the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 02 Mar 2023
| 02 Mar 2023
Spatiotemporal lagging of predictors improves machine learning estimates of atmosphere–forest CO2 exchange
Juha-Pekka Tuovinen
Markku Kulmala
Ivan Mammarella
Juha Aalto
Henriikka Vekuri
Annalea Lohila
Anna Lintunen
Accurate estimates of net ecosystem CO2 exchange (NEE) would improve the understanding of natural carbon sources and sinks and their role in the regulation of global atmospheric carbon. In this work, we use and compare the random forest (RF) and the gradient boosting (GB) machine learning (ML) methods for predicting year-round 6 h NEE over 1996–2018 in a pine-dominated boreal forest in southern Finland and analyze the predictability of NEE. Additionally, aggregation to weekly NEE values was applied to get information about longer term behavior of the method. The meteorological ERA5 reanalysis variables were used as predictors. Spatial and temporal neighborhood (predictor lagging) was used to provide the models more data to learn from, which was found to improve considerably the accuracy of both ML approaches compared to using only the nearest grid cell and time step. Both ML methods can explain temporal variability of NEE in the observational site of this study with meteorological predictors, but the GB method was more accurate. Only minor signs of overfitting could be detected for the GB algorithm when redundant variables were included. The accuracy of the approaches, measured mainly using cross-validated R2 score between the model result and the observed NEE, was high, reaching a best estimate value of 0.92 for GB and 0.88 for RF. In addition to the standard RF approach, we recommend using GB for modeling the CO2 fluxes of the ecosystems due to its potential for better performance.
- Article
(2363 KB) - Full-text XML
- BibTeX
- EndNote





Forests and other terrestrial carbon sinks remove about one-third of the anthropogenic carbon dioxide (CO2) annually emitted to the atmosphere, and thus they constitute an important component of the global carbon balance (Friedlingstein et al., 2020). However, the existing observation network for estimating the total atmosphere–ecosystem CO2 exchange is sparse (Alton, 2020), and especially historical coverage of observations over the past decades is poor. Among other biotypes and ecosystems, boreal forests contribute significantly to the global atmospheric carbon stock, but how they do it in detail is still largely unknown, reflected in the wide range of estimates of the carbon storage of these forests (Bradshaw and Warkentin, 2015). Therefore, there is a need for accurate spatiotemporal modeling of carbon fluxes for improved monitoring and understanding of the boreal, and ultimately, the global carbon cycles (Jung et al., 2020).
In boreal forests, the atmosphere–ecosystem CO2 flux shows strong seasonal and diurnal cycles, dominated by (1) the photosynthesis by plants (acting as a CO2 sink from the atmosphere), and (2) by the total ecosystem respiration, including plant respiration and organic decomposition processes by microorganisms (acting as a CO2 source into the atmosphere). In a homogeneous forest environment, the net flux generated by these processes can be accurately measured with the micrometeorological eddy covariance method, which has emerged as common standard for long-term ecosystem-scale flux measurements (Aubinet et al., 2012; Hicks and Baldocchi, 2020).
Both total respiration and photosynthesis are typically at their largest in the warm season in boreal forests (Ueyama et al., 2013; Wu et al., 2012; Kolari et al., 2007). On average, their net effect, i.e., net ecosystem exchange of CO2 (NEE), is dominated by photosynthesis on the weekly scale in summer, but on the subdaily scale, the total respiration turns NEE positive during nights when photosynthesis of plants is switched off. In the cold season, diurnal variability is mostly absent, and then NEE is again slightly positive as respiration still dominates.
Various meteorological and local abiotic and biotic factors and processes affect NEE, and their importance is different in different seasons. Local conditions include soil type and properties and plant species and their density distributions. Key meteorological variables, such as air temperature and shortwave radiation, typically have large seasonal and diurnal variations. These variables are observed globally using in situ and remote sensing techniques, and the resulting large-scale data sets can be further post-processed and homogenized via data assimilation, employing numerical weather prediction (NWP) models, and presented in a spatiotemporal grid format. This product is called reanalysis, which can be considered a byproduct of the NWP process (Parker, 2016).
In recent years, various machine learning (ML) approaches have been proposed and used to model NEE or related quantities over various locations and globally (Jung et al., 2020; Besnard et al., 2019). Even though NEE appears to be a difficult quantity to model accurately (Tramontana et al., 2016), the random forest method (RF) has been shown to be suitable for this task (Shi et al., 2022; Nadal-Sala et al., 2021; Reitz et al., 2021; Tramontana et al., 2015; Zhou et al., 2019). Typically, the previous work has concentrated on modeling the rather coarse weekly, monthly, or annual temporal resolution; however, some exceptions with subdaily resolution exist (Bodesheim et al., 2018).
Here we employ the RF algorithm to model the 6 h NEE between the atmosphere and a boreal forest in Finland. In addition to the RF regression method, we use the gradient boosting (GB) regression (Friedman, 2001; chap. 10 in Hastie et al., 2009), which has not been as common as the RF in this context. Both methods of this study fit an ensemble of regression trees to predict NEE. The potential of the GB resides in the fitting process: while the trees of RF are fit independently of each other, GB trees become aware of the prediction error of the previous trees as the fitting process continues sequentially, allowing them to concentrate on the most difficult samples (Chen and Guestrin, 2016).
Several meteorological predictors from the global ERA5 reanalysis (Hersbach et al., 2020) were used as input for the RF and GB regression models, including but not limited to soil and air temperatures, precipitation amounts, radiation quantities, and heat fluxes. In contrast to previous studies, we use only the raw reanalysis quantities as predictor input: specifically, we do not use meteorological in situ data directly (e.g., Mahabbati et al., 2021; Tramontana et al., 2015) nor satellite data directly (e.g., Zhou et al., 2019). By excluding many input data sources, we can simplify considerably the modeling process. However, in situ and satellite data have been used in the assimilation of the reanalysis itself (Hersbach et al., 2020).
We propose, test, and show the value of using spatiotemporal neighboring information from the ERA5 reanalysis for improving modeling results. Previously, temporal neighborhood has been used to improve the modeling; see, for instance, Besnard et al. (2019). The benefits of using the temporal neighborhood together with the spatial neighborhood have not been studied earlier.
Additionally, we investigate in detail whether the skill of the GB method could overcome the skill of the popular RF method in explaining the variability of NEE when using the meteorological predictors. For that, we first tune the hyperparameters of both ML methods carefully using Bayesian optimization (Snoek et al., 2012) and compare their results. Then, we rank the importance of the individual predictors in the study site using the SHAP analysis (Lundberg and Lee, 2017) and explore the effect of reducing both the number of samples and the number of predictors on the accuracy of the GB model. Finally, we discuss the significance of our results in a broader context.
2.1 CO2 flux measurements as the target variable
Eddy covariance CO2 flux data, measured above a 60-year-old Scots pine forest in Hyytiälä, Finland (61∘51′ N, 24∘17′ E) in 1996–2018, corresponding roughly to a footprint area of 125 000 m2 (Launiainen et al., 2022) and processed to represent NEE, were acquired from https://smear.avaa.csc.fi/download (last access: 25 February 2021). Flux processing for NEE was done using the EddyUH software (Mammarella et al., 2016; a summary of the data is shown in Fig. 1, presented as multi-year mean values). NEE is a sum of ecosystem carbon uptake in photosynthesis and carbon loss in respiration, and a negative NEE means that the forest takes up carbon, i.e., is a carbon sink. These data consist of 30 min averages which were aggregated for modeling to 6 h resolution using averaging with moving, non-overlapping windows. For this, 00:00, 06:00, 12:00, and 18:00 UTC were used: the hour values indicate the beginning of the averaging period. Only complete 6 h aggregates, i.e., those with no missing values arising from flux processing and instrument faults, were accepted for the averaging process. The resulting data set contained 10 500 non-missing data points and 22 800 missing values. In addition to the preprocessed NEE data, the modeling was separately tested using the raw CO2 flux (i.e., measured by the eddy covariance system and without storage change flux correction and friction velocity filtering) as the target variable.
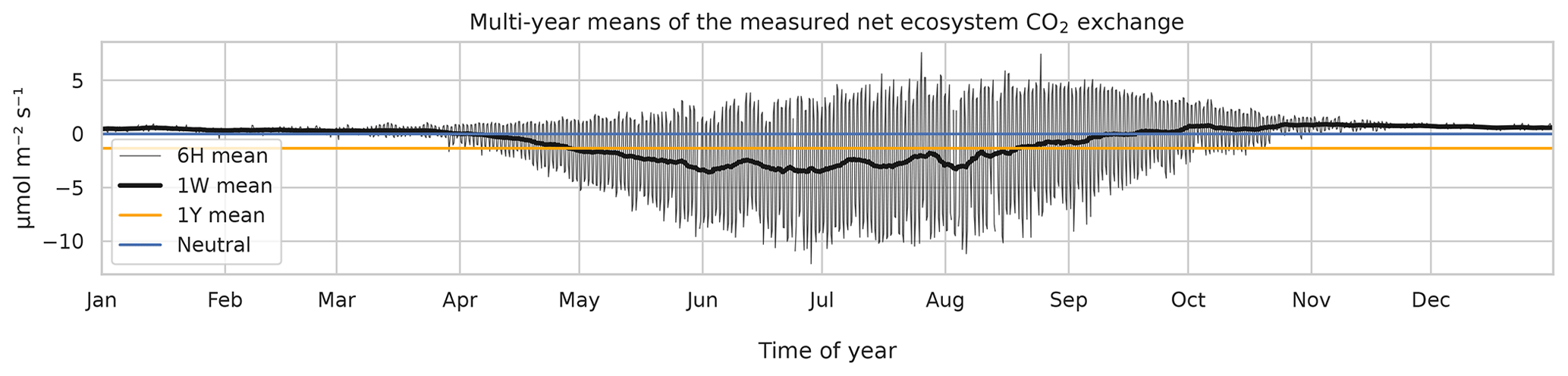
Figure 1The 6 h (thin black), weekly (thick black), and annual (orange) multi-year means of observed net ecosystem CO2 exchange (NEE) at the Hyytiälä SMEARII site. Eddy covariance method with a 24 m tall tower was used for measurements. Years 1996–2018 were used in calculation of the mean values.
Additionally, weekly means were calculated from the 6 h data for validation purposes. For this, a moving, overlapping, and centered windowing was used to preserve the same number of samples as in the 6 h data. Missing data inside the window were accepted not to discard almost all of the samples. When validating the model, the missing 22 800 time steps were also rejected from the model results for consistency. The diurnal distribution of the missing data was the following: 00:00 UTC – 75 %, 06:00 UTC – 66 %, 12:00 UTC – 59 %, and 18:00 UTC – 74 %.
2.2 Variables from the ERA5 reanalysis as predictors
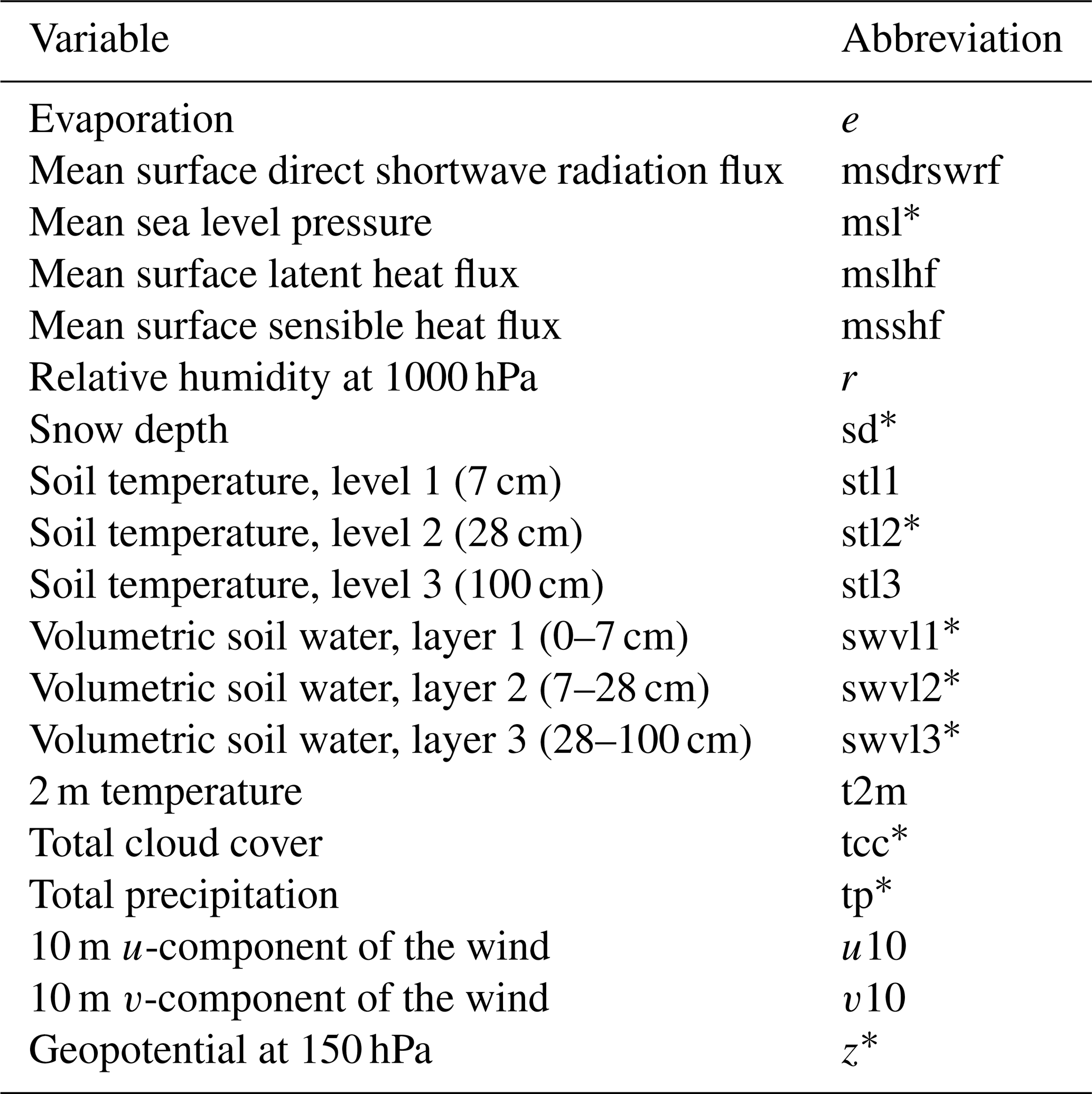
Typically, air and soil temperatures, shortwave (photosynthetically active) radiation, and relative humidity are the key meteorological variables used in modeling the CO2 flux (eg., Nadal-Sala et al., 2021). In addition to these, we included a large set of other variables (1) to search for new, unexpected relationships between the flux and these less common variables, and (2) to study how much these variables can either improve or deteriorate the accuracy of the model. Altogether 19 meteorological variables from the global ERA5 reanalysis product (Hersbach et al., 2017, 2020) were selected (Table 1).
The ERA5 reanalysis data for 1996–2018 were downloaded from https://cds.climate.copernicus.eu/ (last access: 15 March 2021) in the 1∘ × 1∘ spatial and 1 h temporal resolution. The data were downsampled to 6 h using moving averaging with non-overlapping windows, following the same procedure as with the CO2 flux data.
Table 1Gridded parameters from the ERA5 reanalysis product. Asterisks (*) indicate parameters which were found to be redundant – containing irrelevant or superfluous information compared to other parameters – and for this reason they were excluded from the final fitting of the model.
2.3 Temporal lagging and spatial neighborhoods of the predictor data
As the first approximation, the modeling could be carried out by using the grid point closest to the Hyytiälä site. Similarly, temporal synchronization of the predictor data and the target variable could be used. On the other hand, many processes happen sequentially in time, and their effect on the target variable could be seen as delayed. For example, meteorological conditions at nighttime can affect plant photosynthesis the following day (Kolari et al., 2007). On the other hand, because of biases and other uncertainties of the ERA5 reanalysis, the nearest grid cell might not represent the best estimate of the variability of different quantities – instead, the nearby cells could do that. We wanted to give the ML models the opportunity to take these effects into account, and we selected 25 closest grid cells around the site and five closest time steps around each of the time steps (t=0) of the target variable. Note that lagging was applied both to forward and delay the predictors in time (Fig. 2a). The reason to also use the negative lags, even though they seem to violate causality, are the potential temporal uncertainties of the reanalysis data.
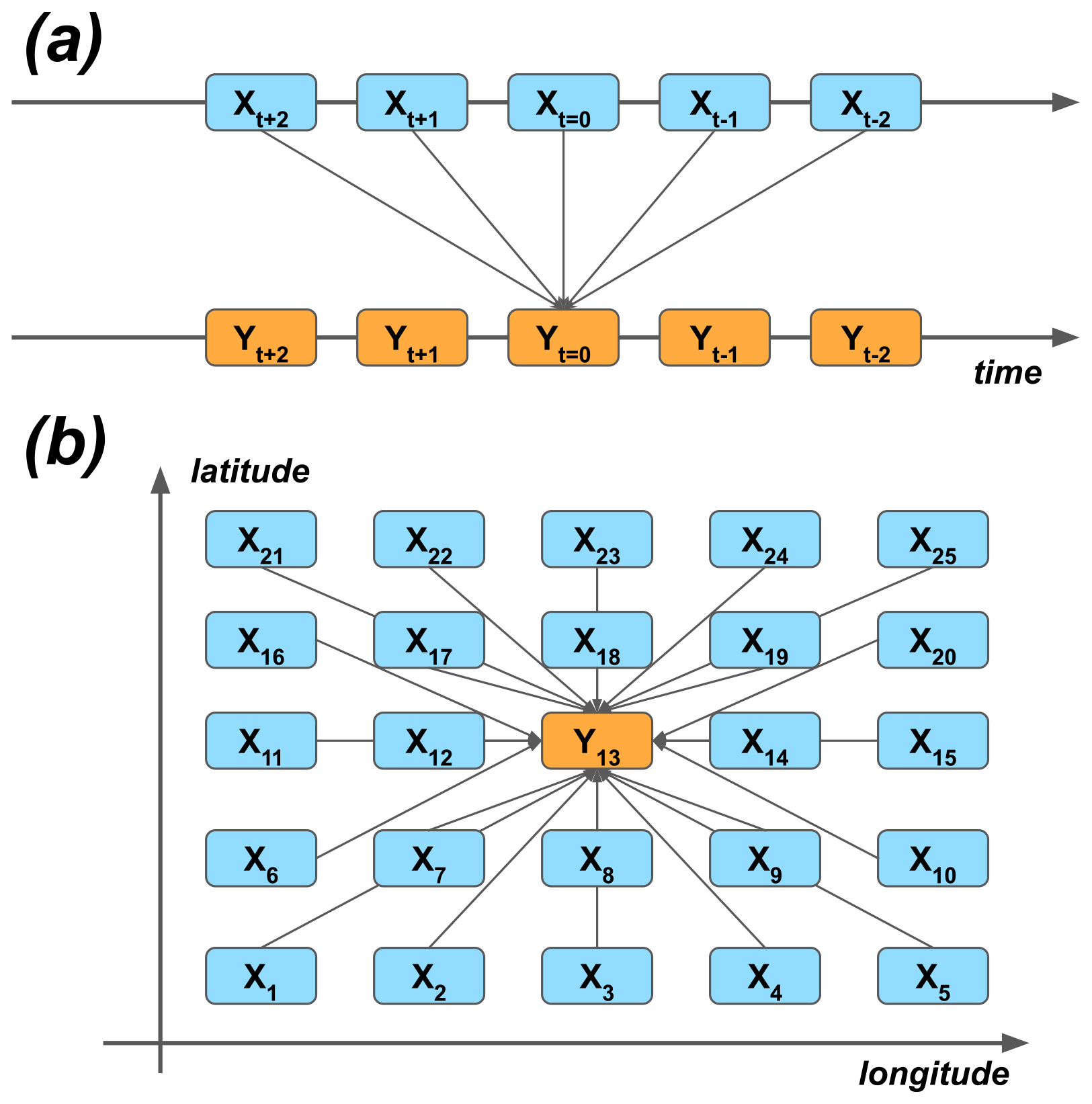
Figure 2The principle of using (a) temporal lagging and (b) spatial neighborhoods of predictor variables X to model the target variable Y. The numbering of the (a) lags and (b) grid cells corresponds to the lags and neighbors of the ERA5 data used in the study.
In total, we had 19 variables × 25 grid cells × 5 temporal lags = 2375 individual predictors for modeling. Technically, calculation of the correlation matrix was too laborious a task with 23752 ≈ 5.6 × 106 operations. However, the predictor set necessarily contains highly correlated variables: for example, the temperature time series of neighboring grid cells are correlated. Such collinearity can hamper the robustness and reliability of statistical models (Lavery et al., 2019). To deal with the collinearity, the principal component analysis method (Jolliffe and Cadima, 2016) using (1) all components and (2) reduced number of components was tested as a preprocessing step to make the predictors orthogonal, i.e., non-correlated, but it was found that this dimension reduction method was unnecessary, as the results were slightly better without it (not shown), and thus it was not used here.
2.4 Gradient boosting and random forest regressions
For the machine learning of this study, the xgboost package (version 1.4.2: https://xgboost.readthedocs.io/; Chen and Guestrin, 2016) of the Python language (v. 3.7.6: https://www.python.org/) was used to fit both the GB and the RF regression models.
Compared to, for example, deep learning methods, GB and RF models can fit properly with relatively small data sets, do not necessarily require graphical processing units to fit fast, have only a small set of tunable hyperparameters, and do not require heavy preprocessing of the predictor or the target data, such as removal of seasonality. In other words, they are generally easier to use. That said, one preprocessing step was found to improve modeling accuracy: quantile transformation with 105 quantiles was used to make the target variable, i.e., the CO2 flux, strictly Gaussian distributed. Validation of the model was then performed using the inverse transformed (non-Gaussian) flux data. The reason for the better results with the Gaussian transformed data is likely the better modeling of the non-extreme values and the use of the RMSE as a cost function, which penalizes highly the erroneous extremes: as the great majority of the data is non-extreme, even a slight enhancement of simulation of the “major bulk” of the data can lead to overall skill improvements – despite the potentially less accurate simulation of the tails.
Both the GB and the RF are ensemble-based tree methods, which means that the final prediction of the model is formed by calculating the mean of weak learners, trees, constituting the ensemble. Variation between the ensemble members is created by fitting the members to random subsamples of the predictor matrix X: these subsamples are formed by sampling randomly both the predictor and the time step dimensions. While the members of the RF are just the trees fitted independently to different subsamples, the GB takes an additional step by fitting the models hierarchically one by one, such that each member tree reduces the prediction error of the previous one. In other words, each new member is forced to concentrate on those observations that are the most difficult to predict correctly (chap. 10 in Hastie et al., 2009), and in this sense, GB learns more than the RF.
2.5 Cross-validation framework, Bayesian parameter tuning, and validation metrics
Repeated K-fold cross-validation with shuffling and R = 8 repeats, each divided to K = 5 folds was used to fit separate ensemble models such that each of the models has its own validation set, and the remaining data were used to fit the model (Hawkins et al., 2003). The validation sets of the five splits together comprise a continuous time series covering all time steps in 1996–2018, and the eight repeats together comprise an ensemble of modeled realizations of the data. We use the ensemble mean over the eight realizations as the best-guess surrogate for the modeled time series.
As an important variation to the standard repeated K-fold cross-validation method, we randomly sampled years instead of individual time steps. Sampling randomly time steps would lead to sampling from the same weather events, i.e., from serially correlated data, which would lead to overestimation of the model accuracy in the validation (Roberts et al., 2017). This can be avoided by sampling sufficiently large, continuous blocks in time, such as years.
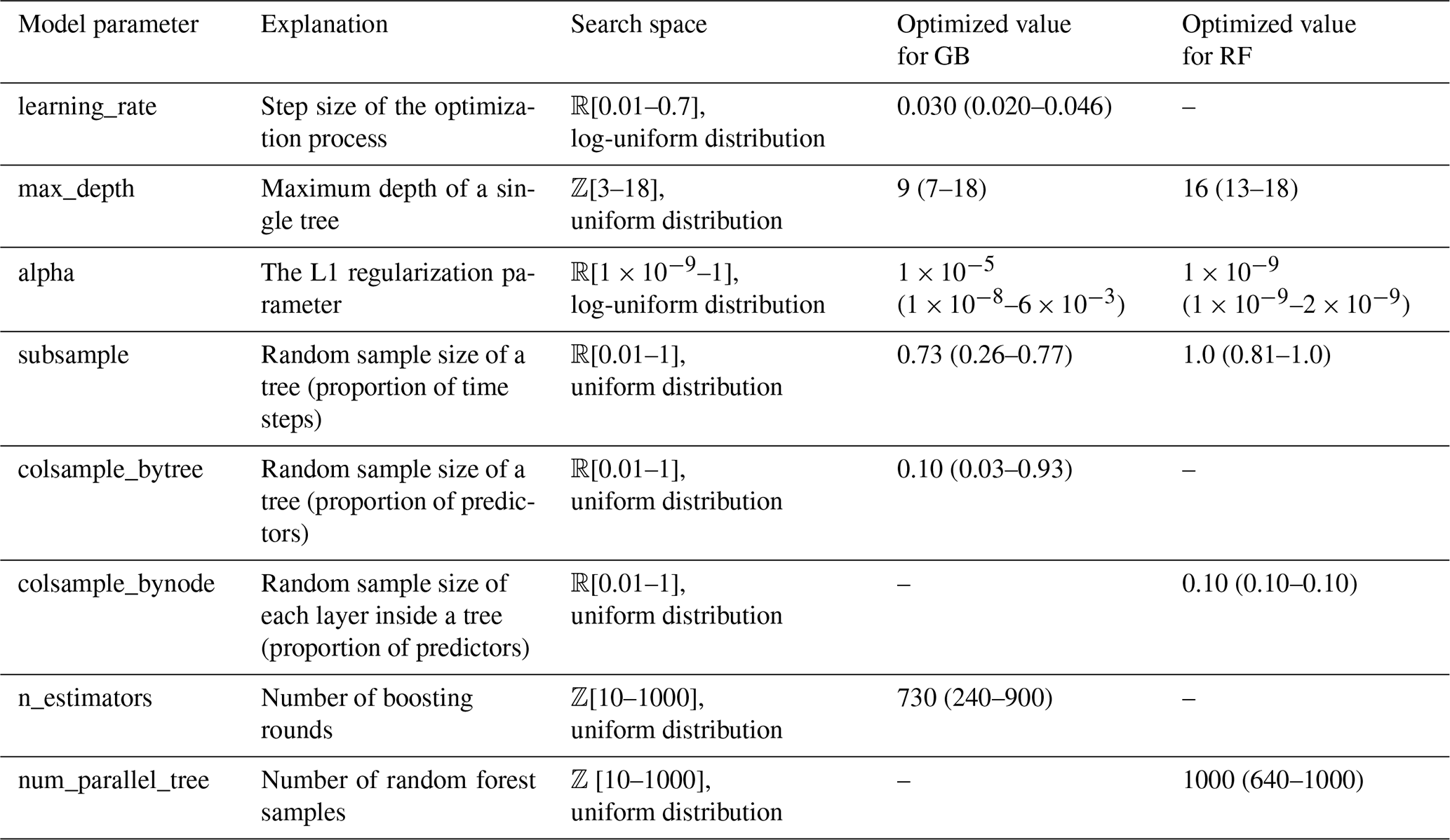
For the Bayesian optimization of the hyperparameters, the BayesSearchCV algorithm of the Scikit-Optimize package was used (version 0.9.0, https://scikit-optimize.github.io/; Snoek et al., 2012). In the Gaussian process-based optimization of the algorithm, an implicit 5-fold cross-validation with 50 iterations has been used for each of the K = 5 folds of the data set. Because of the computational costs, only the first repeat of the cross-validation was used. For the remainder of repeats, R = [2…8], the medians of the optimized parameters were used in fitting. The tuned hyperparameters of the models and their search spaces are listed in Table 2.
For measuring the goodness of fit of the validation samples in the cross-validation, the coefficient of determination (R2 score), the root mean squared error (RMSE), and the Pearson correlation coefficient have been used as metrics of model skill, and they were calculated from the 6 h and weekly data separately.
Table 2Optimized hyperparameters of the GB and RF regression models. The root mean squared error was used as the cost function in the Bayesian optimization. Constant default values of other model parameters were used, and they are not presented here. Identified median values of parameters, and minima and maxima inside brackets, are shown.
2.6 SHAP value analysis for measuring the predictor importance
The Tree SHapley Additive exPlanations (Tree SHAP; version 0.41.0, https://shap.readthedocs.io; Lundberg et al., 2020) is a toolbox for calculating and visualizing predictor importance. Compared to many other metrics of measuring the importance, such as the gain parameter of the XGBoost, SHAP values are both consistent and accurate, and therefore more robust (Lundberg et al., 2020). SHAP values were calculated from the validation samples of the models.
2.7 Subsampling for artificial reduction of fitting data
Additional subsampling with sample sizes of 10 %, 20 %, …, 100 % were used to resample the data within each fold of the cross-validation to give the models less data to learn from. This allows us to measure the sensitivity of the modeling to the amount of fitting data.
The subsampling was implemented with two different strategies. First, the ordinary random sampling was used. This strategy mimics cases in which the time series of a site is incomplete, i.e., contains missing observations randomly distributed over the study period. Second, non-random sampling was used to study those cases in which the study period is shorter but more complete, implemented by using the same percentage shares as with the random sampling but selecting continuous blocks of data from the beginning of the cross-validation samples.
3.1 Goodness of fit of the machine learning approaches
For the 6 h GB data, the 95 % confidence intervals (CIs), based on bootstrapping with 1000 samples, were 0.910–0.920 for R2, 1.13–1.20 µmol m−2 s−1 for RMSE, and 0.956–0.961 for correlation (Fig. 3). For the weekly GB data, the 95 % CIs were 0.963–0.966, 0.458–0.483 µmol m−2 s−1, and 0.981–0.983 for R2, RMSE, and correlation, respectively. The RF performance was also good but did not reach the GB skill, as the CIs for the 6 h (weekly) data were 0.877–0.891 (0.951–0.955) for R2, 1.26–1.33 µmol m−2 s−1 (0.510–0.535 µmol m−2 s−1) for RMSE, and 0.946–0.952 (0.978–0.980) for correlation, respectively.

Figure 3Two-dimensional probability density histograms of the 6 h (a, b) and weekly mean (c, d) observed and cross-validated modeled CO2 fluxes (GB shown in a, c; RF in b, d). Color shading indicates qualitatively the density of the observed–modeled value pairs inside each pixel. Bootstrap-estimated medians of R2 scores, Pearson correlation coefficients, and the root mean square errors of the fit are also shown. See text for the confidence limits of these values.
To study the accuracy of modeling without the seasonal and diurnal cycles, monthly and 6 h grouping were used simultaneously, and all three quality metrics were calculated for these groups for the GB algorithm (Fig. 4a). This analysis reveals how much the high skill reached in the analysis of the complete time series (Fig. 3) is actually attributable to the modeling of the two important temporal cycles. The lowest correlation was found in August at 00:00 UTC (correlation is 0.43, 95 % CIs 0.40–0.50) and the highest in April at 06:00 UTC (0.85, 0.83–0.86). In general, the small absolute values of the flux in general increase the correlation uncertainty in winter, and on the other hand, the largest variation of the target variable in summer daytime (06:00–12:00 UTC, 09:00–15:00 LT) yields the largest RMSE, even though the correlation peaks at the same time.

Figure 4Estimates of the root mean square error (upper panels), the Pearson correlation coefficient (center panels), and the R2 score (bottom panels) derived from the eight repeated representations of the cross-validated time series. (a) Monthly and 6 h decompositions of RMSE, correlation, and R2 for GB. Median values of quantities are shown, calculated from differently repeated cross-validation experiments. (b) Annual variability of RMSE, correlation, and R2 for the RF and GB: variability shown in boxes was calculated from differently repeated cross-validation experiments. Median is shown with a horizontal line in the center of each box. Quartiles are shown with box edges and minima/maxima with whiskers. Years with more than 40 % of missing data were excluded.
When excluding the winter months, the daytime NEE was better predicted (R2 is 0.42 to 0.68) than the nighttime (R2 is −0.04 to 0.54). Interestingly, an opposite result was achieved when the raw CO2 flux was modeled instead of the preprocessed NEE: in that case, the nighttime (18:00–00:00 UTC) fluxes were better predicted than the morning and afternoon fluxes (not shown). Analysis of the results of the different target data implies that the sampling error emerging from a rather large share of missing samples in the raw NEE data could explain the differences.
Additionally, annual grouping of the data was used to obtain annual estimates of R2, correlation, and RMSE, and their confidence intervals for both ML algorithm results (Fig. 4b). In this case, the CIs were calculated from the distribution of the different repeats of the K-fold cross-validation. These estimates show an increasing temporal trend for R2 and correlation, implying either (1) a quality improvement in observed fluxes or (2) in the ERA5 predictor data over the years, or (3) changes in the environment as the forest grows. The highest R2 was achieved in 2015 (median R2 for GB is 0.936), and the lowest in 2000 (median R2 for GB is 0.829).
3.2 Temporal distribution of the fitting data affects the goodness of the fit
The time series of the CO2 flux observations in Hyytiälä are exceptionally long and complete in time. Therefore, it is interesting to study the sensitivity of modeling to the amount and distribution of fitting data to assess whether the methods could be used for sites with less data. For this, additional subsampling was used to reduce the amount of data prior to fitting of the models in the cross-validation framework.
The results indicate that the GB can cope better with less data compared to RF (Fig. 5). For example, when considering the non-random sampling, the GB achieves the same skill with 20 % data as the RF with 70 %. Additionally, R2 results reveal that the selection of the ML algorithm is more important in determining the goodness of fit of the result than the selection of the sampling strategy at each percentage level. The differences between random and non-random sampling results also indicate that lengthening the time series by adding more years to it might be a better strategy to further improve the model than gap-filling the missing values in the existing observational time series. This can be seen in the larger changes in the non-random sampling results as the amount of data increases: with the random sampling approach, the changes, and hence the algorithm improvements, become quite small with larger than 60 % amounts.
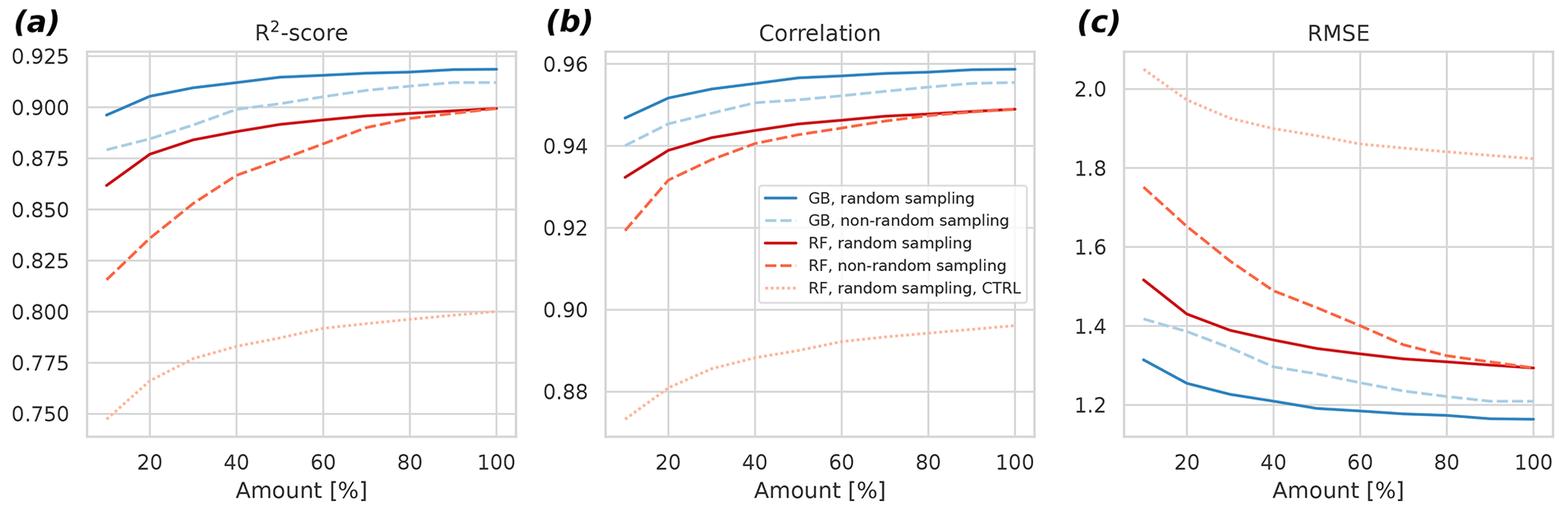
Figure 5Cross-validated R2 score (a), the Pearson correlation coefficient (b), and the root mean square error (c) as a function of the amount of fitting data for the gradient boosting approach (blue) and the random forest approach (red). Different subsampling approaches (random versus non-random) are also shown with different dashes. The control experiment – a fit without spatiotemporal neighbors – is shown for the random forest approach. The control for the gradient boosting fails to fit properly with the limited predictors, and it is not shown for this reason. Averages of 6 h were used in this experiment.
3.3 Analysis of predictor importance
For measuring the predictor importance, SHAP analysis was used. The SHAP implies the relative contribution of each predictor to the model, and it is calculated by measuring each predictor's contribution to each tree of the model. When comparing the predictors, a higher SHAP value implies that the predictor is more important for generating a prediction.
Figure 6 presents the different group means of the predictors in the 40 fitted GB models (which differ from each other by the cross-validation samples used in fitting). The panels (a)–(c) summarize the mean absolute SHAP results for different parameters, grid cells, and lags. The 2 m temperature turned out to be the most important of the input parameters. Also, the sensible heat flux, the relative humidity, the shortwave radiation, and the evaporation rate were among the most important predictors. They were followed by the soil temperature of the uppermost layer, the wind components, the latent heat flux, and the soil temperature of the third layer. The non-lagged variables were more important than the lagged ones, but perhaps surprisingly, the negatively lagged variables turned out to be as important as the positively lagged ones. Contrary to the time dimension, the nearest data point in the spatial dimensions did not contain the most important predictor data on average: the two most important cells, numbers one and five, locate at the bottom corners of the domain (Fig. 2b).
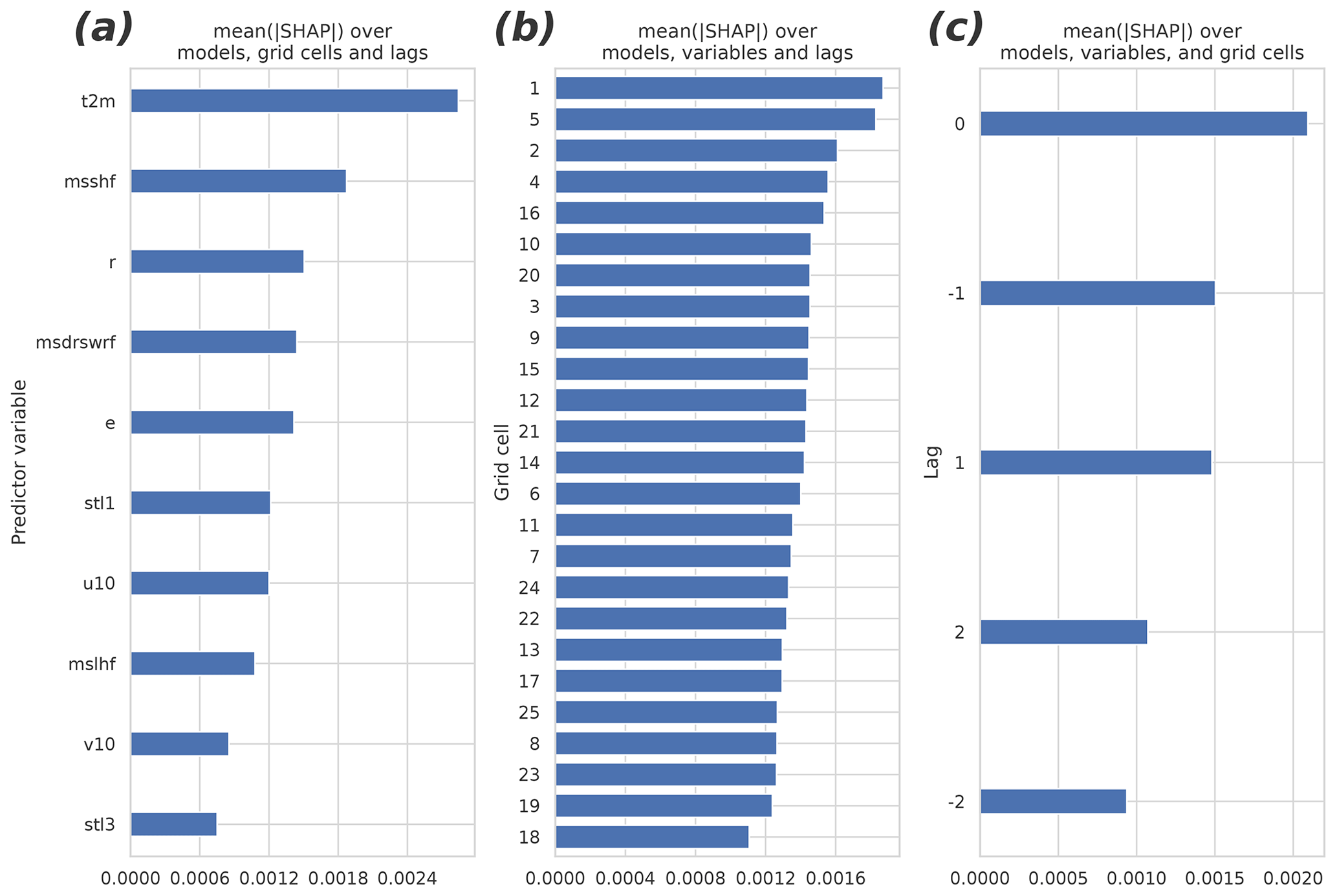
Figure 6The mean absolute SHAP values separated by (a) the predictor variable, (b) the grid cell, and (c) the temporal lag. The higher the value, the more important the predictor/cell/lag. The redundant predictors, shown in Table 1, were excluded from the analysis and from the final fit of the model. See Fig. 2 for the organization of the grid cells and temporal lags.
To study the overall relevance of the input variables, we conducted an experiment in which we excluded them one by one, beginning from the one with the least explanatory power (total cloud cover), and we measured the accuracy of GB after each drop until it started to decrease significantly. It turned out that half of the variables originally included were redundant, i.e., they did not improve the accuracy at all. Importantly however, they did not worsen the models significantly either. Soil moisture of the third layer was the first variable to add significant value to the models, and those with a smaller average gain could be discarded without major effects to the results. Among the all input variables, the top six – those placing above the 10 m u-wind component in Fig. 6a – were the ones to improve the model the most. Interestingly, using only the two most important variables, the 2 m temperature and the sensible heat flux, yielded a model with a relatively good accuracy (R2=0.87), corresponding to the best accuracy achieved with the RF model with all available predictors.
Many local factors affecting net CO2 exchange between the atmosphere and a boreal forest either vary only slowly over time, as is the case for the plant distribution and growth and soil microorganism populations, or are effectively constant (e.g., soil properties and shape of the terrain). In contrast, the variability of meteorological factors is prominent and happens in short timescales, and, partly for these reasons, dominates the variability of the flux response (Sierra et al., 2009). Indeed, the vast majority of the CO2 flux variation in the studied forest can be explained by using only meteorological factors, of which the most important ones were, in order, air temperature, sensible heat flux, relative humidity, shortwave radiation, evaporation rate, soil temperature, wind components, and latent heat flux. Out of all 19 variables included in the analysis, these are the ones which significantly contributed to the GB model skill. It is worth noting that some of the variables included in the analysis are not completely independent of the physical and biophysical processes: to some extent, many of them are regulated by the plants themselves and the environment in general. The most important of such variables are the latent and sensible heat fluxes, evaporation, relative humidity, and the near-surface temperature.
At least to some extent, if not completely, the ML methods employed here might be able to account for slow changes in the response happening over the years if (1) they are caused by the meteorological variables, and (2) the current period of the study contains clear enough signals of these changes. For example, the increasing trend in temperature is one of the most important variables explaining the CO2 variability both in the short and long term (Huntingford et al., 2017; Pulliainen et al., 2017). However, the presented methods cannot extrapolate cases in which the values of a predictor variable fall outside of the range used in fitting the models. It is likely that the temperature extremes exceed the observed variability in the near future along with the warming local and global climate. The sensitivity of the predicted NEE on the temperatures residing outside of the observed range remains unclear, but eventually, the ecosystem changes become so large that the accuracy of the method will necessarily deteriorate.
When interpreting the results, it is important to distinguish the conceptual difference between the negative and positive temporal lags. A strong correlation between the response variable and positively lagged predictor is an indicator of the predictor driving the CO2 flux, either directly or indirectly. A correlation between the flux and a negatively lagged predictor variable is more difficult to understand. It is likely that because of temporal biases and other inaccuracies in the gridded form of the variables, some of the negatively lagged predictors might better represent the relevant variability for modeling. Similarly, because of spatial biases, some of the neighboring grid cells might better represent the local conditions than the nearest cell: in our experiments, the most useful predictor variability was found in the bottom corner cells of the domain.
In general, machine learning methods seek for relationships between the response variable and the predictor data, and they cannot distinguish whether these relationships are truly causal. Even though the identified relationships and interaction mechanisms may not be intuitive and even causally coherent, they can still be used to improve the model accuracy. To be beneficial for the modeling, such a relationship just needs to be sufficiently robust and strong, and constant in time. Even though the predictor data set contained many redundant variables, the GB method gave them a low enough feature importance, and hence the cross-validated correlation remained high. The effectiveness of the GB in rejecting the irrelevant predictors and variability was also evident in the preprocessing: the principal component analysis, which often helps ML models to find the most important dimensions of the predictor data, did not improve the skill at all. In addition to this, the method proved to be skillful even in cases in which the amount of fitting samples was heavily reduced. With less powerful statistical methods, overfitting would be much more likely, leading to poorer cross-validation results when using redundant and/or collinear predictor variables and/or small fitting samples (chap. 7 in Wilks, 2011; chaps. 3 and 7 in Hastie et al., 2009; Lavery et al., 2019).
Both the efficiency of the GB method in omitting the non-optimal predictors and the ability to cope with small fitting samples are especially encouraging considering its application to other locations: all variables can be used, letting the model decide about the redundancy. It is likely that the same variables that were found important at our study site might not constitute an optimal choice in other ecosystems and locations; vice versa, the predictors found redundant in Hyytiälä, such as soil moisture, can be important in other environments (Nadal-Sala et al., 2021; Zhou et al., 2019).
This work could act as a first step in the creation of a multi-purpose, national, regional, or global flux model (Jung et al., 2020; Bodesheim et al., 2018), because (1) the meteorological predictors can explain almost all of the variability of the observed atmosphere–ecosystem NEE, (2) GB regression is efficient in modeling that variability, (3) NEE is measured globally at a large number of sites representing different climates and ecosystems (Hicks and Baldocchi, 2020), and (4) the meteorological variables, derived here from the ERA5 reanalysis, are easily and freely available globally in a spatially and temporally dense, complete, and homogeneous format, extending back to the 1950s. However, for that, a transformation of the model from modeling only one dimension (time) to modeling of three dimensions (time, latitude, longitude) would be necessary, requiring an abundant set of NEE observation samples representing different bioclimates, and additionally, spatial information about the biology and geography (vegetation, land properties, orography, latitude, etc.) of those locations would be needed to allow the model to learn the spatiotemporal relationships between the predictor variables and NEE. It is also worth noting that spatiotemporal structures that the models learn and utilize from the predictor neighborhoods of the meteorological data might not easily and directly translate to different locations.
Another more easily attainable application for the proposed spatiotemporal approach is to use it for gap-filling of the EC measurements of NEE, which are typically available in the half-hourly resolution (Pastorello et al., 2020). In that context, the spatiotemporal structures can be directly learned for each of the study sites separately. For gap-filling, the ERA5 data should be downloaded in the full 1 h resolution and resampled to half-hourly resolution. The applicability of the method in that time resolution remains to be tested, but as shown with the current experiments, it works well for gap-filling the NEE data in the 6 h time resolution. Compared to other studies of this kind, our results are promising in terms of the R2 skill (Irvin et al., 2021; Mahabbati et al., 2021).
As summarized in Fig. 5, the combination of novelties of this study, namely using GB, which excels in this context compared to RF, and using the spatiotemporal neighborhoods from the meteorological input data together yielded a high level of accuracy in modeling both the subdaily and weekly variability of the atmosphere–forest CO2 exchange. Even though the time series of our study were exceptionally long, the GB could cope with much shorter time series as well. As such, the approach is almost directly applicable to gap-filling of the observational NEE data. However, for application of the method in the multi-site context, new stationary predictors would be needed, and the accuracy of the model should be measured using, for example, a leave-one-site-out cross-validation strategy (Roberts et al., 2017).
The code for reproducing the results from experiments and analyses is available at https://doi.org/10.5281/zenodo.7333975 (Kämäräinen et al., 2022). The code can be used to download and preprocess also the ERA5 predictor data: other data, including NEE data, are included in the repository.
MKä designed the experiments and the structure and content of the paper, wrote and executed the code, and composed the text. ALi participated in the planning of the paper content, made major suggestions during the writing process, and helped significantly with the references. JPT contributed significantly to the content of the reference list and commented on the text. IM was responsible for the EC measurements at the study site. HV tested the code and made suggestions on how to improve it. MKu, JA, and ALo commented on the paper.
The contact author has declared that none of the authors has any competing interests.
Publisher’s note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
We thank two anonymous reviewers for their comments and suggestions to improve the paper. We thank the creators and maintainers of the ERA5 reanalysis for providing these invaluable data freely available for the research community. We also thank Hyytiälä SMEAR II staff, ICOS research infrastructure, and the responsible researchers for maintaining the eddy covariance data and providing it openly available online.
This research has been supported by the Academy of Finland (grant nos. 337549, 302958, 342890, 325656, 316114, 325647, and 347782), the Jane and Aatos Erkko Foundation (Quantifying carbon sink, CarbonSink+ and their interaction with air quality), the European Research Council, H2020 European Research Council (ATM-GTP (grant no. 742206)), and the Ministry of Agriculture and Forestry in Finland (grant no. VN/28443/2021-MMM-2, Catch the Carbon-program).
This paper was edited by Trevor Keenan and reviewed by two anonymous referees.
Alton, P. B.: Representativeness of global climate and vegetation by carbon-monitoring networks; implications for estimates of gross and net primary productivity at biome and global levels, Agr. Forest Meteorol., 290, 108017, https://doi.org/10.1016/j.agrformet.2020.108017, 2020.
Aubinet, M., Vesala, T., and Papale, D. (Eds.): Eddy Covariance: A Practical Guide to Measurement and Data Analysis, Springer Science+Business Media B.V, 438 pp., https://doi.org/10.1007/978-94-007-2351-1, 2012.
Besnard, S., Carvalhais, N., Arain, M. A., Black, A., Brede, B., Buchmann, N., Chen, J., Clevers, J. G. P. W., Dutrieux, L. P., Gans, F., Herold, M., Jung, M., Kosugi, Y., Knohl, A., Bewerly, L. E., Paul-Limoges, E., Lohila, A., Merbold, L., Roupsard, O., Valentini, R., Wolf, S., Zhang, X., and Reichstein, M.: Memory effects of climate and vegetation affecting net ecosystem CO2 fluxes in global forests, PLoS One, 14, e0213467, https://doi.org/10.1371/journal.pone.0211510, 2019.
Bodesheim, P., Jung, M., Gans, F., Mahecha, M. D., and Reichstein, M.: Upscaled diurnal cycles of land–atmosphere fluxes: a new global half-hourly data product, Earth Syst. Sci. Data, 10, 1327–1365, https://doi.org/10.5194/essd-10-1327-2018, 2018.
Bradshaw, C. J. A. and Warkentin, I. G.: Global estimates of boreal forest carbon stocks and flux, Global Planet. Change, 128, 24–30, https://doi.org/10.1016/j.gloplacha.2015.02.004, 2015.
Chen, T. and Guestrin, C.: XGBoost: A Scalable Tree Boosting System, in: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD ′16), 13–17 August 2016, KDD ′16: The 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, California, USA, 785–794, https://doi.org/10.1145/2939672.2939785, 2016.
Friedlingstein, P., O'Sullivan, M., Jones, M. W., Andrew, R. M., Hauck, J., Olsen, A., Peters, G. P., Peters, W., Pongratz, J., Sitch, S., Le Quéré, C., Canadell, J. G., Ciais, P., Jackson, R. B., Alin, S., Aragão, L. E. O. C., Arneth, A., Arora, V., Bates, N. R., Becker, M., Benoit-Cattin, A., Bittig, H. C., Bopp, L., Bultan, S., Chandra, N., Chevallier, F., Chini, L. P., Evans, W., Florentie, L., Forster, P. M., Gasser, T., Gehlen, M., Gilfillan, D., Gkritzalis, T., Gregor, L., Gruber, N., Harris, I., Hartung, K., Haverd, V., Houghton, R. A., Ilyina, T., Jain, A. K., Joetzjer, E., Kadono, K., Kato, E., Kitidis, V., Korsbakken, J. I., Landschützer, P., Lefèvre, N., Lenton, A., Lienert, S., Liu, Z., Lombardozzi, D., Marland, G., Metzl, N., Munro, D. R., Nabel, J. E. M. S., Nakaoka, S.-I., Niwa, Y., O'Brien, K., Ono, T., Palmer, P. I., Pierrot, D., Poulter, B., Resplandy, L., Robertson, E., Rödenbeck, C., Schwinger, J., Séférian, R., Skjelvan, I., Smith, A. J. P., Sutton, A. J., Tanhua, T., Tans, P. P., Tian, H., Tilbrook, B., van der Werf, G., Vuichard, N., Walker, A. P., Wanninkhof, R., Watson, A. J., Willis, D., Wiltshire, A. J., Yuan, W., Yue, X., and Zaehle, S.: Global Carbon Budget 2020, Earth Syst. Sci. Data, 12, 3269–3340, https://doi.org/10.5194/essd-12-3269-2020, 2020.
Friedman, J.: Greedy Function Approximation: A Gradient Boosting Machine, Ann. Stat., 29, 1189–1232, 2001.
Hastie, T., Tibshirani, R., and Friedman, J. (Eds.): The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd Edn., Springer Series in Statistics, 745 pp., https://doi.org/10.1007/978-0-387-84858-7, 2009.
Hawkins, D. M., Basak, S. C., and Mills, D.: Assessing model fit by cross-validation, J. Chem. Inf. Comp. Sci., 43, 579–586, https://doi.org/10.1021/ci025626i, 2003.
Hersbach, H., Bell, B., Berrisford, P., Hirahara, S., Horányi, A., Muñoz-Sabater, J., Nicolas, J., Peubey, C., Radu, R., Schepers, D., Simmons, A., Soci, C., Abdalla, S., Abellan, X., Balsamo, G., Bechtold, P., Biavati, G., Bidlot, J., Bonavita, M., De Chiara, G., Dahlgren, P., Dee, D., Diamantakis, M., Dragani, R., Flemming, J., Forbes, R., Fuentes, M., Geer, A., Haimberger, L., Healy, S., Hogan, R.J., Hólm, E., Janisková, M., Keeley, S., Laloyaux, P., Lopez, P., Lupu, C., Radnoti, G., de Rosnay, P., Rozum, I., Vamborg, F., Villaume, S., and Thépaut, J.-N.: Complete ERA5 from 1979: Fifth generation of ECMWF atmospheric reanalyses of the global climate. Copernicus Climate Change Service (C3S) Data Store (CDS) [data set], https://www.ecmwf.int/en/forecasts/dataset/ecmwf-reanalysis-v5 (last access: 17 March 2021), 2017.
Hersbach, H., Bell, B., Berrisford, P., Hirahara, S., Horányi, A., Muñoz-Sabater, J., Nicolas, J., Peubey, C., Radu, R., Schepers, D., Simmons, A., Soci, C., Abdalla, S., Abellan, X., Balsamo, G., Bechtold, P., Biavati, G., Bidlot, J., Bonavita, M., De Chiara, G., Dahlgren, P., Dee, D., Diamantakis, M., Dragani, R., Flemming, J., Forbes, R., Fuentes, M., Geer, A., Haimberger, L., Healy, S., Hogan, R. J., Hólm, E., Janisková, M., Keeley, S., Laloyaux, P., Lopez, P., Lupu, C., Radnoti, G., de Rosnay, P., Rozum, I., Vamborg, F., Villaume, S., and Thépaut, J. N.: The ERA5 global reanalysis, Q. J. Roy. Meteor. Soc., 146, 1999–2049, https://doi.org/10.1002/qj.3803, 2020.
Hicks, B. B. and Baldocchi, D. D.: Measurement of Fluxes Over Land: Capabilities, Origins, and Remaining Challenges, Bound.-Lay. Meteor., 177, 365–394, https://doi.org/10.1007/s10546-020-00531-y, 2020.
Huntingford, C., Atkin, O. K., Martinez-De La Torre, A., Mercado, L. M., Heskel, M. A., Harper, A. B., Bloomfield, K. J., O'Sullivan, O. S., Reich, P. B., Wythers, K. R., Butler, E. E., Chen, M., Griffin, K. L., Meir, P., Tjoelker, M. G., Turnbull, M. H., Sitch, S., Wiltshire, A., and Malhi, Y.: Implications of improved representations of plant respiration in a changing climate, Nat. Commun., 8, 1–11, https://doi.org/10.1038/s41467-017-01774-z, 2017.
Irvin, J., Zhou, S., McNicol, G., Lu, F., Liu, V., Fluet-Chouinard, E., Ouyang, Z., Knox, S. H., Lucas-Moffat, A., Trotta, C., Papale, D., Vitale, D., Mammarella, I., Alekseychik, P., Aurela, M., Avati, A., Baldocchi, D., Bansal, S., Bohrer, G., Campbell, D. I., Chen, J., Chu, H., Dalmagro, H. J., Delwiche, K. B., Desai, A. R., Euskirchen, E., Feron, S., Goeckede, M., Heimann, M., Helbig, M., Helfter, C., Hemes, K. S., Hirano, T., Iwata, H., Jurasinski, G., Kalhori, A., Kondrich, A., Lai, D. Y., Lohila, A., Malhotra, A., Merbold, L., Mitra, B., Ng, A., Nilsson, M. B., Noormets, A., Peichl, M., Rey-Sanchez, A. C., Richardson, A. D., Runkle, B. R., Schäfer, K. V., Sonnentag, O., Stuart-Haëntjens, E., Sturtevant, C., Ueyama, M., Valach, A. C., Vargas, R., Vourlitis, G. L., Ward, E. J., Wong, G. X., Zona, D., Alberto, M. C. R., Billesbach, D. P., Celis, G., Dolman, H., Friborg, T., Fuchs, K., Gogo, S., Gondwe, M. J., Goodrich, J. P., Gottschalk, P., Hörtnagl, L., Jacotot, A., Koebsch, F., Kasak, K., Maier, R., Morin, T. H., Nemitz, E., Oechel, W. C., Oikawa, P. Y., Ono, K., Sachs, T., Sakabe, A., Schuur, E. A., Shortt, R., Sullivan, R. C., Szutu, D. J., Tuittila, E. S., Varlagin, A., Verfaillie, J. G., Wille, C., Windham-Myers, L., Poulter, B., and Jackson, R. B.: Gap-filling eddy covariance methane fluxes: Comparison of machine learning model predictions and uncertainties at FLUXNET-CH4 wetlands, Agr. Forest Meteorol., 308–309, 108528, https://doi.org/10.1016/j.agrformet.2021.108528, 2021.
Jolliffe, I. T. and Cadima, J.: Principal component analysis: A review and recent developments, Philos. T. R. Soc. A, 374, 20150202, https://doi.org/10.1098/rsta.2015.0202, 2016.
Jung, M., Schwalm, C., Migliavacca, M., Walther, S., Camps-Valls, G., Koirala, S., Anthoni, P., Besnard, S., Bodesheim, P., Carvalhais, N., Chevallier, F., Gans, F., Goll, D. S., Haverd, V., Köhler, P., Ichii, K., Jain, A. K., Liu, J., Lombardozzi, D., Nabel, J. E. M. S., Nelson, J. A., O'Sullivan, M., Pallandt, M., Papale, D., Peters, W., Pongratz, J., Rödenbeck, C., Sitch, S., Tramontana, G., Walker, A., Weber, U., and Reichstein, M.: Scaling carbon fluxes from eddy covariance sites to globe: synthesis and evaluation of the FLUXCOM approach, Biogeosciences, 17, 1343–1365, https://doi.org/10.5194/bg-17-1343-2020, 2020.
Kolari, P., Lappalainen, H. K., Hänninen, H., and Hari, P.: Relationship between temperature and the seasonal course of photosynthesis in Scots pine at northern timberline and in southern boreal zone, Tellus B, 59, 542–552, https://doi.org/10.1111/j.1600-0889.2007.00262.x, 2007.
Kämäräinen, M., Lintunen, A., Kulmala, M., Tuovinen, J., Mammarella, I., Aalto, J., Vekuri, H., and Lohila, A.: Gradient boosting and random forest tools for modeling the NEE 2022, Zenodo [code], https://doi.org/10.5281/zenodo.7333975, 2022.
Launiainen, S., Katul, G. G., Leppä, K., Kolari, P., Aslan, T., Grönholm, T., Korhonen, L., Mammarella, I., and Vesala, T.: Does growing atmospheric CO2 explain increasing carbon sink in a boreal coniferous forest?, Glob. Change Biol., 28, 2910–2929, https://doi.org/10.1111/gcb.16117, 2022.
Lavery, M. R., Acharya, P., Sivo, S. A., and Xu, L.: Number of predictors and multicollinearity: What are their effects on error and bias in regression?, Commun. Stat.-Simul. C., 48, 27–38, https://doi.org/10.1080/03610918.2017.1371750, 2019.
Lundberg, S. M. and Lee, S.-I.: A unified approach to interpreting model predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS'17), Curran Associates Inc., Red Hook, NY, USA, 4768–4777, 2017.
Lundberg, S. M., Erion, G., Chen, H., DeGrave, A., Prutkin, J. M., Nair, B., Katz, R., Himmelfarb, J., Bansal, N., and Lee, S.-I.: From local explanations to global understanding with explainable AI for trees, Nat. Mach Intell., 2, 56–67, https://doi.org/10.1038/s42256-019-0138-9, 2020.
Mahabbati, A., Beringer, J., Leopold, M., McHugh, I., Cleverly, J., Isaac, P., and Izady, A.: A comparison of gap-filling algorithms for eddy covariance fluxes and their drivers, Geosci. Instrum. Method. Data Syst., 10, 123–140, https://doi.org/10.5194/gi-10-123-2021, 2021.
Mammarella, I., Peltola, O., Nordbo, A., Järvi, L., and Rannik, Ü.: Quantifying the uncertainty of eddy covariance fluxes due to the use of different software packages and combinations of processing steps in two contrasting ecosystems, Atmos. Meas. Tech., 9, 4915–4933, https://doi.org/10.5194/amt-9-4915-2016, 2016.
Nadal-Sala, D., Grote, R., Birami, B., Lintunen, A., Mammarella, I., Preisler, Y., Rotenberg, E., Salmon, Y., Tatarinov, F., Yakir, D., and Ruehr, N. K.: Assessing model performance via the most limiting environmental driver in two differently stressed pine stands, Ecol. Appl., 31, 1–16, https://doi.org/10.1002/eap.2312, 2021.
Pastorello, G., Trotta, C., Canfora, E., Chu, H., Christianson, D., Cheah, Y. W., Poindexter, C., Chen, J., Elbashandy, A., Humphrey, M., Isaac, P., Polidori, D., Ribeca, A., van Ingen, C., Zhang, L., Amiro, B., Ammann, C., Arain, M. A., Ardö, J., Arkebauer, T., Arndt, S. K., Arriga, N., Aubinet, M., Aurela, M., Baldocchi, D., Barr, A., Beamesderfer, E., Marchesini, L. B., Bergeron, O., Beringer, J., Bernhofer, C., Berveiller, D., Billesbach, D., Black, T. A., Blanken, P. D., Bohrer, G., Boike, J., Bolstad, P. V., Bonal, D., Bonnefond, J. M., Bowling, D. R., Bracho, R., Brodeur, J., Brümmer, C., Buchmann, N., Burban, B., Burns, S. P., Buysse, P., Cale, P., Cavagna, M., Cellier, P., Chen, S., Chini, I., Christensen, T. R., Cleverly, J., Collalti, A., Consalvo, C., Cook, B. D., Cook, D., Coursolle, C., Cremonese, E., Curtis, P. S., D'Andrea, E., da Rocha, H., Dai, X., Davis, K. J., De Cinti, B., de Grandcourt, A., De Ligne, A., De Oliveira, R. C., Delpierre, N., Desai, A. R., Di Bella, C. M., di Tommasi, P., Dolman, H., Domingo, F., Dong, G., Dore, S., Duce, P., Dufrêne, E., Dunn, A., Dušek, J., Eamus, D., Eichelmann, U., ElKhidir, H. A. M., Eugster, W., Ewenz, C. M., Ewers, B., Famulari, D., Fares, S., Feigenwinter, I., Feitz, A., Fensholt, R., Filippa, G., Fischer, M., Frank, J., Galvagno, M., Gharun, M., Gianelle, D., Gielen, B., Gioli, B., Gitelson, A., Goded, I., Goeckede, M., Goldstein, A. H., Gough, C. M., Goulden, M. L., Graf, A., Griebel, A., Gruening, C., Grünwald, T., Hammerle, A., Han, S., Han, X., Hansen, B. U., Hanson, C., Hatakka, J., He, Y., Hehn, M., Heinesch, B., Hinko-Najera, N., Hörtnagl, L., Hutley, L., Ibrom, A., Ikawa, H., Jackowicz-Korczynski, M., Janouš, D., Jans, W., Jassal, R., Jiang, S., Kato, T., Khomik, M., Klatt, J., Knohl, A., Knox, S., Kobayashi, H., Koerber, G., Kolle, O., Kosugi, Y., Kotani, A., Kowalski, A., Kruijt, B., Kurbatova, J., Kutsch, W. L., Kwon, H., Launiainen, S., Laurila, T., Law, B., Leuning, R., Li, Y., Liddell, M., Limousin, J.-M., Lion, M., Liska, A. J., Lohila, A., López-Ballesteros, A., López-Blanco, E., Loubet, B., Loustau, D., Lucas-Moffat, A., Lüers, J., Ma, S., Macfarlane, C., Magliulo, V., Maier, Regine Mammarella, I., Manca, G., Marcolla, B., Margolis, H. A., Marras, S., Massman, W., Mastepanov, M., Matamala, R., Matthes, J. H., Mazzenga, F., McCaughey, H., McHugh, I., McMillan, A. M. S., Merbold, L., Meyer, W., Meyers, T., Miller, S. D., Minerbi, S., Moderow, U., Monson, R. K., Montagnani, L., Moore, C. E., Moors, E., Moreaux, V., Moureaux, C., Munger, J. W., Nakai, T., Neirynck, J., Nesic, Z., Nicolini, G., Noormets, A., Northwood, M., Nosetto, M., Nouvellon, Y., Novick, K., Oechel, W., Olesen, J. E., Ourcival, J.-M., Papuga, S. A., Parmentier, F.-J., Paul-Limoges, E., Pavelka, M., Peichl, M., Pendall, E., Phillips, R. P., Pilegaard, K., Pirk, N., Posse, G., Powell, T., Prasse, H., Prober, S. M., Rambal, S., Rannik, Ü., Raz-Yaseef, N., Rebmann, C., Reed, D., Dios, V. R. d., Restrepo-Coupe, N., Reverter, B. R., Roland, M., Sabbatini, S., Sachs, T., Saleska, S. R., Sánchez-Cañete, E. P., Sanchez-Mejia, Z. M., Schmid, H. P., Schmidt, M., Schneider, K., Schrader, F., Schroder, I., Scott, R. L., Sedlák, P., Serrano-Ortíz, P., Shao, C., Shi, P., Shironya, I., Siebicke, L., Šigut, L., Silberstein, R., Sirca, C., Spano, D., Steinbrecher, R., Stevens, R. M., Sturtevant, C., Suyker, A., Tagesson, T., Takanashi, S., Tang, Y., Tapper, N., Thom, J., Tomassucci, M., Tuovinen, J.-P., Urbanski, S., Valentini, R., van der Molen, M., van Gorsel, E., van Huissteden, K., Varlagin, A., Verfaillie, J., Vesala, T., Vincke, C., Vitale, D., Vygodskaya, N., Walker, J. P., Walter-Shea, E., Wang, H., Weber, R., Westermann, S., Wille, C., Wofsy, S., Wohlfahrt, G., Wolf, S., Woodgate, W., Li, Y., Zampedri, R., Zhang, J., Zhou, G., Zona, D., Agarwal, D., Biraud, S., Torn, M., and Papale, D.: The FLUXNET2015 dataset and the ONEFlux processing pipeline for eddy covariance data, Sci. Data, 7, 225, https://doi.org/10.1038/s41597-020-0534-3, 2020.
Parker, W. S.: Reanalyses and observations: What's the Difference?, B. Am. Meteorol. Soc., 97, 1565–1572, https://doi.org/10.1175/BAMS-D-14-00226.1, 2016.
Pulliainen, J., Aurela, M., Laurila, T., Aalto, T., Takala, M., Salminen, M., Kulmala, M., Barr, A., Heimann, M., Lindroth, A., Laaksonen, A., Derksen, C., Mäkelä, A., Markkanen, T., Lemmetyinen, J., Susiluoto, J., Dengel, S., Mammarella, I., Tuovinen, J. P., and Vesala, T.: Early snowmelt significantly enhances boreal springtime carbon uptake, P. Natl. Acad. Sci. USA, 114, 11081–11086, https://doi.org/10.1073/pnas.1707889114, 2017.
Reitz, O., Graf, A., Schmidt, M., Ketzler, G., and Leuchner, M.: Upscaling Net Ecosystem Exchange Over Heterogeneous Landscapes With Machine Learning, J. Geophys. Res.-Biogeo., 126, 1–16, https://doi.org/10.1029/2020JG005814, 2021.
Roberts, D. R., Bahn, V., Ciuti, S., Boyce, M. S., Elith, J., Guillera-Arroita, G., Hauenstein, S., Lahoz-Monfort, J. J., Schröder, B., Thuiller, W., Warton, D. I., Wintle, B. A., Hartig, F., and Dormann, C. F.: Cross-validation strategies for data with temporal, spatial, hierarchical, or phylogenetic structure, Ecography, 40, 913–929, https://doi.org/10.1111/ecog.02881, 2017.
Shi, H., Luo, G., Hellwich, O., Xie, M., Zhang, C., Zhang, Y., Wang, Y., Yuan, X., Ma, X., Zhang, W., Kurban, A., De Maeyer, P., and Van de Voorde, T.: Variability and uncertainty in flux-site-scale net ecosystem exchange simulations based on machine learning and remote sensing: a systematic evaluation, Biogeosciences, 19, 3739–3756, https://doi.org/10.5194/bg-19-3739-2022, 2022.
Sierra, C. A., Loescher, H. W., Harmon, M. E., Richardson, A. D., Hollinger, D. Y., and Perakis, S. S.: Interannual variation of carbon fluxes from three contrasting evergreen forests: The role of forest dynamics and climate, Ecology, 90, 2711–2723, https://doi.org/10.1890/08-0073.1, 2009.
Snoek, J., Larochelle, H., and Adams, R. P.: Practical Bayesian Optimization of Machine Learning Algorithms, Adv. Neur. In., 25, 2960–2968, https://doi.org/10.1163/15685292-12341254, 2012.
Tramontana, G., Ichii, K., Camps-Valls, G., Tomelleri, E., and Papale, D.: Uncertainty analysis of gross primary production upscaling using Random Forests, remote sensing and eddy covariance data, Remote Sens. Environ., 168, 360–373, https://doi.org/10.1016/j.rse.2015.07.015, 2015.
Tramontana, G., Jung, M., Schwalm, C. R., Ichii, K., Camps-Valls, G., Ráduly, B., Reichstein, M., Arain, M. A., Cescatti, A., Kiely, G., Merbold, L., Serrano-Ortiz, P., Sickert, S., Wolf, S., and Papale, D.: Predicting carbon dioxide and energy fluxes across global FLUXNET sites with regression algorithms, Biogeosciences, 13, 4291–4313, https://doi.org/10.5194/bg-13-4291-2016, 2016.
Ueyama, M., Iwata, H., Harazono, Y., Euskirchen, E. S., Oechel, W. C., and Zona, D.: Growing season and spatial variations of carbon fluxes of Arctic and boreal ecosystems in Alaska (USA), Ecol. Appl., 23, 1798–1816, https://doi.org/10.1890/11-0875.1, 2013.
Wilks, D.: Statistical methods in the atmospheric sciences, 3rd Edn., edited by: Dmowska, R., Hartmann, D., and Rossby, H. T., Elsevier Inc., Oxford, 676 pp., https://doi.org/10.1016/B978-0-12-385022-5.00001-4, 2011.
Wu, S. H., Jansson, P. E., and Kolari, P.: The role of air and soil temperature in the seasonality of photosynthesis and transpiration in a boreal Scots pine ecosystem, Agr. Forest Meteorol., 156, 85–103, https://doi.org/10.1016/j.agrformet.2012.01.006, 2012.
Zhou, Q., Fellows, A., Flerchinger, G. N., and Flores, A. N.: Examining Interactions Between and Among Predictors of Net Ecosystem Exchange: A Machine Learning Approach in a Semi-arid Landscape, Sci. Rep., 9, 1–11, https://doi.org/10.1038/s41598-019-38639-y, 2019.