the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 30 Mar 2020
| 30 Mar 2020
An analysis of forest biomass sampling strategies across scales
Jessica Hetzer
Andreas Huth
Thorsten Wiegand
Hans Jürgen Dobner
Rico Fischer
Tropical forests play an important role in the global carbon cycle as they store a large amount of carbon in their biomass. To estimate the mean biomass of a forested landscape, sample plots are often used, assuming that the biomass of these plots represents the biomass of the surrounding forest.
In this study, we investigated the conditions under which a limited number of sample plots conform to this assumption. Therefore, the minimum number of sample sizes for predicting the mean biomass of tropical forest landscapes was determined by combining statistical methods with simulations of sampling strategies. We examined forest biomass maps of Barro Colorado Island (50 ha), Panama (50 000 km2), and South America, Africa, and Southeast Asia (3 × 106–11 × 106 km2).
The results showed that around 100 plots (1–25 ha each) are necessary for continent-wide biomass estimations if the sampled plots are randomly distributed. However, locations of current inventory plots often do not meet this requirement, for example, as their sampling design is based on spatial transects among climatic gradients. We show that these nonrandom locations lead to a much higher sampling intensity being required (up to 54 000 plots for accurate biomass estimates for South America). The number of sample plots needed can be reduced using large distances (5 km) between the plots within transects.
We also applied novel point pattern reconstruction methods to account for aggregation of inventory plots in known forest plot networks. The results implied that current plot networks can have clustered structures that reduce the accuracy of large-scale estimates of forest biomass if no further statistical approach is applied. To establish more reliable biomass predictions across South American tropical forests, we recommend more spatially randomly distributed inventory plots (minimum: 100 plots) and ensuring that the analyses of inventory plot data consider their spatial characteristics. The precision of forest attribute estimates depends on the sampling intensity and strategy.
- Article
(1516 KB) - Full-text XML
-
Supplement
(559 KB) - BibTeX
- EndNote





For a better understanding of the global carbon cycle, reliable estimations of aboveground biomass (AGB) in vegetation have become increasingly important (Broich et al., 2009; Malhi et al., 2006; Marvin et al., 2014), especially for tropical forests, as they store more carbon in biomass than any other terrestrial ecosystem (Pan et al., 2011). Current biomass mapping approaches are based on forest field inventory plots (e.g., Chave et al., 2003; Lewis et al., 2004; Malhi et al., 2006; Mitchard et al., 2014) or remote sensing measurements (e.g., Asner et al., 2013; Avitabile et al., 2016; Baccini et al., 2012; Saatchi et al., 2015) and involve statistical approaches (e.g., Malhi et al., 2006) or vegetation modeling (e.g., Rödig et al., 2017). Remote-sensing-derived maps have a typical spatial resolution of 100–1000 m and capture the biomass of large landscapes or even entire continents (Asner et al., 2013; Avitabile et al., 2016; Baccini et al., 2012; Saatchi et al., 2011). In contrast, biomass maps based on field inventories have a higher resolution so that the local distribution in biomass can be described in detail.
However, the biomass estimation of large forest landscapes by field inventory plots (typically between 0.25 and 1 ha) poses several challenges in the tropics. Firstly, field inventory campaigns of species-rich, densely grown tropical forests are costly and labor intensive, resulting in a much smaller number of available plots than in temperate and boreal regions (Schimel et al., 2015). Currently, tropical forests are sampled with less than one plot per 1000 km2: a density that is up to 15 times less than those that can be found in the temperate zone (Schimel et al., 2015). For instance, the US national forest inventory includes more than 125 000 forest plots (Smith, 2002). This corresponds to 40 plots per 1000 km2. In contrast, investigations of the South American Amazonian forest are often based on fewer than 500 forest plots (0.05 plots per 1000 km2) (Lopez-Gonzalez et al., 2014; Mitchard et al., 2014) including a highly debated sampling error (Marvin et al., 2014; Mitchard et al., 2014; Saatchi et al., 2015).
Secondly, establishments of forest plots are often limited mainly due to topographic, logistic, or political reasons (Houghton et al., 2009; Mitchard et al., 2014). Even if plots are representative for the landscapes (Anderson et al., 2009), extrapolations from clustered plot networks to larger scales can be biased (Fisher et al., 2008). Consequently, biomass estimations can include large uncertainties; for example, estimates of the total biomass of the Amazon (93±23 PgC, based on 227 forest plots) include uncertainties of more than 25 % (Malhi et al., 2006).
A first step to ensure reliable extrapolations of forest biomass from field plots to large scales is to determine how many plots would be necessary to accurately estimate mean biomass on a regional scale. Previous studies have suggested that, for regions of about 1000 ha, 10–100 sampled 1 ha plots would be necessary (Marvin et al., 2014). However, most investigations assume that plots or biomass is distributed randomly in space (Chave et al., 2004; Fisher et al., 2008; Keller et al., 2015; Marvin et al., 2014) and therefore do not consider a possible bias due to the choice of sampling strategy. The selected sampling design can significantly influence uncertainty and, consequently, the number of sample plots required (Clark and Kellner, 2012). A deeper understanding of how the choice of sampling design affects the number of plots required and the influence of the size of the plots is still lacking.
In this study, we present a novel simulation approach for determining the number of plots necessary across scales, answering the following questions: (i) how many sample plots are necessary for forest biomass estimations in South America, and what is the role of the sampling strategy? (ii) What is the influence of scale on the sampling design?
More specifically, we analyze different sampling strategies for biomass in tropical forests at different scales: 50 ha (Barro Colorado Island, BCI), 50 000 km2 (Panama; Asner et al., 2013), and 11 × 106 km2 (South America; Baccini et al., 2012). Following the scenario of a “virtual ecologist” (Zurell et al., 2010), we investigate through Monte Carlo simulations and analytical investigations the plot size and sample size that are necessary for accurate biomass estimations. Furthermore, we simulate nonrandom sampling strategies that imitate measurements of transects and real-world forest inventories.
2.1 Biomass maps at different scales
We focus on three forest biomass datasets for the South American tropical region covering different scales (Fig. 1). For an analysis at the local scale, a biomass map of the Barro Colorado Island forest in Panama was applied (50 ha) with resolutions between 10 and 100 m. The map was based on the forest inventory of 2010 (Condit et al., 2012), which included measurements of all trees with a stem diameter greater than 1 cm (Condit, 1998). The AGB per plot was determined using allometric relationships (see Supplements of Knapp et al., 2018, for details).
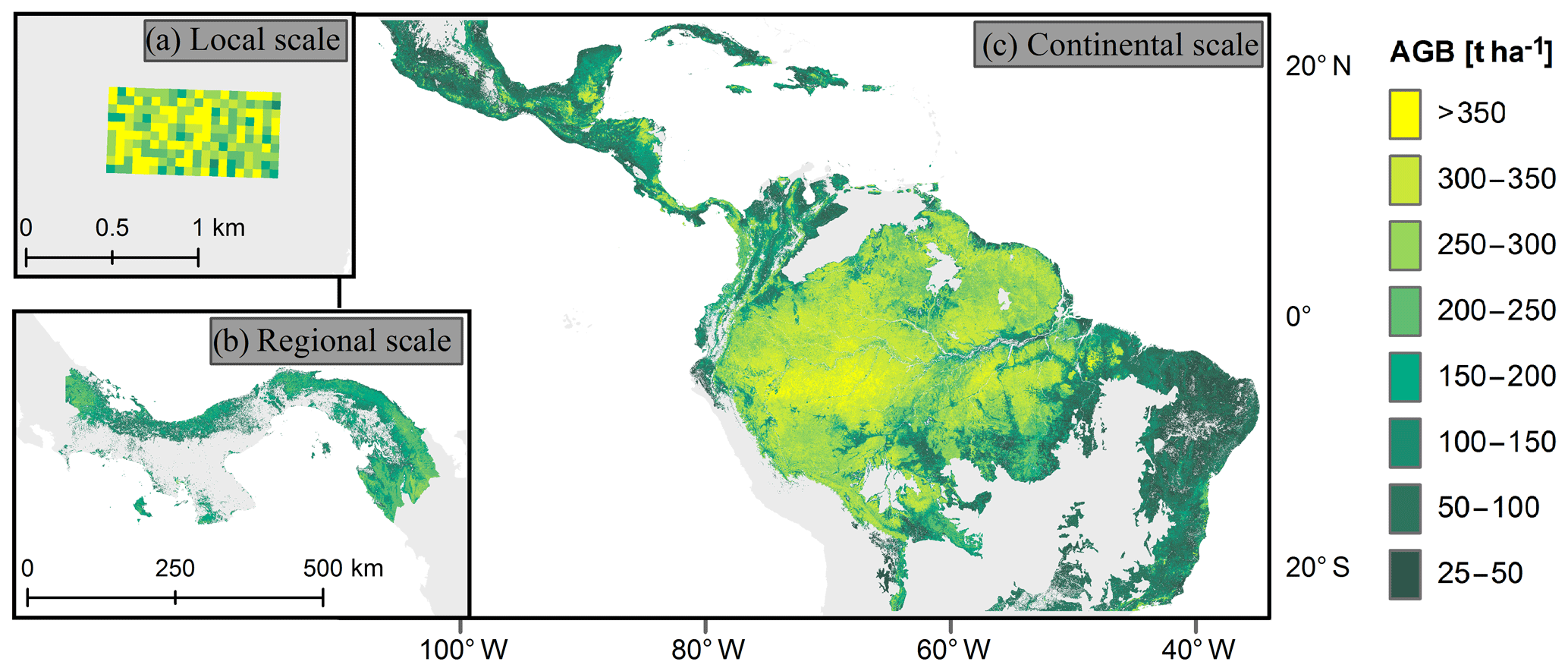
Figure 1Forest aboveground biomass (AGB) maps used for the study. (a) Biomass map of a forest plot on Barro Colorado Island (50 ha, 50 m resolution). (b) Biomass map for Panama (∼50 000 km2, 100 m resolution). (c) Biomass map for South America (∼11 × 106 km2, 500 m resolution). For this study, we excluded all areas covering grasslands, savannas, and shrublands.
Regional-scale analysis was carried out using a carbon density map of Panama that was derived from airborne light detection and ranging (lidar) measurements from 2012, in combination with field measurements and satellite measurements (Asner et al., 2013). The AGB values for this study were calculated by multiplying the carbon values by a factor of 2. We aggregated the AGB map from a 100 m resolution to resolutions of 200, 300, 400, and 500 m. When aggregated pixels covered a mixture of forest and non-forest areas, we assumed the non-forest areas to have a biomass of zero.
At the continental scale, we utilized a biomass map covering South America, Africa, and Southeast Asia with a spatial resolution of 500 m (Baccini et al., 2012). Biomass values of this map give information on the aboveground vegetative biomass in the time period from 2008 to 2010 and were derived using a combination of MODIS data, lidar measurements, and field data. For our analysis, we combined this biomass map with a biome map (Dinerstein et al., 2017) and excluded all areas that covered grasslands, savannas, and shrublands as well as areas with an aboveground biomass of less than 25 t ha−1. To that end, remaining areas were assigned to one of the following four tropical and subtropical forest biomes: (a) dry broadleaf forests, (b) moist broadleaf forests, (c) coniferous forests, and (d) mangroves.
Based on the continental forest biomass map of South America at 500 m resolution, we constructed an additional biomass map of South America with a 100 m resolution using two different downscaling approaches (for details, see Sect. S3 in the Supplement). The downscaling relationships were derived from the Panama map by upscaling this map from 100 to 500 m resolution.
2.2 Simulated sampling strategies
We investigated three different sampling strategies – (a) random sampling, (b) transect sampling, and (c) clustered sampling (Fig. 2) – with different sample sizes. For example, for analysis of the BCI forest, we divided the 50 ha biomass map into 200 square plots with a size of 50 m × 50 m (note that results could slightly differ for circular plots) (Lindsey et al., 1958). Then, we ran simulations with sample sets containing one sample (0.25 ha), two samples (0.50 ha), and so forth until we reached a sample size of 100 samples (25 ha, half of the study area). For large-scale investigations, we analyzed sample sizes of up to 5000 plots for Panama and 200 000 plots for South America.
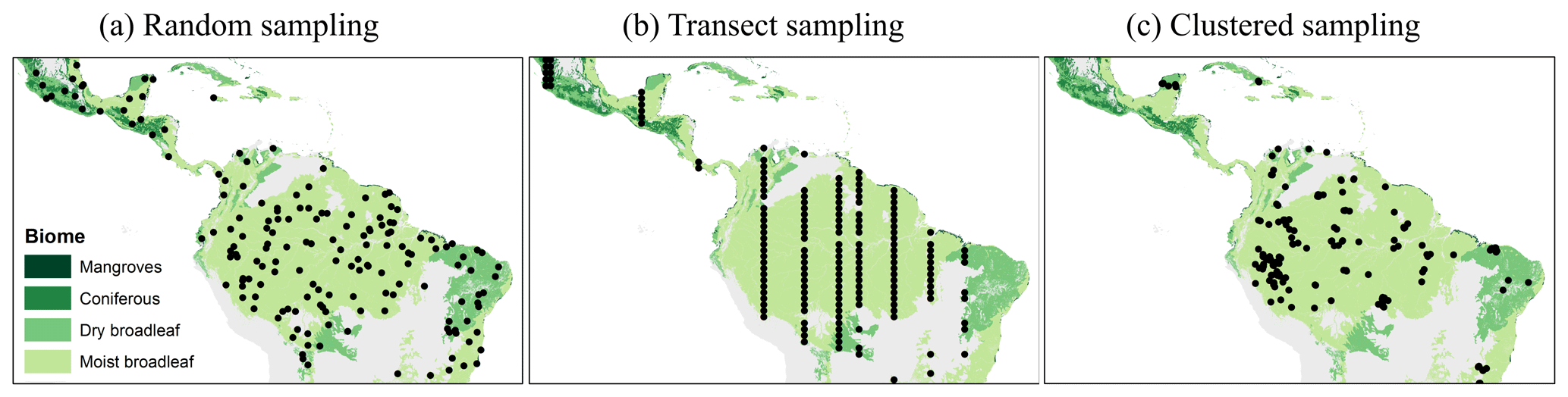
Figure 2Examples of different simulated sampling strategies for South America (colors indicate the tropical biome). Each black dot represents the location of one selected plot (25 ha). (a) Randomly distributed plots. (b) Transect samples (shown are strips with distances of 100 km between the plots). (c) Clustered samples (reconstructions of PP4).
2.2.1 Random sampling
Analysis of random sampling was performed using Monte Carlo simulations. For every map, we selected sampling plots at randomly selected positions (without replications) until the sample set reached the desired sample size. Random sampling is the only strategy where we can assume that the spatial autocorrelation of the map does not influence analytical analysis using the central limit theorem (Sect. S1).
2.2.2 Transect sampling
Transect sampling mimics sampling strategies used whenever plots should cover different gradients (e.g., climate or soil gradients). In this case, field inventory plots are established in a straight line. In our simulation approach, we assume for simplification north–south transects that start at a randomly selected position of the map. Within one transect, the plots have regular distances of 0.5, 1, or 5 km. Whenever the transect reaches the southern end of the map, a new randomly selected north–south transect is chosen starting at the northern border.
The analysis of Panama was conducted by selecting plots of 1 ha (map with 100 m resolution). For South America, we selected plots of 25 ha (map with 500 m resolution). To explore if the north–south climatic gradient influences the results, we also tested west–east instead of north–south tracks. However, the sampling performance remained similar (i.e., the probability of estimating the mean biomass accurately did not change considerably compared to north–south tracks).
2.2.3 Clustered sampling
The clustered sampling approach mimics the spatial clustering of real-world field inventory networks. To this end, we reconstructed the spatial pattern of the plot networks of four studies that estimated forest biomass – including Houghton et al. (2001), PP1; Poorter et al. (2015), PP2; Malhi et al. (2006), PP3; and Mitchard et al. (2014), PP4 – and analyzed them separately regarding the South American map with a resolution of 500 m (25 ha plot size). After removal of duplicate locations within the 500 m grid as well as plots that are located in grasslands, savannas, or shrublands (according to Dinerstein et al., 2017), the number of plots per network ranged between 23 and 167. To generate 1000 plot networks with spatial configurations similar to the original ones, we applied the method of pattern reconstruction (Wiegand et al., 2013; software “Pattern-Reconstruction”). This annealing method produces stochastic reconstructions of an observed point pattern that show the same spatial characteristics as the observed pattern, as quantified by several point pattern summary functions (for details see Sect. S2).
2.3 Determining the minimum sample size
For each map and each sample size, n, we calculated the sampling probability, Pn, which quantifies how often the mean of a sample equals the mean of the underlying “true” biomass distribution (under a given accuracy) as the relative frequency out of 1000 sample sets. For each sample set, the mean biomass ( in t ha−1) was estimated, where i is the sample set number, and n is the sample size. was then compared with the “true” mean biomass, μ [t ha−1], of the underlying biomass map. A sample set was assumed to be accurate if was within μ±10 %. The sampling performance can be assessed as follows:
Pn typically increases with the sample size from 0 (no sample could represent the mean biomass) to 1 (all samples could represent the biomass). We defined nmin as the minimum sample size, n, at which Pn reaches 90 %. The minimum sampling area, amin, is calculated by multiplying the number of plots, nmin, by the plot size.
3.1 Random sampling
3.1.1 Local scale (Barro Colorado Island)
The analysis of the 50 ha biomass map (BCI) shows the expected result that samples with larger plot sizes produce more accurate biomass estimates (Fig. 3a). For instance, a randomly chosen 0.01 ha plot has a probability (Pn) of 5 % of representing the mean biomass of the whole BCI forest, but if the plot has an area of 1 ha, Pn reaches 40 %. The size of the plots also affects the minimum number of plots required (nmin) for reliable biomass estimates (biomass estimates that have at least a 90 % chance of meeting the mean biomass of the original biomass map). For small plots (plot size ≤0.04 ha), nmin increases markedly (Fig. 3b). While only 11 one-hectare plots are needed to estimate the biomass, the number of plots increases to 176 if the plot size is 0.04 ha (20×20 m). However, the minimum total area of the samples (amin) remains similar (Table 1, BCI); i.e., it makes no difference in sample performance whether the samples are taken from 29 plots of 0.25 ha each or 746 plots of 0.01 ha each, as an area of about 7 ha is sampled in both scenarios. Therefore, the most efficient sampling strategy for the 50 ha scale would involve 0.25 ha plots, as greater plot sizes would result in a greater total sampling area (amin), and smaller plot sizes would simply increase the number of plots.
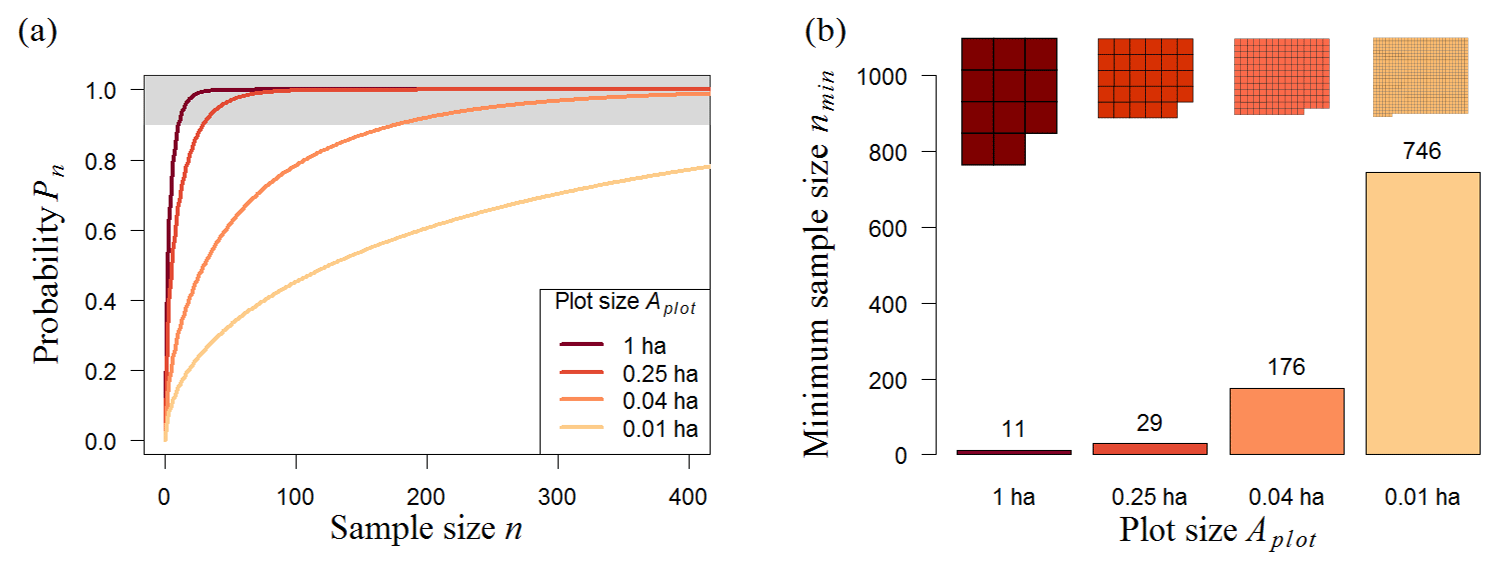
Figure 3Analysis of different random sampling strategies for the Barro Colorado Island forest (BCI, 50 ha). (a) Analytical results showing the number of plots and probability (Pn) that the mean biomass of those plots reflects the mean biomass of the forest (for details, see Methods). We consider strategies using 0.01–1 ha plots (plot size, represented by line colors). The upper boundary (grey) marks sample sizes with at least a 90 % chance of meeting the mean biomass of the original biomass map. (b) Necessary number of plots, nmin, to estimate the biomass reliably (minimum sample size from samples with Pn≥90 %). Shapes above the bars represent the necessary sampling area, .
Table 1Analyzed forest biomass maps and the corresponding minimum sample size. The forest biomass maps for South America (11 000 000 km2; Baccini et al., 2012; Dinerstein et al., 2017), Panama (50 000 km2; Asner et al., 2013), and Barro Colorado Island (50 ha; Condit et al., 2012) and their random sampling performance are shown. Different resolutions of the maps led to different results. The minimum sample size refers to the necessary number of plots to accurately estimate the observed mean biomass of the forest (the mean of the samples does not deviate more than 10 % from the observed mean biomass with a probability of at least 90 %). The last column shows the necessary sampling area, .

3.1.2 Regional scale (Panama)
Analyzing the biomass map of Panama (50 000 km2) by using plot sizes between 1 and 25 ha (Table 1, Panama), we found that the minimum sample size ranges between 70 and 74 plots. In contrast to the BCI analysis, plot size has no remarkable influence on the minimum sample size. However, the total sampling area (amin) increases from 70 to 1850 ha for different plot sizes. The most efficient sampling strategy at this scale is therefore to sample 70 plots of 1 ha each.
3.1.3 Continental scale (South America)
We found that the needed sampling number does not depend on the total forest area of biomes when samples are chosen randomly (Fig. 4). Mangrove forests (90 000 km2, requiring a sample of 100 plots) are the least abundant biome in South America but require a similar number of samples to dry broadleaf forest (2×106 km2, requiring a sample of 104 plots). Furthermore, the minimum sample size does not increase compared to the Panama analysis (Table 1); for example, plot number estimations for South America moist broadleaf forest (46 plots at 500 m resolution) are even 35 % less than for the Panama forest (74 plots at 500 m resolution, mainly consisting of moist broadleaf forest).

Figure 4Results of random sampling for different biomes of South America. (a) Analytical results showing the number of plots and probability (Pn) that the mean biomass of those plots reflects the mean biomass of the forest biome (for details, see Methods). The upper boundary (grey) marks sample sizes with at least a 90 % chance of meeting the mean biomass of the original biomass map. (b) Necessary number of 25 ha plots, nmin, to estimate the biomass for South America forest biomes reliably (minimum sample size from samples with Pn≥90 %; displayed above the bars).
For the whole of the South American tropical forest (11 × 106 km2), 74 plots of 25 ha are necessary to estimate the mean biomass with sufficient accuracy (Table 1, South America (500 m); for Africa and Southeast Asia, see Table S1 in the Supplement). This corresponds to a total sampling area (amin) of about 18.5 km2.
Using the downscaling approach D1 (see Sect. S3 for details), we found that about 70 one-hectare plots would be necessary to estimate the mean biomass of the South American tropical forest (Table 1, South America (100 m)). If we assume a much higher variation of biomass values than observed on the map (downscaling approach D2; see Sect. S3), this number can rise to 121 one-hectare plots.
3.2 Transect sampling
The performance of nonrandom strategies was related to the spatial characteristics of maps (Sect. S4, Fig. S3 in the Supplement). When the spatial clustering of the BCI forest biomass map is analyzed at the scale of 50 m, the obtained spatial biomass distribution is comparable to a random configuration; thus, the design of the sampling strategy has no influence on the results for this local forest area. For Panama and South America, the biomass is distributed in such a way that similar biomass values are more likely to be close to each other, which leads to biased estimation of the mean biomass if the samples are close to each other (e.g., transects with distances of 0.5 km between the plots). This results in differences between random sampling and transect sampling (Fig. 5a): compared to random sampling, transect samples show a lower probability (Pn) of estimating the mean biomass of the forest accurately independent of the sample size. For Panama, random samples based on 100 one-hectare plots exhibit a Pn=95 %, while transect samples are less than 60 % reliable (Fig. 5a).
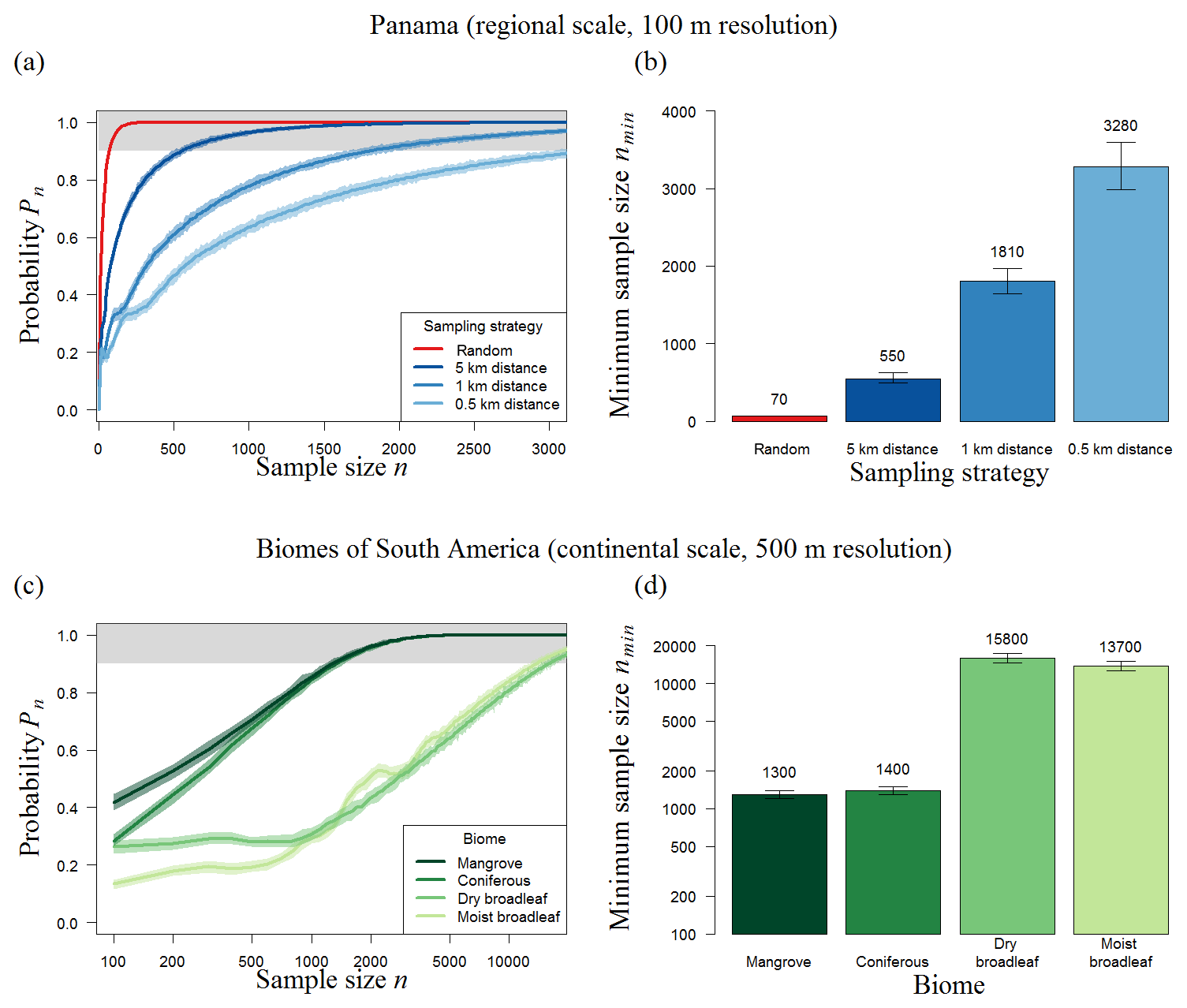
Figure 5Results of transect sampling for (a–b) Panama and (c–d) forest biomes in South America. (a, c) Simulation results showing the number of plots and probability (Pn) that the mean biomass of those plots reflects the mean biomass of the forest (for details, see Methods). (a) We focus on three strategies using distances of 500 m, 1 km, and 5 km between plots (shown in blue) and compare them to random sampling (red). (b) Results for different biomes of the American tropical forest using a distance of 1 km. The area around each line indicates the 95 % confidence intervals of 100 repetitions (total of 1000×100 runs for each sample size). The upper boundary (grey) marks sample sizes with at least a 90 % chance of meeting the mean biomass of the original biomass map. (b, d) Necessary number (nmin) of 1 ha plots for Panama and of 25 ha plots for biomes of South America (error bars show the 95 % confidence intervals of 100 repetitions).
The results show that, if the distances between the plots increase from 0.5 to 5 km, about 80 % fewer plots are necessary for accurate estimations. Larger distances between measurements within one transect make the strategy “more random”, and it therefore performs better. When distances of 5 km are used, Panama requires a total sampling area of 550 ha (instead of 70 ha with random sampling) to estimate the biomass of the 50 000 km2 forest with sufficient precision (Fig. 5b). In summary, even with large distances between plots, transect sampling leads to higher sampling efforts than random sampling.
For South America (11 × 106 km2), transect sampling based on 100 plots (25 ha plot size) shows a probability, Pn, of less than 40 % (Fig. S4). Using distances of 5 km, the minimum sampling size increases by a factor of 140 compared to random sampling (Fig. S4), leading to a total sample area of about 2500 km2.
Stratification into forest biomes does not lead to a marked reduction of the overall number of needed sample plots, since the sum of the plots needed for all single biomes (in total 32 200; Fig. 5d) is similar to plots needed for an overall forest sampling (36 000 plots; Fig. S5). However in contrast to the random sampling, the area size of each biome affects the sampling effort. Here, the large broadleaf biomes need about 10 times more transect samples than coniferous or mangrove forests.
3.3 Clustered sampling
Samples based on forest inventory plots are often influenced by accessibility, which leads to nonrandom locations of the sample plots that are simulated under the clustered sampling approach. Here, we examine the biomass map of South America with reconstructed point patterns PP1–PP4 based on the locations of existing inventories in South America (23–167 plots; see Methods). The results show that the probability (Pn) of estimating forest biomass accurately is considerably lower compared to the probability associated with random samples (Fig. 6). All samples present less than a 45 % chance of reflecting the real mean biomass for South America. For clustered sampling, a greater number of samples per se does not lead to better biomass estimations. The positions of the plots therefore play a crucial role. Although PP4 combines many plots of PP1 and PP3, the stochastic sampling scheme based on the spatial aggregation of plots cannot capture the biomass distribution substantially better than those based on the single datasets alone. In summary, the simulation results demonstrate that nonrandom strategies such as transect sampling and clustered sampling differ considerably from random sampling, leading to increased sampling efforts and noticeably greater sampling uncertainties.
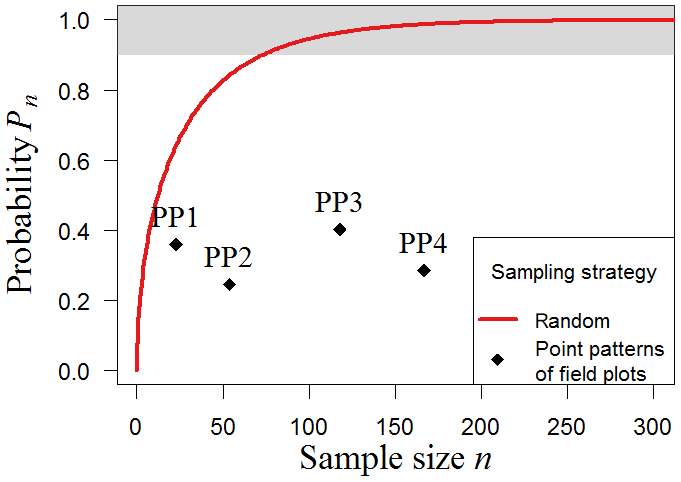
Figure 6Clustered sampling of biomass in South America. We tested different clustered sampling strategies using reconstructed point patterns based on the locations of existing field plots in South America (PP1–PP4). The simulation was performed with the South America map with a resolution of 500 m (25 ha plot size). Results show the probability (Pn) of accurate sampling for the spatial clustering of each point pattern (black crosses; ”accurate” means that the mean biomass of the sample does not deviate more than 10 % from the mean biomass of the original map). The upper boundary (grey) marks sample sizes with at least 90 % chance to estimate biomass accurately. As a reference, the results for random sampling are shown (red line).
Due to the large area of tropical forest, only a few parts of the forest can be investigated in detail. Therefore, effective sampling strategies for these forests are relevant (Broich et al., 2009; Chave et al., 2004; Malhi et al., 2006; Marvin et al., 2014). The question of how many forest plots are necessary to predict forest biomass has not yet been fully answered. Thus far, sampling quality has often been determined on the basis of the assumption that samples are spatially randomly distributed (Chave et al., 2004; Fisher et al., 2008; Keller et al., 2015; Marvin et al., 2014). However, sampling at large scales in the tropics often does not fulfill this condition because, in many cases, random locations are difficult to access (Wang et al., 2012). In this study, we compared different sampling strategies for tropical forests across various scales and plot sizes, examining the probability of obtaining the correct biomass estimate and the associated minimum sample size. Therefore, we analyzed random samples and compared them to simulated samples that are spatially clustered. Please note that in this study we did not consider additional error sources, for instance those due to tree size measurements or allometric models, even though they are also known to influence biomass estimates (Chave et al., 2004).
4.1 Random sampling
Focusing on forests in South America, we showed that, independent from forest area, fewer than 100 randomly distributed 1 ha plots are necessary to estimate the mean biomass with sufficient precision. This result is in line with a study by Marvin et al. (2014) predicting minimum sample sizes between 10 and 100 plots for forest regions in Peru (1–10 km2).
By testing plot sizes between 0.01 and 1 ha, we demonstrated that inventory plots should not be smaller than 0.25 ha because smaller plots tend to be considerably more heterogeneous (reflected by a large increase of the coefficient of variation (CV)) and lead to a noticeably greater number of necessary sample plots. Although the CV of the biomass distribution increases with decreasing plot size for local forests (Réjou-Méchain et al., 2014; Wagner et al., 2010), there seem to be only small effects for larger landscapes. For Panama, we even found that biomass distributions of the aggregated maps were more heterogeneous due to averaging forest with non-forest areas. To estimate the minimum sample size of a particular forest region, it might be useful to explore biomass variability, for example, by using forest models (Zurell et al., 2010) or topography (Réjou-Méchain et al., 2014).
For large areas (tropical forests in South America, Africa, and Southeast Asia), we obtained minimum sample sizes of 74–103 plots (randomly distributed, 25 ha each) on each continent. We also tested larger plot sizes with a biomass map from Saatchi et al. (2011), but the results were similar (75–136 plots, 100 ha each). Furthermore, we also tested smaller plot sizes by downscaling the South American biomass map to 100 m using relationships derived from the Panama forest biomass map (50 000 km2 forest area). The analysis indicated that 70 plots of 1 ha that are randomly distributed in space are sufficient for biomass estimations in South America at large scales (Table 1).
Some remote-sensing-based biomass maps can miss empirically measured biomass patterns in tropical forests (Mitchard et al., 2014). Biomass maps might not meet the high variability of biomass in forests because they do not include fine-scale variation (Mitchard et al., 2014) and saturate at high biomass values (Lu, 2006; Sellers, 1985). We addressed this issue of missing fine-scale variation by constructing an additional biomass map at 100 m resolution with much higher variation in biomass values than observed in the biomass map used. In this case, the number of 1 ha plots that are necessary for continental estimates of the South American tropical forest increased to 121 one-hectare plots (instead of 70 plots). Please note that we tested a simple downscaling procedure, so caution must be applied to these initial findings. In summary, we found that a higher variation in biomass values leads to a higher sampling effort (see Fig. S1).
4.2 Nonrandom sampling
Our analysis showed that sampling efforts change considerably if samples are not random in space. For South America, nonrandom samples of forests are less reliable and require substantially more plots to achieve accurate biomass estimations. This means that the necessary number of plots for nonrandom sampling strategies (as can be found in real-world inventories) cannot be assessed by Monte Carlo simulations that implicitly assume that samples are random (as in related studies, e.g., Chave et al., 2004; Fisher et al., 2008; Keller et al., 2015; Marvin et al., 2014). Instead simulation procedures need to incorporate more advanced methods that include aggregated plot placement.
We demonstrated that a spatial autocorrelation has an effect on the sampling strategy (Legendre and Fortin, 1989; Réjou-Méchain et al., 2014) if plots close to each other are more similar than plots located farther apart (positive autocorrelation). Result suggest that for larger regions biomass tends to be more spatially clustered (e.g., large forest biomass occurs more frequently within the Amazon basin than in the surrounding landscape) because biomass varies due to environmental gradients and geographical reasons (Houghton et al., 2009). Therefore, the uncertainty of large-scale estimations might be more affected by the sampling design than estimates for local scales. However, small forested regions can also be spatially correlated in terms of biomass (e.g., due to management or topography), so biases cannot be excluded whenever the sampling design is not random.
The sampling performance of current plot networks is related to an interplay of clustering and scattering of the inventory plots in certain areas. For instance, if inventory plots are more likely to be located in densely overgrown mature forests, the biomass is overrated because the rest of the plots cannot compensate for this bias (“majestic forest bias”; Malhi et al., 2002). We see a high potential in point pattern analysis to determine critical levels of aggregation that can bias sampling estimation. Current plot networks might improve their sampling performance by combining subsamples of aggregated plot clusters while including additional plots in poorly sampled regions.
Existing plot networks may provide better estimates than suggested by “blind” sampling using additional information (e.g., climate and soil covariates). Those covariates can be utilized, for example, to define weighting factors that enhance biomass mean estimation. To analyze this issue, the pattern reconstruction approach used in this study could include additional criteria (ideally also those used for selection of plots). If the covariates can be mapped in the entire study area, the pattern reconstruction approach can take into account the additional constraints and reject plot configurations that do not agree with these criteria.
In summary, our study shows that the accuracy of the biomass estimates derived from samples depends considerably on the sampling strategy. Inventories are highly relevant for studying forest structure and dynamics. For South America, we have shown that more spatially randomly distributed plots are beneficial for continent-wide biomass estimations. For a given sampled area, plot size should not fall below 0.25 ha, as the variability of biomass values will strongly increase (Chave et al., 2003; Clark et al., 2001; Keller et al., 2015; Réjou-Méchain et al., 2014), and tree-level measurement errors can dominate (Chave et al., 2004).
It is challenging to establish forest plots randomly across South America. On the one hand, mature tropical forests have high tree densities (Crowther et al., 2015), so measurements are more labor intensive. On the other hand, random plot locations may lead to large distances between the plots (Wang et al., 2012), making them more difficult to access and also resulting in higher efforts and costs.
Some studies combine field inventories with remote sensing data to estimate the biomass of large regions (Asner et al., 2013; Baccini et al., 2012; Rödig et al., 2017; Saatchi et al., 2011) as remote sensing can sample forest regions in a short time (Houghton et al., 2009; Schimel et al., 2015). The transect sampling shown here could also give hints for remote-sensing-based airplane campaigns flying in straight lines over forest transects (e.g., comparable to Asner et al., 2013). The methods presented can be applied to any spatially clustered sampling technique. The sampling design is very relevant not only for forest biomass estimations but also in view of other forest attributes (e.g., production). This should be considered when establishing forest plot networks.
Biomass data of BCI (Condit et al., 2012), Panama (Asner et al., 2013), and the tropics (Baccini et al., 2012) are available in the corresponding references. The R code for sampling simulations is available upon request from the corresponding author.
The supplement related to this article is available online at: https://doi.org/10.5194/bg-17-1673-2020-supplement.
JH, RF, and AH conceptualized the research; JH prepared the data and ran analyses. TW supported point pattern analysis. HJD contributed to analytical solutions. JH, RF, and AH prepared the first draft of the paper, and all the co-authors contributed substantially to subsequent versions, including the final draft.
The authors declare that they have no conflict of interest.
We thank Greg Asner for providing the biomass data for Panama and Sassan Saatchi and Alessandro Baccini for providing biomass values for the tropics. We thank Volker Grimm for his helpful comments on a draft of this paper and Franziska Taubert for her support.
The article processing charges for this open-access publication were covered by a Research Centre of the Helmholtz Association.
This paper was edited by Paul Stoy and reviewed by three anonymous referees.
Anderson, L. O., Malhi, Y., Ladle, R. J., Aragão, L. E. O. C., Shimabukuro, Y., Phillips, O. L., Baker, T., Costa, A. C. L., Espejo, J. S., Higuchi, N., Laurance, W. F., López-González, G., Monteagudo, A., Núñez-Vargas, P., Peacock, J., Quesada, C. A., and Almeida, S.: Influence of landscape heterogeneity on spatial patterns of wood productivity, wood specific density and above ground biomass in Amazonia, Biogeosciences, 6, 1883–1902, https://doi.org/10.5194/bg-6-1883-2009, 2009.
Asner, G. P., Mascaro, J., Anderson, C., Knapp, D. E., Martin, R. E., Kennedy-Bowdoin, T., van Breugel, M., Davies, S., Hall, J. S., Muller-Landau, H. C., Potvin, C., Sousa, W., Wright, J., and Bermingham, E.: High-fidelity national carbon mapping for resource management and REDD+, Carbon Balance Manag., 8, 1, https://doi.org/10.1186/1750-0680-8-7, 2013.
Avitabile, V., Herold, M., Heuvelink, G. B. M., Lewis, S. L., Phillips, O. L., Asner, G. P., Armston, J., Ashton, P. S., Banin, L., Bayol, N., Berry, N. J., Boeckx, P., de Jong, B. H. J., Devries, B., Girardin, C. A. J., Kearsley, E., Lindsell, J. A., Lopez-Gonzalez, G., Lucas, R., Malhi, Y., Morel, A., Mitchard, E. T. A., Nagy, L., Qie, L., Quinones, M. J., Ryan, C. M., Ferry, S. J. W., Sunderland, T., Laurin, G. V., Gatti, R. C., Valentini, R., Verbeeck, H., Wijaya, A., and Willcock, S.: An integrated pan-tropical biomass map using multiple reference datasets, Glob. Change Biol., 22, 1406–1420, https://doi.org/10.1111/gcb.13139, 2016.
Baccini, A., Goetz, S. J., Walker, W. S., Laporte, N. T., Sun, M., Sulla-Menashe, D., Hackler, J., Beck, P. S. A., Dubayah, R., Friedl, M. A., Samanta, S., and Houghton, R. A.: Estimated carbon dioxide emissions from tropical deforestation improved by carbon-density maps, Nat. Clim. Change, 2, 182–185, https://doi.org/10.1038/nclimate1354, 2012.
Broich, M., Stehman, S. V., Hansen, M. C., Potapov, P., and Shimabukuro, Y. E.: A comparison of sampling designs for estimating deforestation from Landsat imagery: A case study of the Brazilian Legal Amazon, Remote Sens. Environ., 113, 2448–2454, https://doi.org/10.1016/j.rse.2009.07.011, 2009.
Chave, J., Condit, R., Lao, S., Caspersen, J. P., Foster, R. B., and Hubbell, S. P.: Spatial and temporal variation of biomass in a tropical forest?: results from a large census plot in Panama, J. Ecol., 91, 240–252, https://doi.org/10.1007/bf03403873, 2003.
Chave, J., Condit, R., Aguilar, S., Hernandez, A., Lao, S., and Perez, R.: Error propagation and scaling for tropical forest biomass estimates, Philos. T. R. Soc. B, 359, 409–420, https://doi.org/10.1098/rstb.2003.1425, 2004.
Clark, D. A., Brown, S., Kicklighter, D. W., Chambers, J. Q., Thomlinson, J. R., Ni, J., and Holland, E. A.: Net Primary Productivity in Tropical Forests: An evaluation and Synthesis of Existing Field Data, Ecol. Appl., 11, 371–384, https://doi.org/10.2307/3060895, 2001.
Clark, D. B. and Kellner, J. R.: Tropical forest biomass estimation and the fallacy of misplaced concreteness, J. Veg. Sci., 23, 1191–1196, https://doi.org/10.1111/j.1654-1103.2012.01471.x, 2012.
Condit, R.: Tropical forest census plots: methods and results from Barro colorado Island, Panama and a comparison with other Plots, Springer, Berlin Heidelberg, 1998.
Condit, R., Lao, S., Pérez, R., Dolins, S. B., Foster, R., and Hubbell, S.: Barro Colorado Forest Census Plot Data, Version 2012, https://doi.org/10.5479/data.bci.20130603, 2012.
Crowther, T. W., Glick, H. B., Covey, K. R., Bettigole, C., Maynard, D. S., Thomas, S. M., Smith, J. R., Hintler, G., Duguid, M. C., Amatulli, G., Tuanmu, M. N., Jetz, W., Salas, C., Stam, C., Piotto, D., Tavani, R., Green, S., Bruce, G., Williams, S. J., Wiser, S. K., Huber, M. O., Hengeveld, G. M., Nabuurs, G. J., Tikhonova, E., Borchardt, P., Li, C. F., Powrie, L. W., Fischer, M., Hemp, A., Homeier, J., Cho, P., Vibrans, A. C., Umunay, P. M., Piao, S. L., Rowe, C. W., Ashton, M. S., Crane, P. R., and Bradford, M. A.: Mapping tree density at a global scale, Nature, 525, 201–205, https://doi.org/10.1038/nature14967, 2015.
Dinerstein, E., Olson, D., Joshi, A., Vynne, C., Burgess, N. D., Wikramanayake, E., Hahn, N., Palminteri, S., Hedao, P., Noss, R., Hansen, M., Locke, H., Ellis, E. C., Jones, B., Barber, C. V., Hayes, R., Kormos, C., Martin, V., Crist, E., Sechrest, W. E. S., Price, L., Baillie, J. E. M., Weeden, D. O. N., Suckling, K., Davis, C., Sizer, N., Moore, R., Thau, D., Birch, T., Potapov, P., Turubanova, S., Tyukavina, A., Souza, N. D. E., Pintea, L., Brito, J. C., Llewellyn, O. A., Miller, A. G., Patzelt, A., Ghazanfar, S. A., Timberlake, J., Klöser, H., Shennan-farpón, Y., and Kindt, R.: An Ecoregion-Based Approach to Protecting Half the Terrestrial Realm, Bioscience, 67, 534–545 https://doi.org/10.1093/biosci/bix014, 2017.
Fisher, J. I., Hurtt, G. C., Thomas, R. Q., and Chambers, J. Q.: Clustered disturbances lead to bias in large-scale estimates based on forest sample plots, Ecol. Lett., 11, 554–563, https://doi.org/10.1111/j.1461-0248.2008.01169.x, 2008.
Houghton, R. A., Lawrence, K. T., Hackler, J. L., and Brown, S.: The spatial distribution of forest biomass in the Brazilian Amazon: a comparison of estimates, Glob. Change Biol., 7, 731–746, https://doi.org/10.1111/j.1365-2486.2001.00426.x, 2001.
Houghton, R. A., Hall, F., and Goetz, S. J.: Importance of biomass in the global carbon cycle, J. Geophys. Res.-Biogeo., 114, 1–13, https://doi.org/10.1029/2009JG000935, 2009.
Keller, M., Palace, M., and Hurtt, G.: Biomass estimation in the Tapajos National Forest, Brazil examination of sampling and allometric uncertainties, Forest Ecol. Manag., 154, 371–382, https://doi.org/10.1016/S0378-1127(01)00509-6, 2015.
Knapp, N., Fischer, R., and Huth, A.: Linking lidar and forest modeling to assess biomass estimation across scales and disturbance states, Remote Sens. Environ., 205, 199–209, https://doi.org/10.1016/j.rse.2017.11.018, 2018.
Legendre, P. and Fortin, M. J.: Spatial pattern and ecological analysis, Vegetatio, 80, 107–138, https://doi.org/10.1007/BF00048036, 1989.
Lewis, S. L., Phillips, O. L., Baker, T. R., Lloyd, J., Malhi, Y., Almeida, S., Higuchi, N., Laurance, W. F., Neill, D. a, Silva, J. N. M., Terborgh, J., Lezama, a T., Martinez, R. V, Brown, S., Chave, J., Kuebler, C., Vargas, P. N., and Vinceti, B.: Concerted changes in tropical forest structure and dynamics: evidence from 50 South American long-term plots, Philos. T. R. Soc. B, 359, 421–436, https://doi.org/10.1098/rstb.2003.1431, 2004.
Lindsey, A. A., Barton Jr., J. D., and Miles, S. R.: Field Efficiencies of Forest Sampling Methods, Ecology, 39, 428–444, 1958.
Lopez-Gonzalez, G., Mitchard, E. T. A., Feldpausch, T. R., Brienen, R. J. W., Monteagudo, A., Baker, T. R., Lewis, S. L., Lloyd, J., Quesada, C. A., Gloor, E., ter Steege, H., Meir, P., Alvarez, E., Araujo-Murakami, A., Aragão, L. E. O. C., Arroyo, L., Aymard, G., Banki, O., Bonal, D., Brown, S., Brown, F. I., Cerón, C. E., Chama Moscoso, V., Chave, J., Comiskey, J. M., Cornejo, F., Corrales Medina, M., Da Costa, L., Costa, F. R. C., Di Fiore, A., Domingues, T., Erwin, T. L., Fredericksen, T., Higuchi, N., Honorio Coronado, E. N., Killeen, T. J., Laurance, W. F., Levis, C., Magnusson, W. E., Marimon, B. S., Marimon-Junior, B. H., Mendoza Polo, I., Mishra, P., Nascimento, M., Neill, D., Nunez Vargas, M. P., Palacios, W. A., Parada-Gutierrez, A., Pardo Molina, G., Peña-Claros, M., Pitman, N., Peres, C. A., Poorter, L., Prieto, A., Ramírez-Angulo, H., Restrepo Correa, Z., Roopsind, A., Roucoux, K. H., Rudas, A., Salomao, R. P., Schietti, J., Silveira, M., De Souza, P. F., Steiniger, M., Stropp, J., Terborgh, J., Thomas, R. P., Toledo, M., Torres-Lezama, A., Van Andel, T. R., van der Heijden, G. M. F., Vieira, I. C. G., Vieira, S., Vilanova-Torre, E., Vos, V. A., Wang, O., Zartman, C. E., de Oliveira, E. A., Morandi, P. S., Malhi, Y., and Phillips, O. L.: Amazon forest biomass measured in inventory plots. Plot Data from “Markedly divergent estimates of Amazon forest carbon density from ground plots and satellites”, ForestPlots.NET, https://doi.org/10.5521/FORESTPLOTS.NET/2014_1, 2014.
Lu, D.: The potential and challenge of remote sensing-based biomass estimation, Int. J. Remote Sens., 27, 1297–1328, https://doi.org/10.1080/01431160500486732, 2006.
Malhi, Y., Phillips, O. L., Lloyd, J., Baker, T., Wright, J., Almeida, S., Arroyo, L., Frederiksen, T., Grace, J., Higuchi, N., Killeen, T., Laurance, W. F., Leano, C., Lewis, S., Meir, P., Monteagudo, A., Neill, D., Nunez Vargas, P., Panfil, S. N., Patino, S., Pitman, N., Quesada, C. a., Rudas-Ll, A., Salomao, R., Saleska, S., Silva, N., Silveira, M., Sombroek, W. G., Valencia, R., Vasquez Martinez, R., Vieira, I. C. G., and Vinceti, B.: An international network to monitor the structure, composition and dynamics of Amazonian forests (RAINFOR), J. Veg. Sci., 13, 439–450, https://doi.org/10.1111/j.1654-1103.2002.tb02068.x, 2002.
Malhi, Y., Wood, D., Baker, T. R., Wright, J., Phillips, O. L., Cochrane, T., Meir, P., Chave, J., Almeida, S., Arroyo, L., Higuchi, N., Killeen, T. J., Laurance, S. G., Laurance, W. F., Lewis, S. L., Monteagudo, A., Neill, D. A., Vargas, P. N., Pitman, N. C. A., Quesada, C. A., Salomão, R., Silva, J. N. M., Lezama, A. T., Terborgh, J., Martínez, R. V., and Vinceti, B.: The regional variation of aboveground live biomass in old-growth Amazonian forests, Glob. Change Biol., 12, 1107–1138, https://doi.org/10.1111/j.1365-2486.2006.01120.x, 2006.
Marvin, D. C., Asner, G. P., Knapp, D. E., Anderson, C. B., Martin, R. E., Sinca, F., and Tupayachi, R.: Amazonian landscapes and the bias in field studies of forest structure and biomass, P. Natl. Acad. Sci. USA, 111, E5224–E5232, https://doi.org/10.1073/pnas.1412999111, 2014.
Mitchard, E. T. A., Feldpausch, T. R., Brienen, R. J. W., Lopez-Gonzalez, G., Monteagudo, A., Baker, T. R., Lewis, S. L., Lloyd, J., Quesada, C. A., Gloor, M., Steege, H., Meir, P., Alvarez, E., Araujo-Murakami, A., Aragão, L. E. O. C., Arroyo, L., Aymard, G., Banki, O., Bonal, D., Brown, S., Brown, F. I., Cerón, C. E., Moscoso, V. C., Chave, J., Comiskey, J. A., Cornejo, F., Medina, M. C., Costa, L. Da, Costa, F. R. C., Fiore, A. Di, Domingues, T. F., Erwin, T. L., Frederickson, T., Higuchi, N., Coronado, E. N. H., Killeen, T. J., Laurance, W. F., Levis, C., Magnusson, W. E., Marimon, B. S., Junior, B. H. M., Polo, I. M., Mishra, P., Nascimento, M. T., Neill, D., Vargas, M. P. N., Palacios, W. A., Parada, A., Molina, G. P., Peña-Claros, M., Pitman, N., Peres, C. A., Poorter, L., Prieto, A., Ramirez-Angulo, H., Correa, Z. R., Roopsind, A., Roucoux, K. H., Rudas, A., Salomão, R. P., Schietti, J., Silveira, M., Souza, P. F., Steininger, M. K., Stropp, J., Terborgh, J., Thomas, R., Toledo, M., Torres-Lezama, A., Andel, T. R., Heijden, G. M. F., Vieira, I. C. G., Vieira, S., Vilanova-Torre, E., Vos, V. A., Wang, O., Zartman, C. E., Malhi, Y., and Phillips, O. L.: Markedly divergent estimates of Amazon forest carbon density from ground plots and satellites, Global Ecol. Biogeogr., 23, 935–946, https://doi.org/10.1111/geb.12168, 2014.
Pan, Y., Birdsey, R. A., Fang, J., Houghton, R., Kauppi, P. E., Kurz, W. A., Phillips, O. L., Shvidenko, A., Lewis, S. L., Canadell, J. G., Ciais, P., Jackson, R. B., Pacala, S. W., McGuire, A. D., Piao, S., Rautiainen, A., Sitch, S., and Hayes, D.: A Large and Persistent Carbon Sink in the World's Forests, Science, 333, 988–993, https://doi.org/10.1126/science.1201609, 2011.
Poorter, L., van der Sande, M. T., Thompson, J., Arets, E. J. M. M., Alarcón, A., Álvarez-Sánchez, J., Ascarrunz, N., Balvanera, P., Barajas-Guzmán, G., Boit, A., Bongers, F., Carvalho, F. A., Casanoves, F., Cornejo-Tenorio, G., Costa, F. R. C., de Castilho, C. V., Duivenvoorden, J. F., Dutrieux, L. P., Enquist, B. J., Fernández-Méndez, F., Finegan, B., Gormley, L. H. L., Healey, J. R., Hoosbeek, M. R., Ibarra-Manríquez, G., Junqueira, A. B., Levis, C., Licona, J. C., Lisboa, L. S., Magnusson, W. E., Martínez-Ramos, M., Martínez-Yrizar, A., Martorano, L. G., Maskell, L. C., Mazzei, L., Meave, J. A., Mora, F., Muñoz, R., Nytch, C., Pansonato, M. P., Parr, T. W., Paz, H., Pérez-García, E. A., Rentería, L. Y., Rodríguez-Velazquez, J., Rozendaal, D. M. A., Ruschel, A. R., Sakschewski, B., Salgado-Negret, B., Schietti, J., Simões, M., Sinclair, F. L., Souza, P. F., Souza, F. C., Stropp, J., ter Steege, H., Swenson, N. G., Thonicke, K., Toledo, M., Uriarte, M., van der Hout, P., Walker, P., Zamora, N., and Peña-Claros, M.: Diversity enhances carbon storage in tropical forests, Global Ecol. Biogeogr., 24, 1314–1328, https://doi.org/10.1111/geb.12364, 2015.
Réjou-Méchain, M., Muller-Landau, H. C., Detto, M., Thomas, S. C., Le Toan, T., Saatchi, S. S., Barreto-Silva, J. S., Bourg, N. A., Bunyavejchewin, S., Butt, N., Brockelman, W. Y., Cao, M., Cárdenas, D., Chiang, J.-M., Chuyong, G. B., Clay, K., Condit, R., Dattaraja, H. S., Davies, S. J., Duque, A., Esufali, S., Ewango, C., Fernando, R. H. S., Fletcher, C. D., Gunatilleke, I. A. U. N., Hao, Z., Harms, K. E., Hart, T. B., Hérault, B., Howe, R. W., Hubbell, S. P., Johnson, D. J., Kenfack, D., Larson, A. J., Lin, L., Lin, Y., Lutz, J. A., Makana, J.-R., Malhi, Y., Marthews, T. R., McEwan, R. W., McMahon, S. M., McShea, W. J., Muscarella, R., Nathalang, A., Noor, N. S. M., Nytch, C. J., Oliveira, A. A., Phillips, R. P., Pongpattananurak, N., Punchi-Manage, R., Salim, R., Schurman, J., Sukumar, R., Suresh, H. S., Suwanvecho, U., Thomas, D. W., Thompson, J., Uríarte, M., Valencia, R., Vicentini, A., Wolf, A. T., Yap, S., Yuan, Z., Zartman, C. E., Zimmerman, J. K., and Chave, J.: Local spatial structure of forest biomass and its consequences for remote sensing of carbon stocks, Biogeosciences, 11, 6827–6840, https://doi.org/10.5194/bg-11-6827-2014, 2014.
Rödig, E., Cuntz, M., Heinke, J., Rammig, A., and Huth, A.: Spatial heterogeneity of biomass and forest structure of the Amazon rain forest: Linking remote sensing, forest modelling and field inventory, Global Ecol. Biogeogr., 26, 1292–1302, https://doi.org/10.1111/geb.12639, 2017.
Saatchi, S. S., Harris, N. L., Brown, S., Lefsky, M., Mitchard, E. T. A., Salas, W., Zutta, B. R., Buermann, W., Lewis, S. L., Hagen, S., Petrova, S., White, L., Silman, M., and Morel, A.: Benchmark map of forest carbon stocks in tropical regions across three continents, P. Natl. Acad. Sci. USA, 108, 9899–9904, https://doi.org/10.1073/pnas.1019576108, 2011.
Saatchi, S., Mascaro, J., Xu, L., Keller, M., Yang, Y., Duffy, P., Espírito-Santo, F., Baccini, A., Chambers, J., and Schimel, D.: Seeing the forest beyond the trees, Global Ecol. Biogeogr., 24, 606–610, https://doi.org/10.1111/geb.12256, 2015.
Schimel, D., Pavlick, R., Fisher, J. B., Asner, G. P., Saatchi, S., Townsend, P., Miller, C., Frankenberg, C., Hibbard, K., and Cox, P.: Observing terrestrial ecosystems and the carbon cycle from space, Glob. Change Biol., 21, 1762–1776, https://doi.org/10.1111/gcb.12822, 2015.
Sellers, P. J.: Canopy reflectance, photosynthesis and transpiration, Int. J. Remote Sens., 6, 1335–1372, https://doi.org/10.1080/01431168508948283, 1985.
Smith, W. B.: Forest inventory and analysis: A national inventory and monitoring program, Environ. Pollut., 116, 233–242, https://doi.org/10.1016/S0269-7491(01)00255-X, 2002.
Wagner, F., Rutishauser, E., Blanc, L., and Herault, B.: Effects of plot size and census interval on descriptors of forest structure and dynamics, Biotropica, 42, 664–671, https://doi.org/10.1111/j.1744-7429.2010.00644.x, 2010.
Wang, J. F., Stein, A., Gao, B. B., and Ge, Y.: A review of spatial sampling, Spat. Stat., 2, 1–14, https://doi.org/10.1016/j.spasta.2012.08.001, 2012.
Wiegand, T., He, F., and Hubbell, S. P.: A systematic comparison of summary characteristics for quantifying point patterns in ecology, Ecography, 36, 92–103, https://doi.org/10.1111/j.1600-0587.2012.07361.x, 2013.
Zurell, D., Berger, U., Cabral, J. S., Jeltsch, F., Meynard, C. N., Münkemüller, T., Nehrbass, N., Pagel, J., Reineking, B., Schröder, B., and Grimm, V.: The virtual ecologist approach: Simulating data and observers, Oikos, 119, 622–635, https://doi.org/10.1111/j.1600-0706.2009.18284.x, 2010.