameter model can be fitted, does predicted height improve the prediction of biomass through a chain of models? We hypothesized that the role of the residual model error, which is decisive in tree-level predictive performance, decreases with plot size when evaluating plot-level predictive performance.
The comparison and selection of allometric equations is commonly based on the goodness of fit of the fitted models, using selection criteria like the Akaike information criterion (AIC), the Bayesian information criterion (BIC), and the root-mean-square error (RMSE). This selection mode puts the emphasis on the predictive performance of the models at the tree level. Here, we assessed the predictive performance of allometric equations (i) at the tree level based on a dataset of tree biomass observations, (ii) at the plot level based on randomly generated plots using a null forest model and the tree dataset, and (iii) at the forest level based on the same null forest model. For each of these three levels, specific performance statistics were used (Table 1).
From a statistical standpoint, criteria like AIC or BIC may be tricky to use to compare models that have been fitted in different ways (e.g., ordinary-least-squares fitting on log-transformed data versus weighted-least-squares fitting on untransformed data). All the models we considered were fitted using linear regression on log-transformed data. Thus, AIC, R2, and the residual standard error σ refer to the model fit (i.e., the log-transformed biomass), while the other statistics in Table 1 refer to biomass.
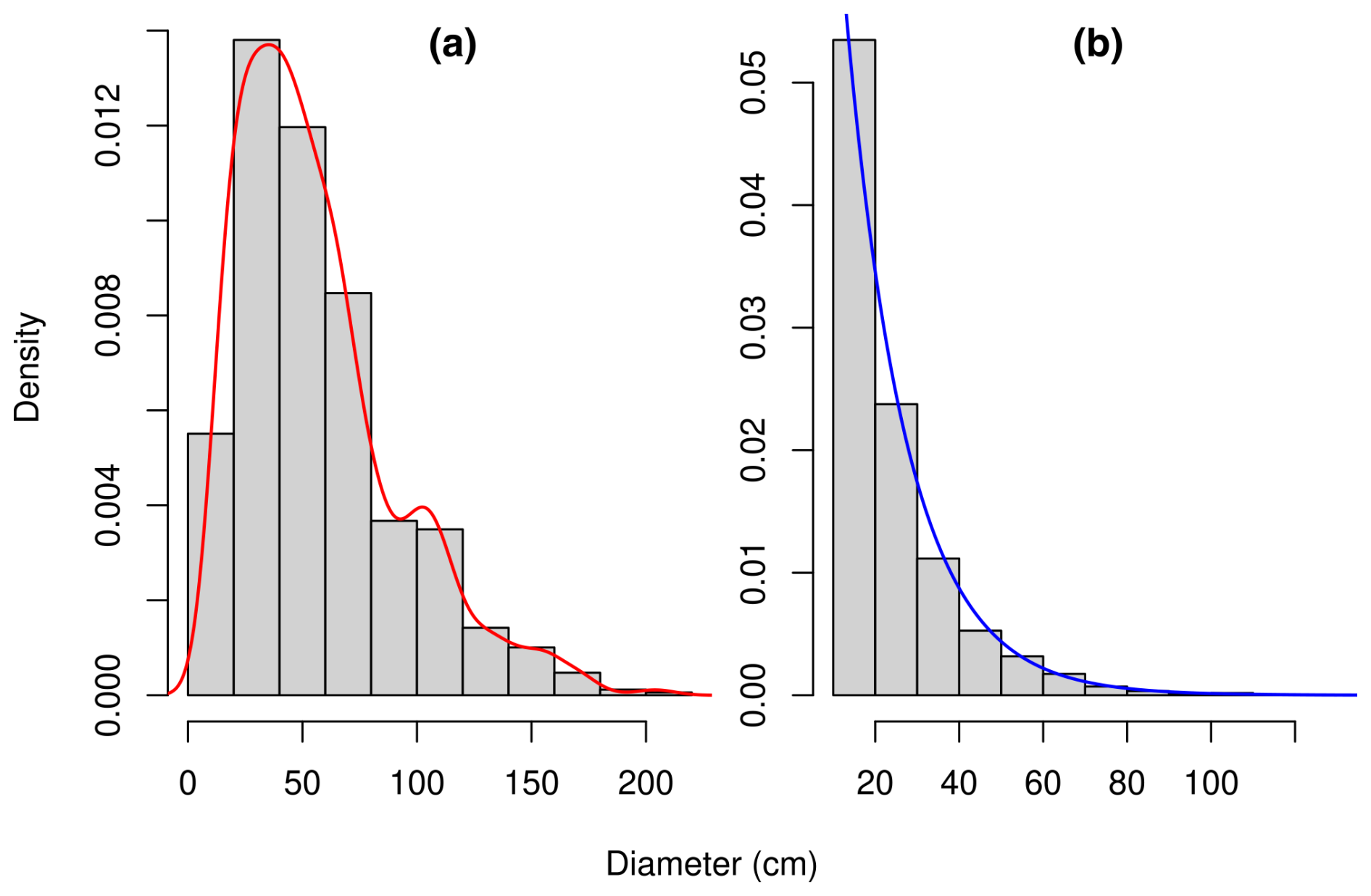
Figure 1Diameter distribution of (a) the 844 trees sampled in the Congo Basin forests for the measurement of their biomass (Fayolle et al., 2018) and (b) the 10 000 trees resampled from the former set of trees so as to conform to an exponential distribution with parameter 0.0689 cm−1. The red line is a density estimate d𝒳 of the distribution using a Gaussian kernel with a bandwidth determined by Silverman's rule of thumb. The blue line is the density dℱ of the exponential distribution with parameter 0.0689 cm−1. The dataset in panel (b) was obtained from the dataset in panel (a) by resampling each diameter x with a probability proportional to .
2.1 Tree biomass data and tree-level predictive performance
We used the dataset on individual tree biomass described in Fayolle et al. (2018). This dataset, denoted 𝒳, includes the diameter, height, wood specific gravity, aboveground biomass, and species of m=844 trees in the Congo Basin. The trees belong to 52 different species and 49 different genera. Data were collected in six countries of the Congo Basin: Cameroon, Central African Republic, Congo, Democratic Republic of the Congo, Equatorial Guinea, and Gabon. Details on tree measurements and data collection are given in Fayolle et al. (2018). Trees in dataset 𝒳 were sampled in the range 10.3–208.0 cm in diameter at breast height (dbh), with a peak of the sampling effort around 35 cm dbh (Fig. 1). Let d𝒳 be the density of the diameter distribution of trees in dataset 𝒳. This distribution reflects the sampling design of trees and is unrelated to the diameter distribution of trees in the forest.
Let f be an allometric equation that predicts the tree biomass f(x,θ) of each tree using its dendrometrical characteristics x, where θ denotes the coefficients of the model. Model f included the bias correction factor when back-transforming data from the log-transform. A prediction bias remained even with this correction factor. The prediction error for a tree with observed biomass B was . From the prediction errors for all trees in dataset 𝒳, various performance statistics could be computed, including the prediction bias b𝒳, which is the average prediction error, and the mean squared error MSE𝒳 (Table 1). Although rarely considered in the statistics of predictive performance of allometric equations, one may also consider the prediction variability brought by the uncertainty on the model coefficients θ. When using a linear regression to fit the model, the estimator of θ is distributed as a multivariate normal distribution with mean θ and covariance matrix Σ. Drawing coefficient values ϑ according to this multivariate normal distribution, computing the resulting tree biomass f(x,ϑ), and averaging its squared difference with the prediction f(x,θ) brought the mean error ME𝒳 (Table 1).
As a secondary dataset, denoted 𝒳′, we used a subset of the pantropical dataset assembled before 𝒳 by Chave et al. (2014). We kept only observations from the Congo Basin (Cameroon, Central African Republic, and Gabon), totaling trees. The dataset gives the diameter, height, wood specific gravity, and aboveground biomass of trees. However, for the purposes of our study, we only kept the diameter and height variables.
2.2 Null forest stand model and forest-level predictive performance
Plot-level biomass data were generated using the collection of tree biomass measurements and a null model for the diameter structure of the forest. This null model had two entries: the stand density N and its basal area G. Following the hypothesis of demographic equilibrium, the null model assumed that the forest had a reverse-J-shaped diameter distribution that could be modeled by an exponential distribution (Muller-Landau et al., 2006; Picard et al., 2021). The parameter μ of this exponential distribution can be computed from N and G as , where x0 is the minimum diameter for inventory in the forest plot. For N and G we used average values given by Picard et al. (2021), based on sample plots in central Africa: N = 467 ha−1 and G = 29.8 m2 ha−1. These values gave μ = 0.0689 cm−1.
An outcome 𝒴 of a plot in the null forest was randomly drawn by resampling dataset 𝒳 so that the diameter distribution of trees in 𝒴 conformed to the exponential distribution with parameter μ. Let be the density of this target distribution. Because the diameter distribution of trees in 𝒳 differed for the target distribution, the resampling involved unequal weights. Specifically, the ith tree of 𝒳 was resampled with a weight wi proportional to . In other words,
so . For a forest plot with area A, the N×A trees in 𝒴 were thus sampled from 𝒳 with replacement using the probability of drawing wi for the ith tree of 𝒳.
The forest level was reached by letting the plot area A tend to infinity for a fixed N. In the resulting forest-level distribution of trees, the ith tree of 𝒳 had probability wi. Replacing equal tree weights with these unequal weights wi changed the predictive performance statistics. The prediction bias at the forest level bℱ, the mean squared error MSEℱ, and the mean error MEℱ due to the uncertainty on the model coefficients were thus obtained (Table 1).
2.3 Error partitioning and plot-level predictive performance
The different sources of prediction error at the plot level were assessed using a Monte Carlo approach. Plot variability in biomass predictions was generated by drawing different outcomes of the null forest stand model. The variability due to model coefficients was generated by drawing different outcomes of the model coefficients according to a multivariate normal distribution with mean θ and covariance matrix Σ. Calculations were performed by combining each plot outcome with each coefficient outcome, resulting in a full factorial design.
2.3.1 For a model
Let K be the number of randomly generated forest plots and let J be the number of randomly generated model coefficients. Let nk be the number of trees in the kth plot, let θj be the jth outcome of the model coefficients, and let xki and Bki be the dendrometrical characteristics and observed biomass of the ith tree of the kth plot. Let be the difference between the observed biomass of the kth plot and its predicted biomass according to model f using the jth coefficient value per unit of plot area. The plot-level predictive performance of model f was assessed using the mean sum of squares of these differences, denoted mean sum of squared errors (MSS). Using the calculations of the analysis of variance, this mean sum of squared differences could be partitioned into the squared bias, the plot variability, and the coefficient variability (Appendix A1). These three terms could be approximated by (Nbℱ)2, , and N2 MEℱ, respectively.
2.3.2 For a chain of models
We generalized the assessment of the predictive performance of an equation to a chain of two allometric equations, where the response variable of the first equation is a predictor of the second one. Our computations readily extends to a chain of three or more allometric equations. Let g be an allometric equation that predicts some tree characteristics from some dendrometrical characteristics x of the tree. Let f be a second allometric equation that predicts the tree biomass using its dendrometrical characteristics x and those predicted by model g. Coefficients θ and ϕ are those of models f and g, respectively. Typically, y is tree height. The chain f∘g cannot be compared to another biomass model using AIC or BIC, whereas the MSS statistic still allowed us to compare their predictive performance.
To the K randomly generated plots and J randomly drawn coefficients θ, we now add L random draws of the coefficients ϕ. Let ϕl be the lth outcome of the model coefficients. Let be the difference between the observed biomass of the kth plot and its predicted biomass according to the chain f∘g using the jth coefficient value of f and the lth coefficient value of g per unit of plot area. The mean sum of squared errors (MSS) of these differences could be partitioned into four terms (Appendix A2): the squared bias, the plot variability, the variability due to the coefficients of model g, and the variability due to the coefficients of model f.
Table 2Statistics on the predictive performance of five allometric equations fitted to a dataset 𝒳 of 844 trees in the Congo Basin forests. The response variable of all these models is the log-transformed tree aboveground biomass ln (B), with B in kg. ρ is the wood specific gravity in g cm−3, D is tree diameter in cm, H is tree height in m, and s denotes the tree genus. N is the density of a forest plot with area A = 1 ha, distributed according to a null forest model ℱ. The quantity b is the prediction biases of tree biomass, MSE is the mean squared error of tree biomass, and ME is the mean error due to coefficient uncertainty. For these three quantities, subscripts ℱ and 𝒳 refer to the null forest and to the fitting dataset. AIC is the Akaike information criterion, σ is the residual standard error, and R2 is the coefficient of determination of the fitted model.

2.4 Model comparisons
We compared five allometric equations (see Eqs. 3–7 in Table 2) and one chain of equations. All these models are rooted in the concept of allometry as defined by Huxley and Teissier (1936). It assumes that the relative growth rates of two parts of an individual correlate (Gould, 1966). Models (3) to (6) correspond to simple allometry, where the ratio between relative growth rates is fixed. As discussed by White and Gould (1965), the biologically meaningful parameters are the coefficients associated to covariates. Model (7) corresponds to complex allometry, where the relative growth rate of biomass is a convex function of the relative growth rate of diameter. After back-transformation from the log-transform, model (7) also corresponds to a log-normal model (Picard et al., 2015). Its parameters correspond to maximal biomass, the diameter where biomass reaches its maximum, and a shape parameter. This model can account for senescence: as a tree grows, it accumulates biomass as its diameter increases, until it reaches senescence. When senescent, it may lose biomass (because of dead branches, holes in the trunk, etc.) while its diameter still increases. Regarding the chain of equations, its first model predicted tree height from tree diameter:
while its second model was model (3).
We used F-tests to compare nested models, i.e., to compare models (3) and (4), models (5) and (6), and models (6) and (7). Models (3)–(7) were fitted to dataset 𝒳 with m=844 observations, while model (2) was fitted to with observations. When back-transforming the data from the log-transform, the bias correction factor was used, where σ was the residual error of the fitted model. Monte Carlo computations were performed with K=1000 and J=1000, bringing 106 values of ekj. For the chain assessment, we used K=800 and , bringing 2×106 values of eklj. All computations were performed with the software R.
The predictive performances of the models differed between the tree level and the forest level. When looking at tree-level performance statistics, the best model was model (4). It had at the same time the lowest AIC, the smallest residual standard error σ, the smallest prediction bias Nb𝒳, the smallest mean squared error , and the smallest mean error due to coefficient uncertainty N2 ME𝒳 among the five competing models (Table 2). When looking at forest-level performance statistics, model (4) still had the smallest mean squared error and the smallest mean error due to coefficient uncertainty N2 MEℱ among the five models (Table 2). However, it was the worst-performing model in terms of prediction bias Nbℱ. The model with the smallest forest-level prediction bias Nbℱ was model (7).
The plot-level statistics (Nbℱ)2, , and N2 MEℱ approximated the terms of the partition of MSS well. The forest-level squared biased (Nbℱ)2 was a good approximation of the squared bias (SB) component of MSS for plot area greater than 50 ha (Fig. 2c). The SB component of MSS actually showed few fluctuations around (Nbℱ)2 as the plot area changed (Fig. 2c). The forest-level mean error due to coefficient uncertainty N2 MEℱ was also a good approximation of the coefficient variability component of MSS for plot area greater than 50 ha (Fig. 2a). Like SB, the coefficient variability showed few fluctuations around N2 MEℱ as plot area changed (Fig. 2a). In contrast, the plot variability component of MSS sharply decreased with plot area (Fig. 2b). It actually decreased proportionally to the inverse of plot area, with the coefficient of proportionality being well approximated by N MSEℱ.
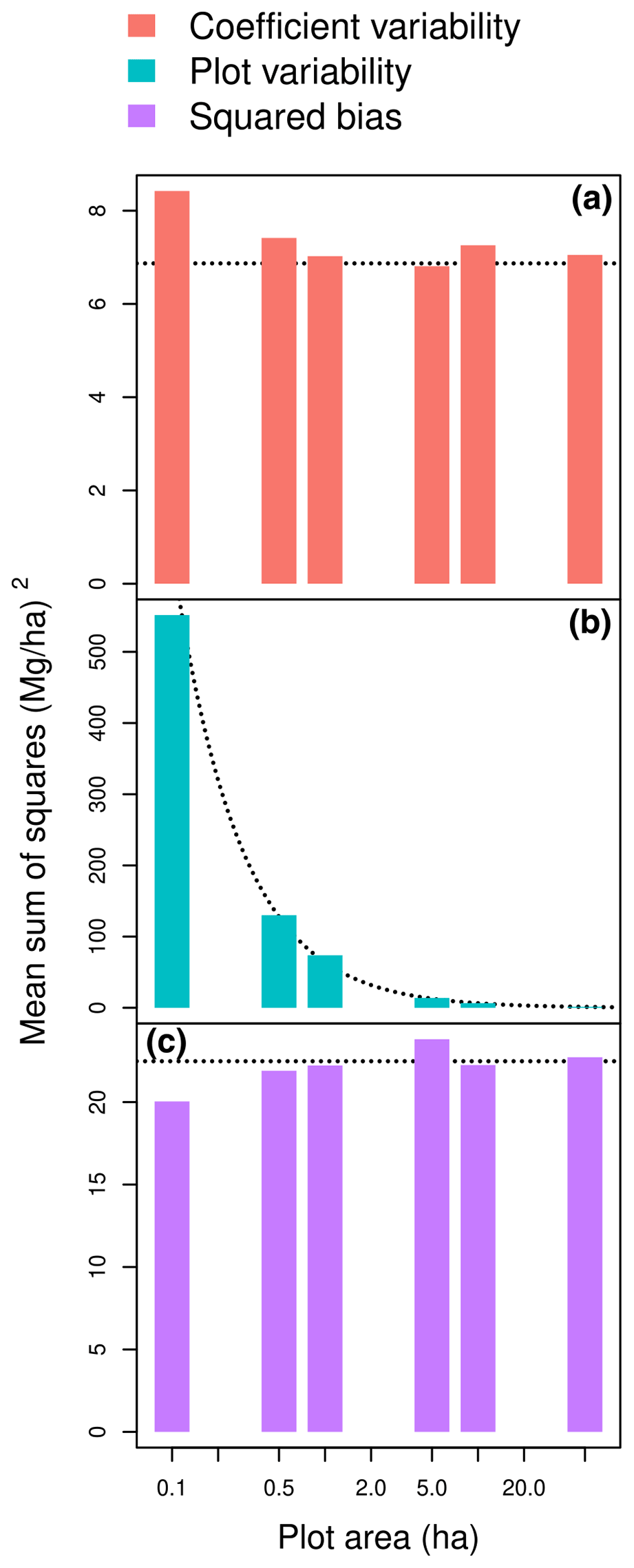
Figure 2Coefficient variability (a), plot variability (b), and squared bias (c) as a function of plot area when predicting the aboveground biomass of a forest plot using the allometric equation fitted to a dataset of 844 trees in the Congo Basin. The dashed lines are (a) the horizontal line y=N2 MEℱ; (b) the line , where A is the plot area; and (c) the horizontal line y=(Nbℱ)2, where forest plots are randomly generated according to a null forest model ℱ with tree density N. The x axis has a log scale.
The plot-level predictive performance of a model thus depended on plot area. For a small plot area of 0.1 ha, MSS was dominated by its plot variability component (blue bars in Fig. 3a). Accordingly, the model with the lowest MSS was model (4), i.e., the model with the lowest . This selection agreed with the model selection based on tree-level performance statistics (Fig. 3a). The ranking of the five competing models based on their AIC (model (4) > (6) > (7) > (3) > (5)) was actually almost the same as their ranking based on their MSS for a plot size of 0.1 ha (model (4) > (6) > (3) > (7) > (5)). For a plot area of 1 ha, MSS was still dominated by its plot variability component, but the other components of MSS (violet and orange bars in Fig. 3b) gained in importance. Model (4), which had a large prediction bias, was outperformed by model (7), which had the smallest prediction bias among the five models. For a large plot area of 10 ha, the plot variability component of MSS was no longer decisive in model selection (Fig. 3c). Thanks to its small prediction bias and coefficient variability, model (7) again outperformed the other models.
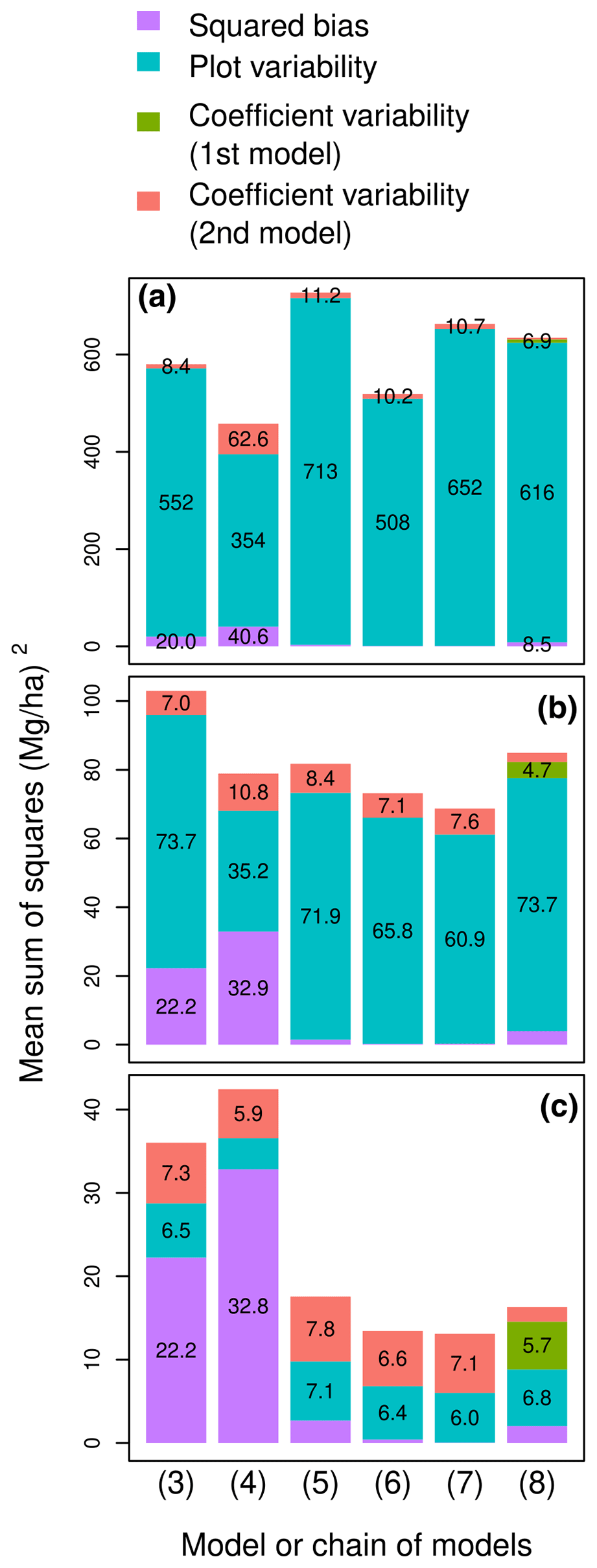
Figure 3Partition of the mean sum of squared errors into squared bias, plot variability, the variability due to the coefficients of the first model, and the variability due to the coefficients of the second model for six models or model chains (labeled on the x axis) and for plots of area (a) A = 0.1 ha, (b) A = 1 ha, and (c) A = 10 ha. Errors are the differences between observed and predicted plot-level aboveground biomass. Model labels follow the model numbering in Table 2: (3) ; (4) ; (5) ; (6) ; (7) ; (8) chain (f∘g), with g: and f: .
The choice of whether or not to add a variable to a model's predictors therefore depended on the level considered and the plot size. According to the F-test to compare nested models, which is a tree-level approach, model (6) outperformed model (5) (F=165.5 with 841 and 840 df, p value < 0.001). In other words, adding tree height on top of wood specific gravity and tree diameter in the model predictors improved the predictive performance of the model at the tree level. Whatever the plot area, the same conclusion was reached when comparing these two models at the plot level using MSS (compare models (5) and (6) in Fig. 3). However, model comparison based on MSS did not always agree with the F-test. All sorts of disagreement could be found. Tree-level prediction could be improved by adding the variable, while plot-level prediction was not. On the contrary, tree-level prediction was not improved by adding the variable, while plot-level prediction was. The variable “genus” illustrated the former disagreement: model (4) outperformed model (3) at the tree level (F=5.45 with 842 and 746 df, p value < 0.001). At the plot level, for a large plot area (10 ha), the performance ranking of the two models reversed (compare models (3) and (4) in Fig. 3c). The variable log (D)2 illustrated the latter disagreement: model (7) did not outperform model (6) at the tree level (F=0.20 with 840 and 839 df, p value = 0.66). At the plot level, the opposite conclusion was obtained for plot areas of 1 and 10 ha (compare models (6) and (7) in Fig. 3).
Adding tree height as a predictor through a chain of models improved plot-level predictive performances for large plots. There is no F-test or goodness-of-fit statistic to compare a chain of models to a model. However, the MSS allowed us to compare the models to the two-step chain where tree height was first predicted from tree diameter, then biomass was predicted from wood specific gravity, diameter, and height. Predicting tree height from diameter using a larger dataset reduced the prediction bias but brought some additional variability due to the coefficients of the height–diameter model. The model based on diameter alone outperformed the chain for a plot area of 1 ha (compare (5) and (8) in Fig. 3). However, as plot area increased and plot variability vanished, the chain performed better than the model based on diameter alone.
4.1 Predictive performance statistics
Forest-level predictive performance statistics were quite different from tree-level ones. Model selection for allometric equations has so far been based on tree-level predictive performance, such as AIC, residual standard error, and RMSE (e.g. Chave et al., 2014). Using forest-level performance statistics may thus shed new light on the selection of allometric equations among competing models. The different weighting of trees in the dataset and in the null forest changed the performance statistics. For instance, large trees had a much stronger weight in the dataset 𝒳 than in the null forest ℱ. Therefore, models that are biased for large trees will counter-perform according to b𝒳 but show better performance according to bℱ. This result also implies that different forests will yield different performance statistics. In particular, the diameter distribution of trees in the forest will influence the forest-level performance statistics.
A significant result of our study was that the performance of a model to predict the biomass of a plot depended on plot size. This result is consistent with previous results based on error propagation (Chave et al., 2004). The plot-level performance statistics were good proxies of the MSS partition. Rather than performing long Monte Carlo computations to obtain MSS, one can immediately approximate it as . This formula readily explains the change in MSS with plot size. For small plots, the predictive performance according to MSS is determined by the forest-level mean squared error MSEℱ. For large plots, individual tree errors compensate each other and cancel off, so MSEℱ no longer matters for the predictive performance. The predictive performance is then determined by the prediction bias and the variability due to model coefficients. In other words, models with high residual standard error are strongly penalized in tree-level selection, whereas it is much less a selection criterion in plot-level selection for large plots. When predicting the biomass of a large plot, what matters is the prediction bias and the coefficient variability.
When developing allometric equations, a recurring question is whether it is worth adding a variable among the set of predictors of a model (Feldpausch et al., 2012; Goodman et al., 2014). This question is equivalent to comparing two nested models, one with the variable among its predictors and the other without. When there was strong indication that adding the variable improved the prediction of the biomass of trees, the same conclusion was reached when considering the biomass of plots. However, when the benefit from adding the variable was not so marked, the conclusion based on tree-level prediction could differ from that based on plot-level prediction. Adding a predictor is all the more relevant, as it explains biomass variability. Alternatively, at the plot level, this variability can be left as a random noise that cancels off if the plot is large enough. It is thus a question of trade-off between bias and variance. The variable “genus” illustrates this trade-off here. Model (4), which fits a different allometry for each species genus, had the best tree-level predictive performance. It confirmed that different tree genera had different biomass allometries. However, at the scale of the forest where the species composition was not exactly the same as in the calibration dataset, model (4) resulted in the highest bias and the weakest overall predictive performance. In this example, we conclude that, even there are differences in allometry between tree genera, if our objective is to predict the biomass of large plots, it is statistically more efficient to leave the heterogeneity in species composition as a random noise.
Using plot-level predictive performance is desirable to predict plot biomass. However, to disentangle the biological processes that contribute to biomass allometry, goodness of fit should still be assessed at the tree level. The models we compared were all rooted in the allometry concept. Another family of models that predict tree-level biomass consists of geometric models, which are rooted in the tree taper concept. They predict biomass as wood density times volume, where volume is integrated from a taper equation (Manso et al., 2024). Another family of models emerges from the carbon allocation strategy of trees (Wolf et al., 2011; Yang et al., 2024). These different model families must be compared against the observations to build a theory of allometry.
One limitation of our study is that measurement errors were not taken into account in the MSS. However, measurement errors generally have a minor contribution to the overall biomass prediction error at the plot level (Chave et al., 2004). Another limitation is that simulated forests instead of real forest inventory data were used to generate plot data. We expect the bias contribution to MSS to increase with plot size for real data instead of being almost independent of it (Fig. 2c). If this hypothesis is verified, our results would be conservative with respect to the role of bias in model selection.
4.2 Validation datasets
We created this study in the context of model fitting, i.e., when a calibration dataset is available and model coefficients need to be estimated. A different context is when models are given with known coefficients and a validation dataset is available to compare their predictive performance. The MSS computations can take place in both contexts. Nonetheless, for a calibration dataset, by construction, model residuals sum up to zero. This property ensures that there is no prediction bias, at least for log-transformed variables and with equal tree weights in the dataset. This is no longer true with a validation dataset. If the trees used to fit the model are not representative of the area where the allometric equation is applied, it will lead to prediction bias. To exemplify this bias, we can fit the allometric equation using dataset 𝒳, whose trees come from central Africa, and assess its predictive performance using the subset of dataset 𝒳′ corresponding to the Amazon (with trees coming from Brazil, Colombia, French Guiana, and Peru). The coefficient variability and the plot variability were of the same order for Amazonian forests as for central African forests (Fig. 4a). However, the bias component was about 30 times greater for Amazonian forests than for central African forests, thus confirming that central African forests differed from Amazonian forests. Therefore, assessing the predictive performance of the allometric equations on a dataset that is not representative of the forest where the equations were fitted inflates the role of bias in the overall performance.
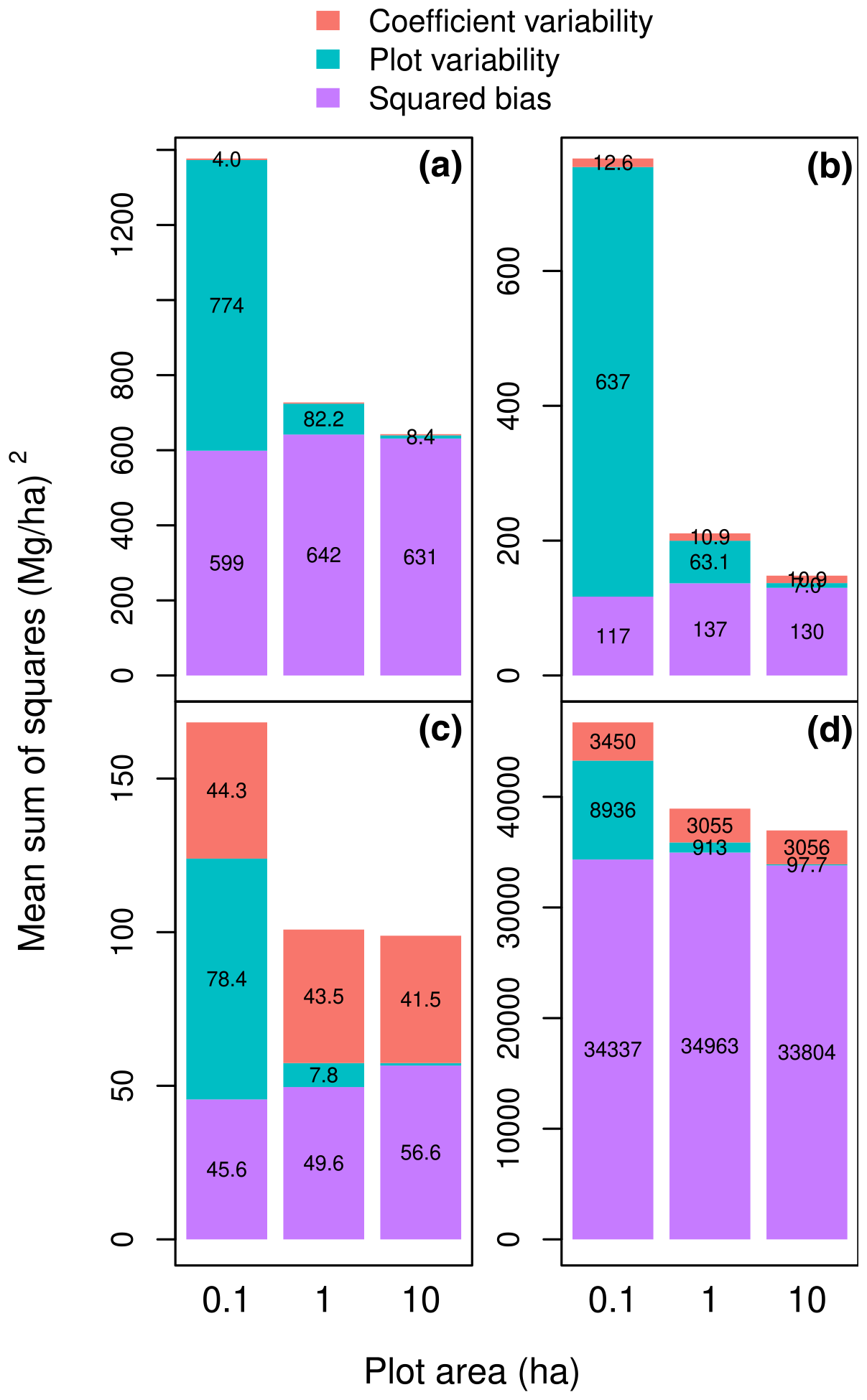
Figure 4Partition of the mean sum of squared errors (MSS) into squared bias, plot variability, and the variability due to the model coefficients when the dataset used for model fitting differs from the dataset used to compute MSS: (a) the calibration dataset is the dataset 𝒳 of Fayolle et al. (2018), and the validation dataset is a subset of the dataset of Chave et al. (2014) corresponding to the Amazon; (b) the calibration dataset is 𝒳, and the validation dataset is the subset of 𝒳 with the slenderest trees (i.e., excluding trees less than 0.9 × the average tree height); (c) the calibration dataset is the subset of 𝒳 with the largest trees (D≥ 48.9 cm), and the validation dataset is the subset of 𝒳 with the smallest trees (D < 48.9 cm); (d) the calibration dataset is the subset of 𝒳 with the smallest trees (D < 48.9 cm), and the validation dataset is the subset of 𝒳 with the largest trees (D≥ 48.9 cm). The model is , and the plot area varies from 0.1 to 10 ha (on the x axis). Errors are the differences between observed and predicted plot-level aboveground biomass.
If some model predictors vary in a systematic way (i.e., non-randomly) across plots in the validation dataset, then the model residuals will also result in a plot-level prediction bias. To illustrate this effect, consider a pseudo-validation dataset 𝒱 that is resampled from 𝒳 using weights wi given by Eq. (1) but with the additional condition that a tree is sampled if its height is greater than the 9/10 of the average height predicted by model (2). Dataset 𝒱 is not a true validation dataset because it is built from the calibration dataset 𝒳. Nonetheless, it illustrates what would happen if a validation dataset was taken from a plot where trees were systematically more slender than in the calibration plots. Then, the squared bias component of the MSS is indeed inflated. For model (3), it increases from 22 to 130 Mg2 ha−2 (Fig. 4b; to be compared to model (3) in Fig. 3).
A similar approach can be used to assess the prediction error when predictors extend beyond the calibration range. To illustrate this effect, we partitioned dataset 𝒳 into a subset of large trees with diameter ≥ 48.9 cm and a subset of small trees with diameter < 48.9 cm, where 48.9 cm is the median diameter of trees in 𝒳. One subset was then used for model fitting, and the other one was used to compute MSS. The error of predicting the biomass of large trees with an allometric equation fitted to small trees was much greater than the error of predicting the biomass of small trees with an allometric equation fitted to large trees (Fig. 4c and d). Moreover, the bias was comparatively greater in the former case than in the latter case. Due to heteroscedasticity, there is much more variability in tree biomass in large trees than in small trees. Including large trees in biomass datasets is a recommendation that has long been known (Chave et al., 2005).
4.3 Local specific versus general equations
Our results can contribute to the long-standing debate about locally developed specific equations versus general allometric equations (Chave et al., 2004; Weiskittel et al., 2015). Given a maximum sampling effort, and thus a given amount of available observations, the question is whether observations should be split among different categories (typically species and sites) to fit locally developed specific equations or whether observations should be kept together to fit a general equation. Locally developed specific equations tend to be less biased (Weiskittel et al., 2015). However, because they are based on a smaller number of observations, they tend to have a greater residual error and a greater variability due to coefficients. Our results indicate that the answer to this question also depends on the size of the plots for which biomass is predicted. Larger plots penalize biased models more heavily. They thus tend to favor locally developed specific equations. Our results also show that, in up to 1 ha of plot area, the plot variability is the dominant component of MSS. Because this component of MSS is the one related to the residual model error, it indicates that general allometric equations would tend to be preferred to predict the biomass of plots with an area less than or equal to 1 ha. This conclusion would have to be confirmed using other datasets.
A variant of this question is whether or not to add an extra variable (typically tree height) as a predictor of the model (Feldpausch et al., 2012). The extra variable can better account for local variation in biomass, thus reducing bias. On the other hand, the requirement for this variable may reduce the availability of data, thus increasing residual error and the variability due to coefficients. Using a chain of models where the extra variable is first predicted from other predictors (typically tree height predicted from diameter) can circumvent this problem (Chave et al., 2014; Sullivan et al., 2018). Typically, the first model (the height–diameter relationship) is locally fitted, while the second model (the biomass equation) is a general equation, thus combining the advantages of locally fitted models with those of general models. We showed here that this strategy could indeed be efficient, even for a single calibration dataset.
The plot-level predictive performance of an allometric equation depended on plot size. The effect of plot size A could be well approximated by the formula , where the first term corresponds to bias, the second corresponds to the tree residual error, and the third one corresponds to the uncertainty on model coefficients. For small plots (≤ 0.1 ha), the plot-level predictive performance was dominated by the MSEℱ term. Model selection based on plot-level predictive performance was then consistent with model selection based on tree-level performance. For large plots, the term depending on MSEℱ vanished. Model selection based on plot-level performance could then differ from that based on tree-level performance. In the case of large plots, chains of models that combined a general equation to predict biomass and local equations to predict some of the predictors of the biomass equation could provide a good trade-off between the bias and the uncertainty in model coefficients. For these large plots, introducing additional covariates in the models may not be needed. The unexplained share of biomass variability may instead be left as a random noise that cancels off among trees. Our results may thus contribute to save efforts in measuring tree biomass for the future development of allometric equations.
A1 One-model decomposition
For one model, the mean sum of squares of differences between observed and predicted plot-level biomass is
By the definition of the variance, the mean sum of squares is equal to the variance plus the squared bias. As the plot area tends to infinity, the number of trees goes to infinity and the difference between the plot-level observed biomass and the predicted one tends towards the forest-level bias times the number of trees in the plot. Thus MSS = Var + SB, where
Using the calculations of the analysis of variance, the variance can in turn be partitioned into an inter-plot variance (or plot variability) and an intra-plot variance. The variability in plot-level biomass errors results from the individual tree errors that do not compensate. Therefore, the greater the residual standard error of model f, the greater this plot variability. As the plot area tends to infinity, the tree-level errors from different trees compensate each other and the plot variability vanishes. As the plot area tends to zero, the tree-level errors from different trees do not compensate. For a very small plot area, the plot contains very few trees whose errors accumulate almost independently. Therefore, the plot-level variance of biomass differences is close to the sum of individual errors: NA×MSEℱ. Scaling this error per unit area of the plot finally brings .
Regarding the intra-plot variance (or variability within a plot), it results from the different coefficient values and reflects the uncertainty on these coefficients. For a tree taken at random in the forest with probability wi, the difference in biomass due to a model coefficient θj is . For the NA trees found in a plot with area A, this difference is multiplied by NA. Integrating over the possible outcomes of θj and scaling per unit area of the plot, it shows that the coefficient variability is close to N2 MEℱ.
To summarize, Var = (plot variability) + (coefficient variability), where
A2 Two-model decomposition
For a chain of two models, the mean sum of squares of differences between observed and predicted plot-level biomass is
As before, the mean sum of squares is the variance plus the squared bias, MSS = Var + SB, where
Again, the variance can be partitioned into an inter-plot variance (or plot variability) and an intra-plot variance (or coefficient variability), Var = (plot variability) + (coefficient variability), where
Now the coefficient variability can be partitioned into the variability due to the coefficients of model g and that due to the coefficients of model f, (coefficient variability) = (variability due to g coefficients) + (variability due to f coefficients), where
The code has been uploaded to Zenodo https://doi.org/10.5281/zenodo.12748213 (Picard, 2024).
We downloaded the data of Chave et al. (2014) at https://jeromechave.github.io/pantropical_allometry.htm. The PREREDD+ data will be shared on reasonable request to the last author.
NP and AN conceived the ideas; NF, FBB, AF, JL, GNA, BS, ODYB, HMM, and AN collected the data; NP designed the methodology, analyzed the data, and led the writing of the article. All authors made critical contributions to the drafts and gave final approval for publication.
The contact author has declared that none of the authors has any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims made in the text, published maps, institutional affiliations, or any other geographical representation in this paper. While Copernicus Publications makes every effort to include appropriate place names, the final responsibility lies with the authors.
This work was supported by the PREREDD+ regional project, funded by a gift from the Global Environment Facility, administered by the World Bank to the COMIFAC. Component 2b of the PREREDD+, which aimed at “building allometric equations for the forests of the Congo Basin”, was led by the ONFi/TEREA/Nature+ consortium. Data collection in Gabon was carried out by IRET with logistic support necessary for the field and laboratory measurements provided by Rougier Gabon.
This research has been supported by the Global Environment Facility (grant no. TF010038).
This paper was edited by David Medvigy and reviewed by Robson Borges de Lima and one anonymous referee.
Brede, B., Terryn, L., Barbier, N., Bartholomeus, H. M., Bartolo, R., Calders, K., Derroire, G., Moorthy, S. M. K., Lau, A., Levick, S. R., Raumonen, P., Verbeeck, H., Wang, D., Whiteside, T., van der Zee, J., and Herold, M.: Non-destructive estimation of individual tree biomass: Allometric models, terrestrial and UAV laser scanning, Remote Sens. Environ., 280, 113180, https://doi.org/10.1016/j.rse.2022.113180, 2022. a
Chave, J., Condit, R., Aguilar, S., Hernandez, A., Lao, S., and Perez, R.: Error propagation and scaling for tropical forest biomass estimates, Philos. T. Roy. Soc. B, 359, 409–420, https://doi.org/10.1098/rstb.2003.1425, 2004. a, b, c
Chave, J., Andalo, C., Brown, S., Cairns, M. A., Chambers, J. Q., Eamus, D., Fölster, H., Fromard, F., Higuchi, N., Kira, T., Lescure, J. P., Nelson, B. W., Ogawa, H., Puig, H., Riéra, B., and Yamakura, T.: Tree allometry and improved estimation of carbon stocks and balance in tropical forests, Oecologia, 145, 87–99, https://doi.org/10.1007/s00442-005-0100-x, 2005. a
Chave, J., Réjou-Méchain, M., Búrquez, A., Chidumayo, E., Colgan, M. S., Delitti, W. B. C., Duque, A., Eid, T., Fearnside, P. M., Goodman, R. C., Henry, M., Martínez-Yrízar, A., Mugasha, W. A., Muller-Landau, H. C., Mencuccini, M., Nelson, B. W., Ngomanda, A., Nogueira, E. M., Ortiz-Malavassi, E., Pélissier, R., Ploton, P., Ryan, C. M., Saldarriaga, J. G., and Vieilledent, G.: Improved allometric models to estimate the aboveground biomass of tropical trees, Glob. Change Biol., 20, 3177–3190, https://doi.org/10.1111/gcb.12629, 2014 (data available at: https://jeromechave.github.io/pantropical_allometry.htm, last access: 11 March 2025). a, b, c, d, e, f, g
Clark, D. B. and Kellner, J. R.: Tropical forest biomass estimation and the fallacy of misplaced concreteness, J. Veg. Sci., 23, 1191–1196, https://doi.org/10.1111/j.1654-1103.2012.01471.x, 2012. a
Fang, J., Guo, Z., Piao, S., and Chen, A.: Terrestrial vegetation carbon sinks in China, 1981–2000, Sci. China Ser. D, 50, 1341–1350, https://doi.org/10.1007/s11430-007-0049-1, 2007. a, b
Fang, J., Guo, Z., Hu, H., Kato, T., Muraoka, H., and Son, Y.: Forest biomass carbon sinks in East Asia, with special reference to the relative contributions of forest expansion and forest growth, Glob. Change Biol., 20, 2019–2030, https://doi.org/10.1111/gcb.12512, 2014. a
Fayolle, A., Ngomanda, A., Mbasi, M., Barbier, N., Bocko, Y., Boyemba, F., Couteron, P., Fonton, N., Kamdem, N., Katembo, J., Kondaoule, H. J., Loumeto, J., Maïdou, H. M., Mankou, G., Mengui, T., Mofack, G. I., Moundounga, C., Moundounga, Q., Nguimbous, L., Nchama, N. N., Obiang, D., Asue, F. O. M., Picard, N., Rossi, V., Senguela, Y. P., Sonké, B., Viard, L., Yongo, O. D., Zapfack, L., and Medjibe, V. P.: A regional allometry for the Congo basin forests based on the largest ever destructive sampling, Forest Ecol. Manag., 430, 228–240, https://doi.org/10.1016/j.foreco.2018.07.030, 2018. a, b, c, d, e
Feldpausch, T. R., Banin, L., Phillips, O. L., Baker, T. R., Lewis, S. L., Quesada, C. A., Affum-Baffoe, K., Arets, E. J. M. M., Berry, N. J., Bird, M., Brondizio, E. S., de Camargo, P., Chave, J., Djagbletey, G., Domingues, T. F., Drescher, M., Fearnside, P. M., França, M. B., Fyllas, N. M., Lopez-Gonzalez, G., Hladik, A., Higuchi, N., Hunter, M. O., Iida, Y., Salim, K. A., Kassim, A. R., Keller, M., Kemp, J., King, D. A., Lovett, J. C., Marimon, B. S., Marimon-Junior, B. H., Lenza, E., Marshall, A. R., Metcalfe, D. J., Mitchard, E. T. A., Moran, E. F., Nelson, B. W., Nilus, R., Nogueira, E. M., Palace, M., Patiño, S., Peh, K. S.-H., Raventos, M. T., Reitsma, J. M., Saiz, G., Schrodt, F., Sonké, B., Taedoumg, H. E., Tan, S., White, L., Wöll, H., and Lloyd, J.: Height-diameter allometry of tropical forest trees, Biogeosciences, 8, 1081–1106, https://doi.org/10.5194/bg-8-1081-2011, 2011. a
Feldpausch, T. R., Lloyd, J., Lewis, S. L., Brienen, R. J. W., Gloor, M., Monteagudo Mendoza, A., Lopez-Gonzalez, G., Banin, L., Abu Salim, K., Affum-Baffoe, K., Alexiades, M., Almeida, S., Amaral, I., Andrade, A., Aragão, L. E. O. C., Araujo Murakami, A., Arets, E. J. M. M., Arroyo, L., Aymard C., G. A., Baker, T. R., Bánki, O. S., Berry, N. J., Cardozo, N., Chave, J., Comiskey, J. A., Alvarez, E., de Oliveira, A., Di Fiore, A., Djagbletey, G., Domingues, T. F., Erwin, T. L., Fearnside, P. M., França, M. B., Freitas, M. A., Higuchi, N., E. Honorio C., Iida, Y., Jiménez, E., Kassim, A. R., Killeen, T. J., Laurance, W. F., Lovett, J. C., Malhi, Y., Marimon, B. S., Marimon-Junior, B. H., Lenza, E., Marshall, A. R., Mendoza, C., Metcalfe, D. J., Mitchard, E. T. A., Neill, D. A., Nelson, B. W., Nilus, R., Nogueira, E. M., Parada, A., Peh, K. S.-H., Pena Cruz, A., Peñuela, M. C., Pitman, N. C. A., Prieto, A., Quesada, C. A., Ramírez, F., Ramírez-Angulo, H., Reitsma, J. M., Rudas, A., Saiz, G., Salomão, R. P., Schwarz, M., Silva, N., Silva-Espejo, J. E., Silveira, M., Sonké, B., Stropp, J., Taedoumg, H. E., Tan, S., ter Steege, H., Terborgh, J., Torello-Raventos, M., van der Heijden, G. M. F., Vásquez, R., Vilanova, E., Vos, V. A., White, L., Willcock, S., Woell, H., and Phillips, O. L.: Tree height integrated into pantropical forest biomass estimates, Biogeosciences, 9, 3381–3403, https://doi.org/10.5194/bg-9-3381-2012, 2012. a, b, c
Gibbs, H. K., Brown, S., Niles, J. O., and Foley, J. A.: Monitoring and estimating tropical forest carbon stocks: making REDD a reality, Environ. Res. Lett., 2, 1–13, https://doi.org/10.1088/1748-9326/2/4/045023, 2007. a
Goodman, R. C., Phillips, O. L., and Baker, T. R.: The importance of crown dimensions to improve tropical tree biomass estimates, Ecol. Appl., 24, 680–698, https://doi.org/10.1890/13-0070.1, 2014. a, b
Gould, S. J.: Allometry and size in ontogeny and phylogeny, Biol. Rev., 41, 587–638, https://doi.org/10.1111/j.1469-185X.1966.tb01624.x, 1966. a
Guo, Z., Fang, J., Pan, Y., and Birdsey, R.: Inventory-based estimates of forest biomass carbon stocks in China: A comparison of three methods, Forest Ecol. Manag., 259, 1225–1231, https://doi.org/10.1016/j.foreco.2009.09.047, 2010. a
Huxley, J. S. and Teissier, G.: Terminology of relative growth, Nature, 137, 780–781, https://doi.org/10.1038/137780b0, 1936. a
Lewis, S. L., Wheeler, C. E., Mitchard, E. T. A., and Koch, A.: Restoring natural forests is the best way to remove atmospheric carbon, Nature, 568, 25–28, https://doi.org/10.1038/d41586-019-01026-8, 2019. a
Lines, E. R., Fischer, F. J., Owen, H. J. F., and Jucker, T.: The shape of trees: Reimagining forest ecology in three dimensions with remote sensing, J. Ecol., 110, 1730–1745, https://doi.org/10.1111/1365-2745.13944, 2022. a
MacFarlane, D. W.: Allometric scaling of large branch volume in hardwood trees in Michigan, USA: Implications for aboveground forest carbon stock inventories, Forest Sci., 57, 451–459, https://doi.org/10.1093/forestscience/57.6.451, 2011. a
Manso, R., Price, A., Ash, A., and Macdonald, E.: Volume prediction of young improved Sitka spruce trees in Great Britain through Bayesian model averaging, Forestry, cpae010, https://doi.org/10.1093/forestry/cpae010, 2024. a
McRoberts, R. E. and Westfall, J. A.: Effects of uncertainty in model predictions of individual tree volume on large area volume estimates, Forest Sci., 60, 34–42, https://doi.org/10.5849/forsci.12-141, 2014. a
McRoberts, R. E., Moser, P., Zimermann Oliveira, L., and Vibrans, A. C.: A general method for assessing the effects of uncertainty in individual-tree volume model predictions on large-area volume estimates with a subtropical forest illustration, Can. J. Forest Res., 45, 44–51, https://doi.org/10.1139/cjfr-2014-0266, 2015. a
Momo Takoudjou, S., Ploton, P., Sonké, B., Hackenberg, J., Griffon, S., De Coligny, F., Kamdem, N. G., Libalah, M., Mofack, G. I., Le Moguédec, G., Pélissier, R., and Barbier, N.: Using terrestrial laser scanning data to estimate large tropical trees biomass and calibrate allometric models: A comparison with traditional destructive approach, Methods Ecol. Evol., 9, 905–916, https://doi.org/10.1111/2041-210X.12933, 2018. a
Muller-Landau, H. C., Condit, R. S., Harms, K. E., Marks, C. O., Thomas, S. C., Bunyavejchewin, S., Chuyong, G., Co, L., Davies, S., Foster, R., Gunatilleke, S., Gunatilleke, N., Hart, T., Hubbell, S. P., Itoh, A., Kassim, A. R., Kenfack, D., Lafrankie, J. V., Lagunzad, D., Lee, H. S., Losos, E., Makana, J. R., Ohkubo, T., Samper, C., Sukumar, R., Sun, I.-f., Nur Supardi, M. N., Tan, S., Thomas, D., Thompson, J., Valencia, R., Vallejo, M. I., Villa Muñoz, G., Yamakura, T., Zimmerman, J. K., Dattaraja, H. S., Esufali, S., Hall, P., He, F., Hernandez, C., Kiratiprayoon, S., Suresh, H. S., Wills, C., and Ashton, P.: Comparing tropical forest tree size distributions with the predictions of metabolic ecology and equilibrium models, Ecol. Lett., 9, 589–602, https://doi.org/10.1111/j.1461-0248.2006.00915.x, 2006. a
Pan, Y., Luo, T., Birdsey, R., Hom, J., and Melillo, J.: New estimates of carbon storage and sequestration in China's forests: effects of age–class and method on inventory-based carbon estimation, Climatic Change, 67, 211–236, https://doi.org/10.1007/s10584-004-2799-5, 2004. a
Paul, K. I., Roxburgh, S. H., Chave, J., England, J. R., Zerihun, A., Specht, A., Lewis, T., Bennett, L. T., Baker, T. G., Adams, M. A., Huxtable, D., Montagu, K. D., Falster, D. S., Feller, M., Sochacki, S., Ritson, P., Bastin, G., Bartle, J., Wildy, D., Hobbs, T., Larmour, J., Waterworth, R., Stewart, H. T. L., Jonson, J., Forrester, D. I., Applegate, G., Mendham, D., Bradford, M., O'grady, A., Green, D., Sudmeyer, R., Rance, S. J., Turner, J., Barton, C., Wenk, E. H., Grove, T., Attiwill, P. M., Pinkard, E., Butler, D., Brooksbank, K., Spencer, B., Snowdon, P., O'brien, N., Battaglia, M., Cameron, D. M., Hamilton, S., McAuthur, G., and Sinclair, J.: Testing the generality of above-ground biomass allometry across plant functional types at the continent scale, Glob. Change Biol., 22, 2106–2124, https://doi.org/10.1111/gcb.13201, 2016. a
Picard, N.: R code to compute the performance statistics of allometric equations at plot level, Zenodo [code], https://doi.org/10.5281/zenodo.12748213, 2024. a
Picard, N., Rutishauser, E., Ploton, P., Ngomanda, A., and Henry, M.: Should tree biomass allometry be restricted to power models?, Forest Ecol. Manag., 353, 156–163, https://doi.org/10.1016/j.foreco.2015.05.035, 2015. a
Picard, N., Henry, M., Fonton, N. H., Kondaoulé, J., Fayolle, A., Birigazzi, L., Sola, G., Poultouchidou, A., Trotta, C., and Maïdou, H.: Error in the estimation of emission factors for forest degradation in central Africa, J. For. Res., 21, 23–30, https://doi.org/10.1007/s10310-015-0510-5, 2016. a
Picard, N., Mortier, F., Ploton, P., Liang, J., Derroire, G., Bastin, J. F., Ayyappan, N., Bénédet, F., Boyemba Bosela, F., Clark, C. J., Crowther, T. W., Engone Obiang, N. L., Forni, É., Harris, D., Ngomanda, A., Poulsen, J. R., Sonké, B., Couteron, P., and Gourlet-Fleury, S.: Using model analysis to unveil hidden patterns in tropical forest structures, Front. Ecol. Evol., 9, 599200, https://doi.org/10.3389/fevo.2021.599200, 2021. a, b
Réjou-Méchain, M., Barbier, N., Couteron, P., Ploton, P., Vincent, G., Herold, M., Mermoz, S., Saatchi, S., Chave, J., de Boissieu, F., Féret, J. B., Momo Takoudjou, S., and Pélissier, R.: Upscaling forest biomass from field to satellite measurements: sources of errors and ways to reduce them, Surv. Geophys., 40, 881–911, https://doi.org/10.1007/s10712-019-09532-0, 2019. a
Rodda, S. R., Fararoda, R., Gopalakrishnan, R., Jha, N., Réjou-Méchain, M., Couteron, P., Barbier, N., Alfonso, A., Bako, O., Bassama, P., Behera, D., Bissiengou, P., Biyiha, H., Brockelman, W. Y., Chanthorn, W., Chauhan, P., Dadhwal, V. K., Dauby, G., Deblauwe, V., Dongmo, N., Droissart, V., Jeyakumar, S., Jha, C. S., Kandem, N. G., Katembo, J., Kougue, R., Leblanc, H., Lewis, S., Libalah, M., Manikandan, M., Martin-Ducup, O., Mbock, G., Memiaghe, H., Mofack, G., Mutyala, P., Narayanan, A., Nathalang, A., Ndjock, G. O., Ngoula, F., Nidamanuri, R. R., Pélissier, R., Saatchi, S., Sagang, L. B., Salla, P., Simo-Droissart, M., Smith, T. B., Sonké, B., Stevart, T., Tjomb, D., Zebaze, D., Zemagho, L., and Ploton, P.: LiDAR-based reference aboveground biomass maps for tropical forests of South Asia and Central Africa, Scientific Data, 11, 334, https://doi.org/10.1038/s41597-024-03162-x, 2024. a
Sullivan, M. J. P., Lewis, S. L., Hubau, W., Qie, L., Baker, T. R., Banin, L. F., Chave, J., Cuni-Sanchez, A., Feldpausch, T. R., Lopez-Gonzalez, G., Arets, E., Ashton, P., Bastin, J. F., Berry, N. J., Bogaert, J., Boot, R., Brearley, F. Q., Brienen, R., Burslem, D. F. R. P., de Canniere, C., Chudomelová, M., Dancák, M., Ewango, C., Hédl, R., Lloyd, J., Makana, J. R., Malhi, Y., Marimon, B. S., Junior, B. H. M., Metali, F., Moore, S., Nagy, L., Vargas, P. N., Pendry, C. A., Ramírez-Angulo, H., Reitsma, J., Rutishauser, E., Salim, K. A., Sonké, B., Sukri, R. S., Sunderland, T., Svátek, M., Umunay, P. M., Martinez, R. V., Vernimmen, R. R. E., Torre, E. V., Vleminckx, J., Vos, V., and Phillips, O. L.: Field methods for sampling tree height for tropical forest biomass estimation, Methods Ecol. Evol., 9, 1179–1189, https://doi.org/10.1111/2041-210X.12962, 2018. a
Vorster, A. G., Evangelista, P. H., Stovall, A. E. L., and Ex, S.: Variability and uncertainty in forest biomass estimates from the tree to landscape scale: the role of allometric equations, Carbon Balance Manag., 15, 8, https://doi.org/10.1186/s13021-020-00143-6, 2020. a
Weiskittel, A. R., MacFarlane, D. W., Radtke, P. J., Affleck, D. L. R., Temesgen, H., Woodall, C. W., Westfall, J. A., and Coulston, J. W.: A call to improve methods for estimating tree biomass for regional and national assessments, J. Forest., 113, 414–424, https://doi.org/10.5849/jof.14-091, 2015. a, b
White, J. F. and Gould, S. J.: Interpretation of the coefficient in the allometric equation, Am. Nat., 99, 5–18, http://www.jstor.org/stable/2459251 (last access: 27 December 2024), 1965. a
Wolf, A., Field, C. B., and Berry, J. A.: Allometric growth and allocation in forests: a perspective from FLUXNET, Ecol. Appl., 21, 1546–1556, https://doi.org/10.1890/10-1201.1, 2011. a
Xu, D., Wang, H., Xu, W., Luan, Z., and Xu, X.: LiDAR applications to estimate forest biomass at individual tree scale: Opportunities, challenges and future perspectives, Forests, 12, 550, https://doi.org/10.3390/f12050550, 2021. a
Yang, M., Zhou, X., Liu, Z., Li, P., Liu, C., Huang, H., Tang, J., Zhang, C., Zou, Z., Xie, B., and Peng, C.: Dynamic carbon allocation trade-off: A robust approach to model tree biomass allometry, Methods Ecol. Evol., 15, 886–899, https://doi.org/10.1111/2041-210X.14315, 2024. a, b, c